 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVI-HT: Adaptive Vision-IMU Fusion for 3D Hand Tracking
May 20, 2026We present AVI-HT, an adaptive visual-IMU fusion approach for tracking 3D hand poses by jointly modeling the egocentric image with on-glove 6-DoF IMU signals. AVI-HT achieves significantly improved accuracy and availability, particularly in hand-object interaction (HOI) scenarios involving heavy visual occlusion. Two complementary ingredients underpin its success: (1) synchronized multi-modal training data pairing on-body vision-IMU sensor streams with ground-truth 3D hand poses from a motion-capture system, and (2) a cross-sensor deep attention mechanism that adaptively modulates the trust assigned to the vision and individual IMU sensors. To evaluate AVI-HT in real-world settings, we conduct extensive experiments on our DexGloveHOI dataset that consists of 100K+ pairwise vision-IMU samples with synchronized 3D annotated poses, in which users manipulate a variety of objects during daily tasks. We compare against multiple single- and multi-modal tracking approaches under two hand models (UmeTrack, MANO). The results show that AVI-HT reduces mean keypoint error by 16.1% and its wrist-aligned variant by 24.2% over the baselines. Ablation studies further reveal the per-finger contribution of IMU sensors across activity types, and the model's sensitivity to IMU noise and temporal misalignment in vision-IMU fusion.
Glove2Hand: Synthesizing Natural Hand-Object Interaction from Multi-Modal Sensing Gloves
Mar 21, 2026Understanding hand-object interaction (HOI) is fundamental to computer vision, robotics, and AR/VR. However, conventional hand videos often lack essential physical information such as contact forces and motion signals, and are prone to frequent occlusions. To address the challenges, we present Glove2Hand, a framework that translates multi-modal sensing glove HOI videos into photorealistic bare hands, while faithfully preserving the underlying physical interaction dynamics. We introduce a novel 3D Gaussian hand model that ensures temporal rendering consistency. The rendered hand is seamlessly integrated into the scene using a diffusion-based hand restorer, which effectively handles complex hand-object interactions and non-rigid deformations. Leveraging Glove2Hand, we create HandSense, the first multi-modal HOI dataset featuring glove-to-hand videos with synchronized tactile and IMU signals. We demonstrate that HandSense significantly enhances downstream bare-hand applications, including video-based contact estimation and hand tracking under severe occlusion.
AirGlove: Exploring Egocentric 3D Hand Tracking and Appearance Generalization for Sensing Gloves
Feb 05, 2026Sensing gloves have become important tools for teleoperation and robotic policy learning as they are able to provide rich signals like speed, acceleration and tactile feedback. A common approach to track gloved hands is to directly use the sensor signals (e.g., angular velocity, gravity orientation) to estimate 3D hand poses. However, sensor-based tracking can be restrictive in practice as the accuracy is often impacted by sensor signal and calibration quality. Recent advances in vision-based approaches have achieved strong performance on human hands via large-scale pre-training, but their performance on gloved hands with distinct visual appearances remains underexplored. In this work, we present the first systematic evaluation of vision-based hand tracking models on gloved hands under both zero-shot and fine-tuning setups. Our analysis shows that existing bare-hand models suffer from substantial performance degradation on sensing gloves due to large appearance gap between bare-hand and glove designs. We therefore propose AirGlove, which leverages existing gloves to generalize the learned glove representations towards new gloves with limited data. Experiments with multiple sensing gloves show that AirGlove effectively generalizes the hand pose models to new glove designs and achieves a significant performance boost over the compared schemes.
Glissando-Net: Deep sinGLe vIew category level poSe eStimation ANd 3D recOnstruction
Jan 24, 2025



We present a deep learning model, dubbed Glissando-Net, to simultaneously estimate the pose and reconstruct the 3D shape of objects at the category level from a single RGB image. Previous works predominantly focused on either estimating poses(often at the instance level), or reconstructing shapes, but not both. Glissando-Net is composed of two auto-encoders that are jointly trained, one for RGB images and the other for point clouds. We embrace two key design choices in Glissando-Net to achieve a more accurate prediction of the 3D shape and pose of the object given a single RGB image as input. First, we augment the feature maps of the point cloud encoder and decoder with transformed feature maps from the image decoder, enabling effective 2D-3D interaction in both training and prediction. Second, we predict both the 3D shape and pose of the object in the decoder stage. This way, we better utilize the information in the 3D point clouds presented only in the training stage to train the network for more accurate prediction. We jointly train the two encoder-decoders for RGB and point cloud data to learn how to pass latent features to the point cloud decoder during inference. In testing, the encoder of the 3D point cloud is discarded. The design of Glissando-Net is inspired by codeSLAM. Unlike codeSLAM, which targets 3D reconstruction of scenes, we focus on pose estimation and shape reconstruction of objects, and directly predict the object pose and a pose invariant 3D reconstruction without the need of the code optimization step. Extensive experiments, involving both ablation studies and comparison with competing methods, demonstrate the efficacy of our proposed method, and compare favorably with the state-of-the-art.
DDM-NET: End-to-end learning of keypoint feature Detection, Description and Matching for 3D localization
Dec 08, 2022



In this paper, we propose an end-to-end framework that jointly learns keypoint detection, descriptor representation and cross-frame matching for the task of image-based 3D localization. Prior art has tackled each of these components individually, purportedly aiming to alleviate difficulties in effectively train a holistic network. We design a self-supervised image warping correspondence loss for both feature detection and matching, a weakly-supervised epipolar constraints loss on relative camera pose learning, and a directional matching scheme that detects key-point features in a source image and performs coarse-to-fine correspondence search on the target image. We leverage this framework to enforce cycle consistency in our matching module. In addition, we propose a new loss to robustly handle both definite inlier/outlier matches and less-certain matches. The integration of these learning mechanisms enables end-to-end training of a single network performing all three localization components. Bench-marking our approach on public data-sets, exemplifies how such an end-to-end framework is able to yield more accurate localization that out-performs both traditional methods as well as state-of-the-art weakly supervised methods.
Implicit Autoencoder for Point Cloud Self-supervised Representation Learning
Jan 03, 2022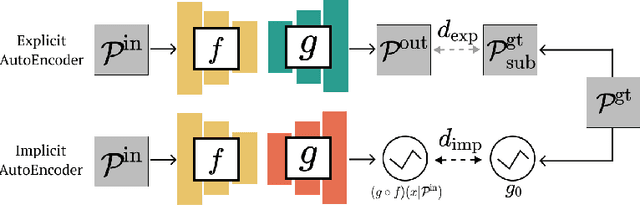
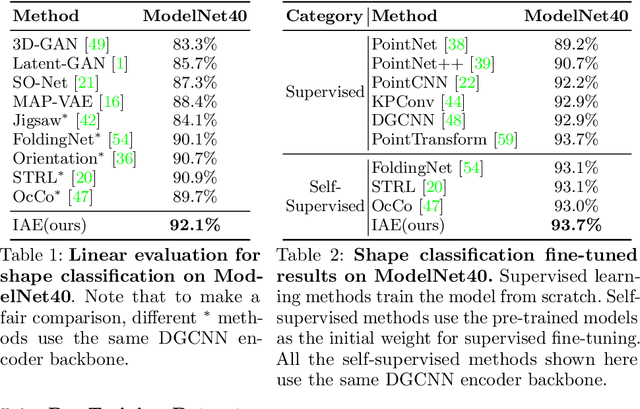
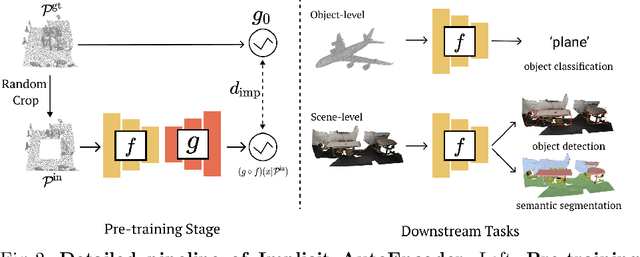

Many 3D representations (e.g., point clouds) are discrete samples of the underlying continuous 3D surface. This process inevitably introduces sampling variations on the underlying 3D shapes. In learning 3D representation, the variations should be disregarded while transferable knowledge of the underlying 3D shape should be captured. This becomes a grand challenge in existing representation learning paradigms. This paper studies autoencoding on point clouds. The standard autoencoding paradigm forces the encoder to capture such sampling variations as the decoder has to reconstruct the original point cloud that has sampling variations. We introduce Implicit Autoencoder(IAE), a simple yet effective method that addresses this challenge by replacing the point cloud decoder with an implicit decoder. The implicit decoder outputs a continuous representation that is shared among different point cloud sampling of the same model. Reconstructing under the implicit representation can prioritize that the encoder discards sampling variations, introducing more space to learn useful features. We theoretically justify this claim under a simple linear autoencoder. Moreover, the implicit decoder offers a rich space to design suitable implicit representations for different tasks. We demonstrate the usefulness of IAE across various self-supervised learning tasks for both 3D objects and 3D scenes. Experimental results show that IAE consistently outperforms the state-of-the-art in each task.
Beyond Visual Attractiveness: Physically Plausible Single Image HDR Reconstruction for Spherical Panoramas
Mar 24, 2021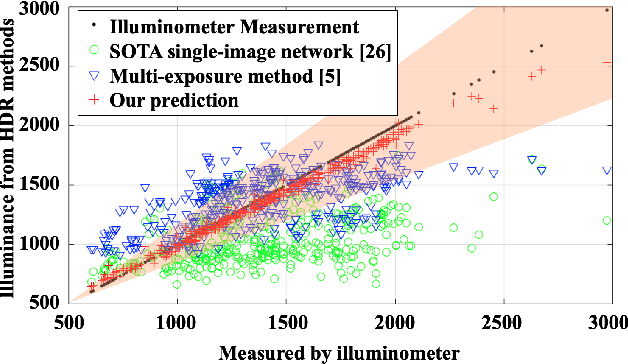

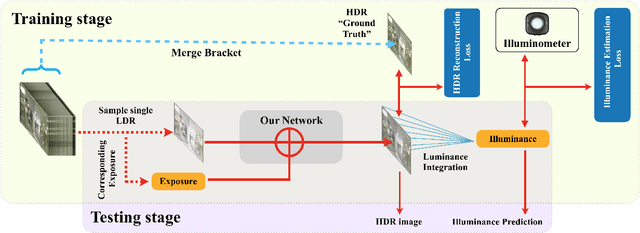
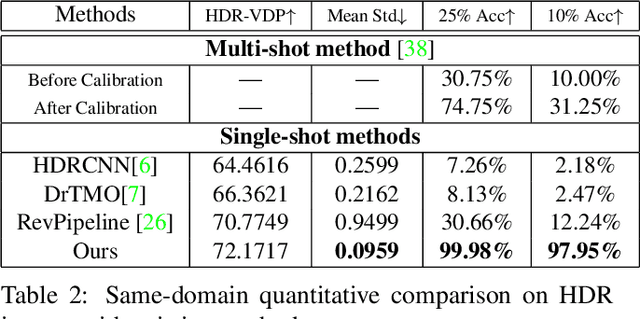
HDR reconstruction is an important task in computer vision with many industrial needs. The traditional approaches merge multiple exposure shots to generate HDRs that correspond to the physical quantity of illuminance of the scene. However, the tedious capturing process makes such multi-shot approaches inconvenient in practice. In contrast, recent single-shot methods predict a visually appealing HDR from a single LDR image through deep learning. But it is not clear whether the previously mentioned physical properties would still hold, without training the network to explicitly model them. In this paper, we introduce the physical illuminance constraints to our single-shot HDR reconstruction framework, with a focus on spherical panoramas. By the proposed physical regularization, our method can generate HDRs which are not only visually appealing but also physically plausible. For evaluation, we collect a large dataset of LDR and HDR images with ground truth illuminance measures. Extensive experiments show that our HDR images not only maintain high visual quality but also top all baseline methods in illuminance prediction accuracy.
Pano Popups: Indoor 3D Reconstruction with a Plane-Aware Network
Jul 01, 2019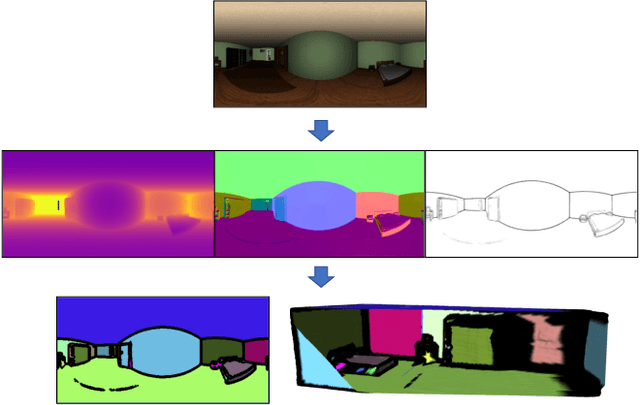
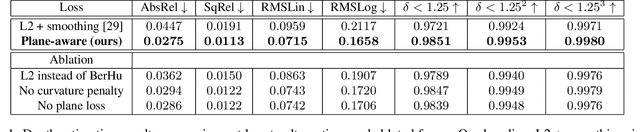
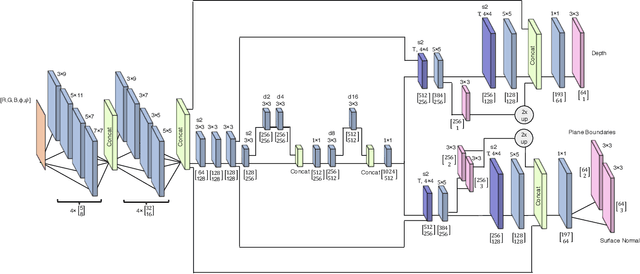
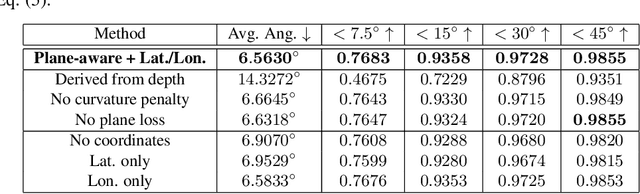
In this work we present a method to train a plane-aware convolutional neural network for dense depth and surface normal estimation as well as plane boundaries from a single indoor \threesixty image. Using our proposed loss function, our network outperforms existing methods for single-view, indoor, omnidirectional depth estimation and provides an initial benchmark for surface normal prediction from \threesixty images. Our improvements are due to the use of a novel plane-aware loss that leverages principal curvature as an indicator of planar boundaries. We also show that including geodesic coordinate maps as network priors provides a significant boost in surface normal prediction accuracy. Finally, we demonstrate how we can combine our network's outputs to generate high quality 3D ``pop-up" models of indoor scenes.