 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoder Gradient Shields: A Family of Provable and High-Fidelity Methods Against Gradient-Based Box-Free Watermark Removal
Jan 17, 2026Box-free model watermarking has gained significant attention in deep neural network (DNN) intellectual property protection due to its model-agnostic nature and its ability to flexibly manage high-entropy image outputs from generative models. Typically operating in a black-box manner, it employs an encoder-decoder framework for watermark embedding and extraction. While existing research has focused primarily on the encoders for the robustness to resist various attacks, the decoders have been largely overlooked, leading to attacks against the watermark. In this paper, we identify one such attack against the decoder, where query responses are utilized to obtain backpropagated gradients to train a watermark remover. To address this issue, we propose Decoder Gradient Shields (DGSs), a family of defense mechanisms, including DGS at the output (DGS-O), at the input (DGS-I), and in the layers (DGS-L) of the decoder, with a closed-form solution for DGS-O and provable performance for all DGS. Leveraging the joint design of reorienting and rescaling of the gradients from watermark channel gradient leaking queries, the proposed DGSs effectively prevent the watermark remover from achieving training convergence to the desired low-loss value, while preserving image quality of the decoder output. We demonstrate the effectiveness of our proposed DGSs in diverse application scenarios. Our experimental results on deraining and image generation tasks with the state-of-the-art box-free watermarking show that our DGSs achieve a defense success rate of 100% under all settings.
NWaaS: Nonintrusive Watermarking as a Service for X-to-Image DNN
Jul 24, 2025The intellectual property of deep neural network (DNN) models can be protected with DNN watermarking, which embeds copyright watermarks into model parameters (white-box), model behavior (black-box), or model outputs (box-free), and the watermarks can be subsequently extracted to verify model ownership or detect model theft. Despite recent advances, these existing methods are inherently intrusive, as they either modify the model parameters or alter the structure. This natural intrusiveness raises concerns about watermarking-induced shifts in model behavior and the additional cost of fine-tuning, further exacerbated by the rapidly growing model size. As a result, model owners are often reluctant to adopt DNN watermarking in practice, which limits the development of practical Watermarking as a Service (WaaS) systems. To address this issue, we introduce Nonintrusive Watermarking as a Service (NWaaS), a novel trustless paradigm designed for X-to-Image models, in which we hypothesize that with the model untouched, an owner-defined watermark can still be extracted from model outputs. Building on this concept, we propose ShadowMark, a concrete implementation of NWaaS which addresses critical deployment challenges by establishing a robust and nonintrusive side channel in the protected model's black-box API, leveraging a key encoder and a watermark decoder. It is significantly distinctive from existing solutions by attaining the so-called absolute fidelity and being applicable to different DNN architectures, while being also robust against existing attacks, eliminating the fidelity-robustness trade-off. Extensive experiments on image-to-image, noise-to-image, noise-and-text-to-image, and text-to-image models, demonstrate the efficacy and practicality of ShadowMark for real-world deployment of nonintrusive DNN watermarking.
Decoder Gradient Shield: Provable and High-Fidelity Prevention of Gradient-Based Box-Free Watermark Removal
Feb 28, 2025



The intellectual property of deep image-to-image models can be protected by the so-called box-free watermarking. It uses an encoder and a decoder, respectively, to embed into and extract from the model's output images invisible copyright marks. Prior works have improved watermark robustness, focusing on the design of better watermark encoders. In this paper, we reveal an overlooked vulnerability of the unprotected watermark decoder which is jointly trained with the encoder and can be exploited to train a watermark removal network. To defend against such an attack, we propose the decoder gradient shield (DGS) as a protection layer in the decoder API to prevent gradient-based watermark removal with a closed-form solution. The fundamental idea is inspired by the classical adversarial attack, but is utilized for the first time as a defensive mechanism in the box-free model watermarking. We then demonstrate that DGS can reorient and rescale the gradient directions of watermarked queries and stop the watermark remover's training loss from converging to the level without DGS, while retaining decoder output image quality. Experimental results verify the effectiveness of proposed method. Code of paper will be made available upon acceptance.
A Key-Driven Framework for Identity-Preserving Face Anonymization
Sep 05, 2024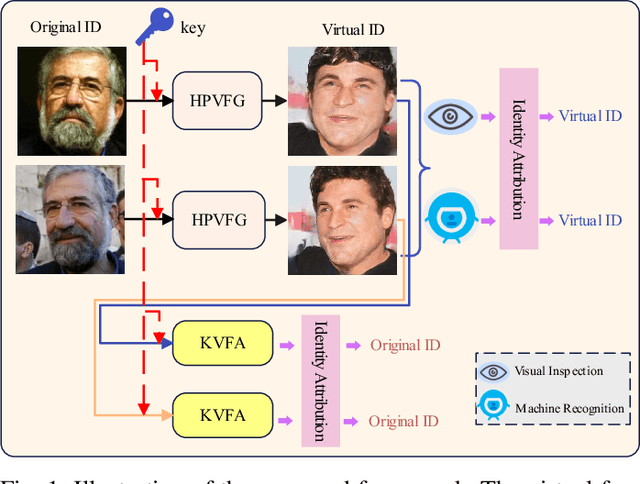
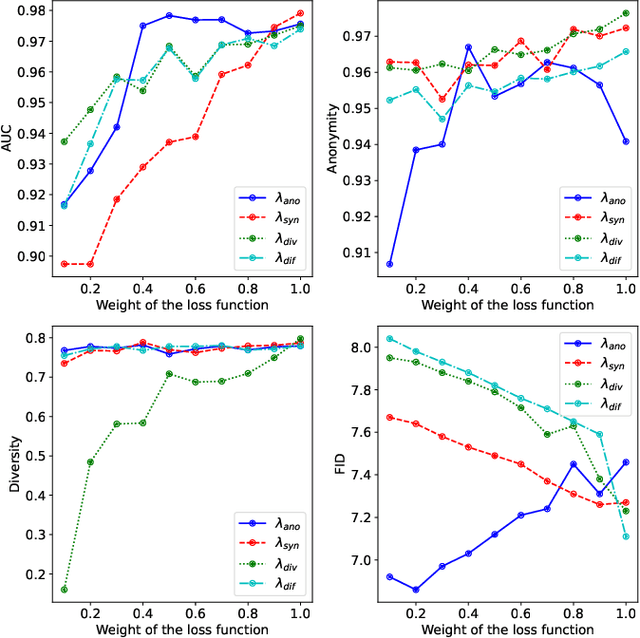
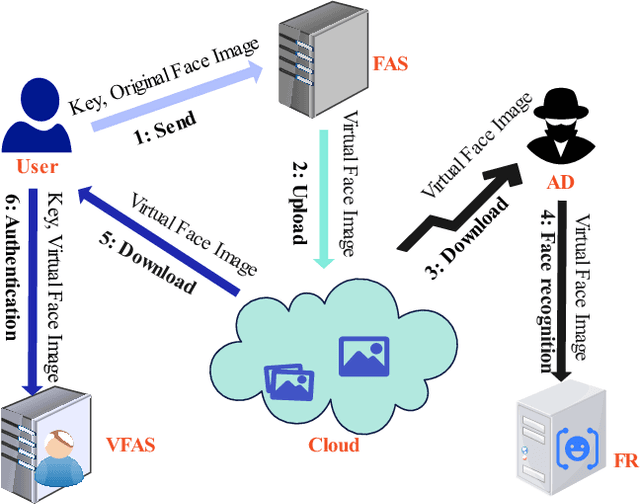
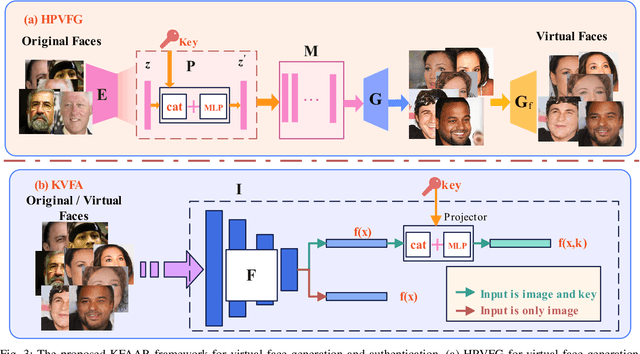
Virtual faces are crucial content in the metaverse. Recently, attempts have been made to generate virtual faces for privacy protection. Nevertheless, these virtual faces either permanently remove the identifiable information or map the original identity into a virtual one, which loses the original identity forever. In this study, we first attempt to address the conflict between privacy and identifiability in virtual faces, where a key-driven face anonymization and authentication recognition (KFAAR) framework is proposed. Concretely, the KFAAR framework consists of a head posture-preserving virtual face generation (HPVFG) module and a key-controllable virtual face authentication (KVFA) module. The HPVFG module uses a user key to project the latent vector of the original face into a virtual one. Then it maps the virtual vectors to obtain an extended encoding, based on which the virtual face is generated. By simultaneously adding a head posture and facial expression correction module, the virtual face has the same head posture and facial expression as the original face. During the authentication, we propose a KVFA module to directly recognize the virtual faces using the correct user key, which can obtain the original identity without exposing the original face image. We also propose a multi-task learning objective to train HPVFG and KVFA. Extensive experiments demonstrate the advantages of the proposed HPVFG and KVFA modules, which effectively achieve both facial anonymity and identifiability.
Box-Free Model Watermarks Are Prone to Black-Box Removal Attacks
May 16, 2024


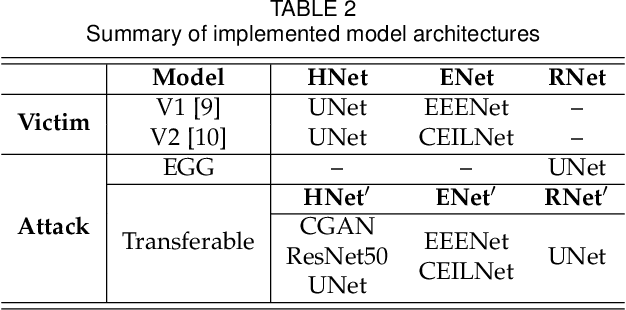
Box-free model watermarking is an emerging technique to safeguard the intellectual property of deep learning models, particularly those for low-level image processing tasks. Existing works have verified and improved its effectiveness in several aspects. However, in this paper, we reveal that box-free model watermarking is prone to removal attacks, even under the real-world threat model such that the protected model and the watermark extractor are in black boxes. Under this setting, we carry out three studies. 1) We develop an extractor-gradient-guided (EGG) remover and show its effectiveness when the extractor uses ReLU activation only. 2) More generally, for an unknown extractor, we leverage adversarial attacks and design the EGG remover based on the estimated gradients. 3) Under the most stringent condition that the extractor is inaccessible, we design a transferable remover based on a set of private proxy models. In all cases, the proposed removers can successfully remove embedded watermarks while preserving the quality of the processed images, and we also demonstrate that the EGG remover can even replace the watermarks. Extensive experimental results verify the effectiveness and generalizability of the proposed attacks, revealing the vulnerabilities of the existing box-free methods and calling for further research.
Detecting Every Object from Events
Apr 08, 2024



Object detection is critical in autonomous driving, and it is more practical yet challenging to localize objects of unknown categories: an endeavour known as Class-Agnostic Object Detection (CAOD). Existing studies on CAOD predominantly rely on ordinary cameras, but these frame-based sensors usually have high latency and limited dynamic range, leading to safety risks in real-world scenarios. In this study, we turn to a new modality enabled by the so-called event camera, featured by its sub-millisecond latency and high dynamic range, for robust CAOD. We propose Detecting Every Object in Events (DEOE), an approach tailored for achieving high-speed, class-agnostic open-world object detection in event-based vision. Built upon the fast event-based backbone: recurrent vision transformer, we jointly consider the spatial and temporal consistencies to identify potential objects. The discovered potential objects are assimilated as soft positive samples to avoid being suppressed as background. Moreover, we introduce a disentangled objectness head to separate the foreground-background classification and novel object discovery tasks, enhancing the model's generalization in localizing novel objects while maintaining a strong ability to filter out the background. Extensive experiments confirm the superiority of our proposed DEOE in comparison with three strong baseline methods that integrate the state-of-the-art event-based object detector with advancements in RGB-based CAOD. Our code is available at https://github.com/Hatins/DEOE.
"Seeing'' Electric Network Frequency from Events
May 04, 2023Most of the artificial lights fluctuate in response to the grid's alternating current and exhibit subtle variations in terms of both intensity and spectrum, providing the potential to estimate the Electric Network Frequency (ENF) from conventional frame-based videos. Nevertheless, the performance of Video-based ENF (V-ENF) estimation largely relies on the imaging quality and thus may suffer from significant interference caused by non-ideal sampling, motion, and extreme lighting conditions. In this paper, we show that the ENF can be extracted without the above limitations from a new modality provided by the so-called event camera, a neuromorphic sensor that encodes the light intensity variations and asynchronously emits events with extremely high temporal resolution and high dynamic range. Specifically, we first formulate and validate the physical mechanism for the ENF captured in events, and then propose a simple yet robust Event-based ENF (E-ENF) estimation method through mode filtering and harmonic enhancement. Furthermore, we build an Event-Video ENF Dataset (EV-ENFD) that records both events and videos in diverse scenes. Extensive experiments on EV-ENFD demonstrate that our proposed E-ENF method can extract more accurate ENF traces, outperforming the conventional V-ENF by a large margin, especially in challenging environments with object motions and extreme lighting conditions. The code and dataset are available at https://xlx-creater.github.io/E-ENF.
DDM-NET: End-to-end learning of keypoint feature Detection, Description and Matching for 3D localization
Dec 08, 2022



In this paper, we propose an end-to-end framework that jointly learns keypoint detection, descriptor representation and cross-frame matching for the task of image-based 3D localization. Prior art has tackled each of these components individually, purportedly aiming to alleviate difficulties in effectively train a holistic network. We design a self-supervised image warping correspondence loss for both feature detection and matching, a weakly-supervised epipolar constraints loss on relative camera pose learning, and a directional matching scheme that detects key-point features in a source image and performs coarse-to-fine correspondence search on the target image. We leverage this framework to enforce cycle consistency in our matching module. In addition, we propose a new loss to robustly handle both definite inlier/outlier matches and less-certain matches. The integration of these learning mechanisms enables end-to-end training of a single network performing all three localization components. Bench-marking our approach on public data-sets, exemplifies how such an end-to-end framework is able to yield more accurate localization that out-performs both traditional methods as well as state-of-the-art weakly supervised methods.
Towards End-to-End Synthetic Speech Detection
Jun 11, 2021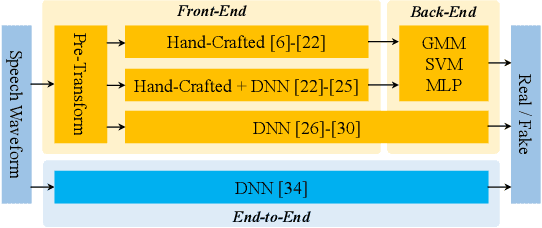
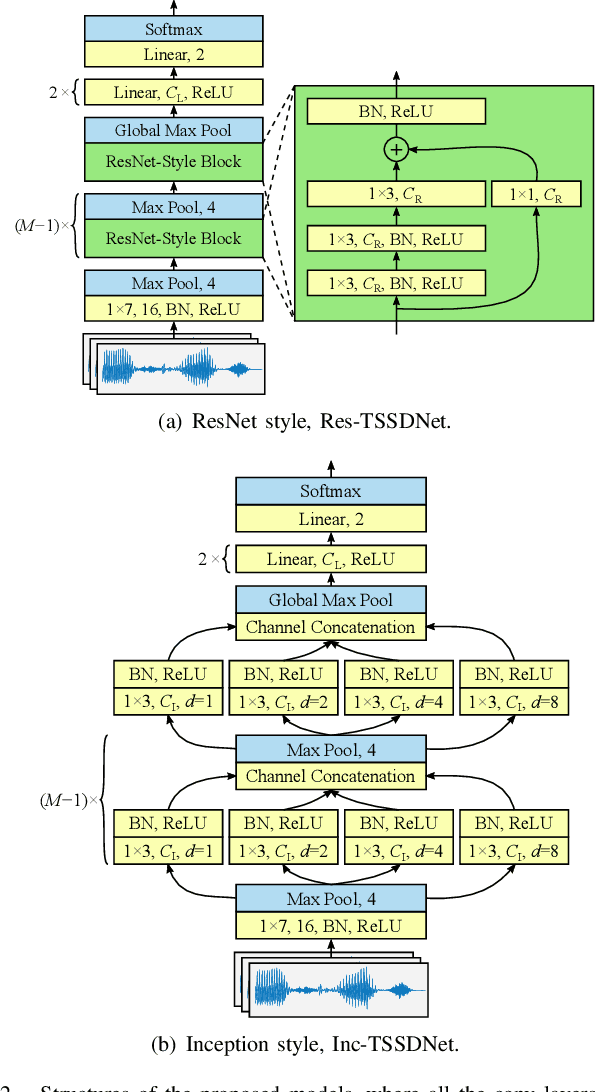
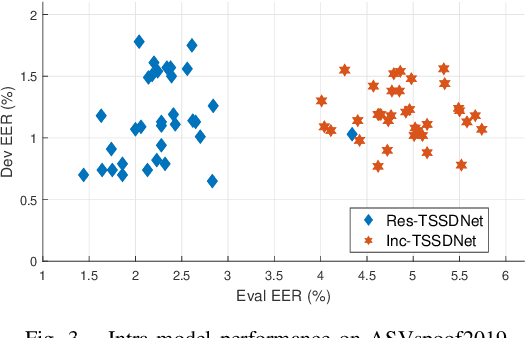
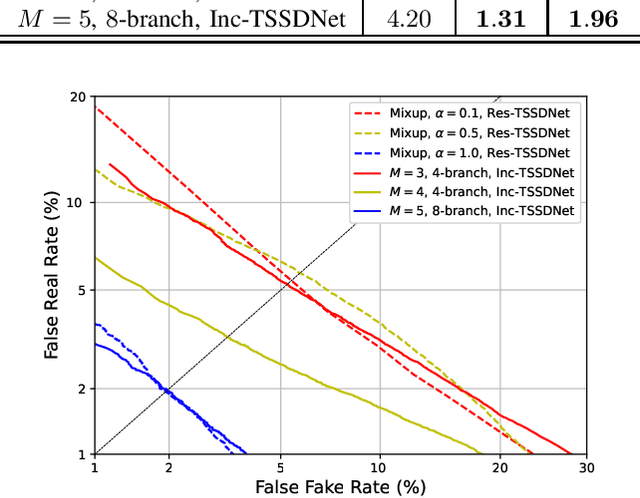
The constant Q transform (CQT) has been shown to be one of the most effective speech signal pre-transforms to facilitate synthetic speech detection, followed by either hand-crafted (subband) constant Q cepstral coefficient (CQCC) feature extraction and a back-end binary classifier, or a deep neural network (DNN) directly for further feature extraction and classification. Despite the rich literature on such a pipeline, we show in this paper that the pre-transform and hand-crafted features could simply be replaced by end-to-end DNNs. Specifically, we experimentally verify that by only using standard components, a light-weight neural network could outperform the state-of-the-art methods for the ASVspoof2019 challenge. The proposed model is termed Time-domain Synthetic Speech Detection Net (TSSDNet), having ResNet- or Inception-style structures. We further demonstrate that the proposed models also have attractive generalization capability. Trained on ASVspoof2019, they could achieve promising detection performance when tested on disjoint ASVspoof2015, significantly better than the existing cross-dataset results. This paper reveals the great potential of end-to-end DNNs for synthetic speech detection, without hand-crafted features.