 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBox-Free Model Watermarks Are Prone to Black-Box Removal Attacks
Paper and Code
May 16, 2024


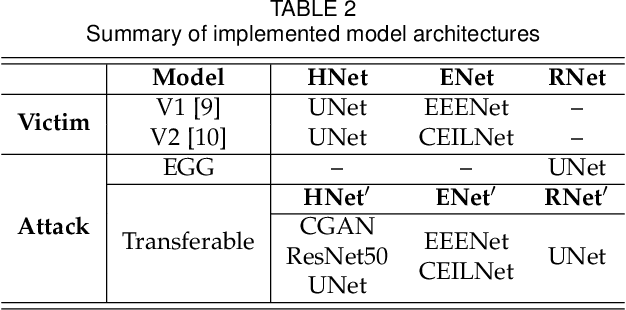
Box-free model watermarking is an emerging technique to safeguard the intellectual property of deep learning models, particularly those for low-level image processing tasks. Existing works have verified and improved its effectiveness in several aspects. However, in this paper, we reveal that box-free model watermarking is prone to removal attacks, even under the real-world threat model such that the protected model and the watermark extractor are in black boxes. Under this setting, we carry out three studies. 1) We develop an extractor-gradient-guided (EGG) remover and show its effectiveness when the extractor uses ReLU activation only. 2) More generally, for an unknown extractor, we leverage adversarial attacks and design the EGG remover based on the estimated gradients. 3) Under the most stringent condition that the extractor is inaccessible, we design a transferable remover based on a set of private proxy models. In all cases, the proposed removers can successfully remove embedded watermarks while preserving the quality of the processed images, and we also demonstrate that the EGG remover can even replace the watermarks. Extensive experimental results verify the effectiveness and generalizability of the proposed attacks, revealing the vulnerabilities of the existing box-free methods and calling for further research.