 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRUC: Feedforward Dynamic Scene Reconstruction from Uncalibrated Collaborative Driving Views
May 28, 2026We present FRUC, a feed-forward 3D Gaussian splatting framework for dynamic scene reconstruction from uncalibrated collaborative driving views. Existing multi-agent reconstruction frameworks are often hindered by rigid prerequisites, demanding precise spatial calibration and slow per-scene optimization. In this paper, we rethink this task by conceptualizing a distributed multi-vehicle network as a spatio-temporally unstructured ego-centric multi-camera system, where the core challenge lies in enhancing ego-centric occluded geometry through collaboration without degrading the ego's accurately observed visible geometry, while preserving reconstruction efficiency. For efficient reconstruction, FRUC is built upon a visual grounded geometric Transformer backbone to enable one-shot, calibration-free inference from a flexible number of multi-vehicle views. To achieve non-destructive geometric supplementation under uncalibrated cross-agent misalignment, FRUC first introduces an ego-centric causal occlusion field that explicitly derives occlusion evolution as latent priors by modeling agent-wise spatio-temporal correlations. Guided by these occlusion priors, it further formulates cross-agent integration as a deterministic residual denoising process via zero-initialized injection, turning challenging cross-agent fusion into bounded residual learning for robust collaborative blind-spot completion. Through extensive evaluations on the real-world V2XReal and UrbanIng-V2X datasets, FRUC is shown to be a new state-of-the-art for the scene reconstruction of dynamic collaborative driving environments, significantly outperforming existing methods in both rendering quality and efficiency.
Aggregation Alignment for Federated Learning with Mixture-of-Experts under Data Heterogeneity
Mar 22, 2026Large language models (LLMs) increasingly adopt Mixture-of-Experts (MoE) architectures to scale model capacity while reducing computation. Fine-tuning these MoE-based LLMs often requires access to distributed and privacy-sensitive data, making centralized fine-tuning impractical. Federated learning (FL) therefore provides a paradigm to collaboratively fine-tune MoE-based LLMs, enabling each client to integrate diverse knowledge without compromising data privacy. However, the integration of MoE-based LLM fine-tuning into FL encounters two critical aggregation challenges due to inherent data heterogeneity across clients: (i) divergent local data distributions drive clients to develop distinct gating preference for localized expert selection, causing direct parameter aggregation to produce a ``one-size-fits-none'' global gating network, and (ii) same-indexed experts develop disparate semantic roles across clients, leading to expert semantic blurring and the degradation of expert specialization. To address these challenges, we propose FedAlign-MoE, a federated aggregation alignment framework that jointly enforces routing consistency and expert semantic alignment. Specifically, FedAlign-MoE aggregates gating behaviors by aligning routing distributions through consistency weighting and optimizes local gating networks through distribution regularization, maintaining cross-client stability without overriding discriminative local preferences. Meanwhile, FedAlign-MoE explicitly quantifies semantic consistency among same-indexed experts across clients and selectively aggregates updates from semantically aligned clients, ensuring stable and specialized functional roles for global experts. Extensive experiments demonstrate that FedAlign-MoE outperforms state-of-the-art benchmarks, achieving faster convergence and superior accuracy in non-IID federated environments.
RecoverMark: Robust Watermarking for Localization and Recovery of Manipulated Faces
Feb 24, 2026The proliferation of AI-generated content has facilitated sophisticated face manipulation, severely undermining visual integrity and posing unprecedented challenges to intellectual property. In response, a common proactive defense leverages fragile watermarks to detect, localize, or even recover manipulated regions. However, these methods always assume an adversary unaware of the embedded watermark, overlooking their inherent vulnerability to watermark removal attacks. Furthermore, this fragility is exacerbated in the commonly used dual-watermark strategy that adds a robust watermark for image ownership verification, where mutual interference and limited embedding capacity reduce the fragile watermark's effectiveness. To address the gap, we propose RecoverMark, a watermarking framework that achieves robust manipulation localization, content recovery, and ownership verification simultaneously. Our key insight is twofold. First, we exploit a critical real-world constraint: an adversary must preserve the background's semantic consistency to avoid visual detection, even if they apply global, imperceptible watermark removal attacks. Second, using the image's own content (face, in this paper) as the watermark enhances extraction robustness. Based on these insights, RecoverMark treats the protected face content itself as the watermark and embeds it into the surrounding background. By designing a robust two-stage training paradigm with carefully crafted distortion layers that simulate comprehensive potential attacks and a progressive training strategy, RecoverMark achieves a robust watermark embedding in no fragile manner for image manipulation localization, recovery, and image IP protection simultaneously. Extensive experiments demonstrate the proposed RecoverMark's robustness against both seen and unseen attacks and its generalizability to in-distribution and out-of-distribution data.
Learning Mutual View Information Graph for Adaptive Adversarial Collaborative Perception
Feb 23, 2026Collaborative perception (CP) enables data sharing among connected and autonomous vehicles (CAVs) to enhance driving safety. However, CP systems are vulnerable to adversarial attacks where malicious agents forge false objects via feature-level perturbations. Current defensive systems use threshold-based consensus verification by comparing collaborative and ego detection results. Yet, these defenses remain vulnerable to more sophisticated attack strategies that could exploit two critical weaknesses: (i) lack of robustness against attacks with systematic timing and target region optimization, and (ii) inadvertent disclosure of vulnerability knowledge through implicit confidence information in shared collaboration data. In this paper, we propose MVIG attack, a novel adaptive adversarial CP framework learning to capture vulnerability knowledge disclosed by different defensive CP systems from a unified mutual view information graph (MVIG) representation. Our approach combines MVIG representation with temporal graph learning to generate evolving fabrication risk maps and employs entropy-aware vulnerability search to optimize attack location, timing and persistence, enabling adaptive attacks with generalizability across various defensive configurations. Extensive evaluations on OPV2V and Adv-OPV2V datasets demonstrate that MVIG attack reduces defense success rates by up to 62\% against state-of-the-art defenses while achieving 47\% lower detection for persistent attacks at 29.9 FPS, exposing critical security gaps in CP systems. Code will be released at https://github.com/yihangtao/MVIG.git
Decoder Gradient Shields: A Family of Provable and High-Fidelity Methods Against Gradient-Based Box-Free Watermark Removal
Jan 17, 2026Box-free model watermarking has gained significant attention in deep neural network (DNN) intellectual property protection due to its model-agnostic nature and its ability to flexibly manage high-entropy image outputs from generative models. Typically operating in a black-box manner, it employs an encoder-decoder framework for watermark embedding and extraction. While existing research has focused primarily on the encoders for the robustness to resist various attacks, the decoders have been largely overlooked, leading to attacks against the watermark. In this paper, we identify one such attack against the decoder, where query responses are utilized to obtain backpropagated gradients to train a watermark remover. To address this issue, we propose Decoder Gradient Shields (DGSs), a family of defense mechanisms, including DGS at the output (DGS-O), at the input (DGS-I), and in the layers (DGS-L) of the decoder, with a closed-form solution for DGS-O and provable performance for all DGS. Leveraging the joint design of reorienting and rescaling of the gradients from watermark channel gradient leaking queries, the proposed DGSs effectively prevent the watermark remover from achieving training convergence to the desired low-loss value, while preserving image quality of the decoder output. We demonstrate the effectiveness of our proposed DGSs in diverse application scenarios. Our experimental results on deraining and image generation tasks with the state-of-the-art box-free watermarking show that our DGSs achieve a defense success rate of 100% under all settings.
Shared Spatial Memory Through Predictive Coding
Nov 06, 2025

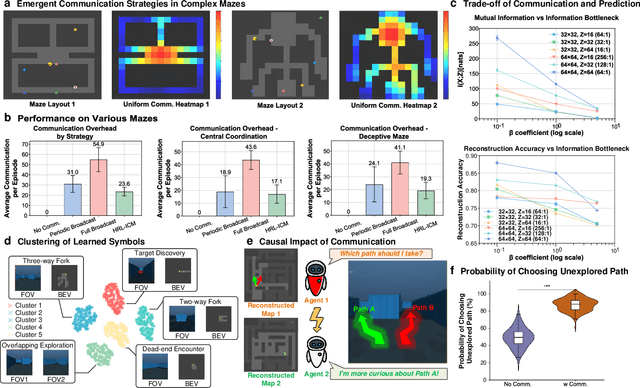
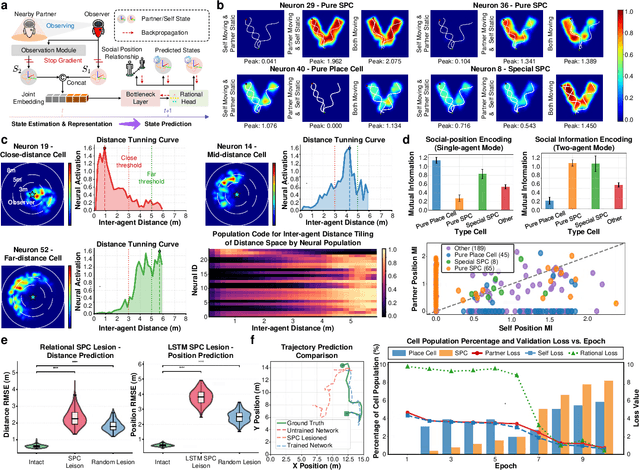
Sharing and reconstructing a consistent spatial memory is a critical challenge in multi-agent systems, where partial observability and limited bandwidth often lead to catastrophic failures in coordination. We introduce a multi-agent predictive coding framework that formulate coordination as the minimization of mutual uncertainty among agents. Instantiated as an information bottleneck objective, it prompts agents to learn not only who and what to communicate but also when. At the foundation of this framework lies a grid-cell-like metric as internal spatial coding for self-localization, emerging spontaneously from self-supervised motion prediction. Building upon this internal spatial code, agents gradually develop a bandwidth-efficient communication mechanism and specialized neural populations that encode partners' locations: an artificial analogue of hippocampal social place cells (SPCs). These social representations are further enacted by a hierarchical reinforcement learning policy that actively explores to reduce joint uncertainty. On the Memory-Maze benchmark, our approach shows exceptional resilience to bandwidth constraints: success degrades gracefully from 73.5% to 64.4% as bandwidth shrinks from 128 to 4 bits/step, whereas a full-broadcast baseline collapses from 67.6% to 28.6%. Our findings establish a theoretically principled and biologically plausible basis for how complex social representations emerge from a unified predictive drive, leading to social collective intelligence.
NWaaS: Nonintrusive Watermarking as a Service for X-to-Image DNN
Jul 24, 2025The intellectual property of deep neural network (DNN) models can be protected with DNN watermarking, which embeds copyright watermarks into model parameters (white-box), model behavior (black-box), or model outputs (box-free), and the watermarks can be subsequently extracted to verify model ownership or detect model theft. Despite recent advances, these existing methods are inherently intrusive, as they either modify the model parameters or alter the structure. This natural intrusiveness raises concerns about watermarking-induced shifts in model behavior and the additional cost of fine-tuning, further exacerbated by the rapidly growing model size. As a result, model owners are often reluctant to adopt DNN watermarking in practice, which limits the development of practical Watermarking as a Service (WaaS) systems. To address this issue, we introduce Nonintrusive Watermarking as a Service (NWaaS), a novel trustless paradigm designed for X-to-Image models, in which we hypothesize that with the model untouched, an owner-defined watermark can still be extracted from model outputs. Building on this concept, we propose ShadowMark, a concrete implementation of NWaaS which addresses critical deployment challenges by establishing a robust and nonintrusive side channel in the protected model's black-box API, leveraging a key encoder and a watermark decoder. It is significantly distinctive from existing solutions by attaining the so-called absolute fidelity and being applicable to different DNN architectures, while being also robust against existing attacks, eliminating the fidelity-robustness trade-off. Extensive experiments on image-to-image, noise-to-image, noise-and-text-to-image, and text-to-image models, demonstrate the efficacy and practicality of ShadowMark for real-world deployment of nonintrusive DNN watermarking.
Decoder Gradient Shield: Provable and High-Fidelity Prevention of Gradient-Based Box-Free Watermark Removal
Feb 28, 2025



The intellectual property of deep image-to-image models can be protected by the so-called box-free watermarking. It uses an encoder and a decoder, respectively, to embed into and extract from the model's output images invisible copyright marks. Prior works have improved watermark robustness, focusing on the design of better watermark encoders. In this paper, we reveal an overlooked vulnerability of the unprotected watermark decoder which is jointly trained with the encoder and can be exploited to train a watermark removal network. To defend against such an attack, we propose the decoder gradient shield (DGS) as a protection layer in the decoder API to prevent gradient-based watermark removal with a closed-form solution. The fundamental idea is inspired by the classical adversarial attack, but is utilized for the first time as a defensive mechanism in the box-free model watermarking. We then demonstrate that DGS can reorient and rescale the gradient directions of watermarked queries and stop the watermark remover's training loss from converging to the level without DGS, while retaining decoder output image quality. Experimental results verify the effectiveness of proposed method. Code of paper will be made available upon acceptance.
GCP: Guarded Collaborative Perception with Spatial-Temporal Aware Malicious Agent Detection
Jan 05, 2025Collaborative perception significantly enhances autonomous driving safety by extending each vehicle's perception range through message sharing among connected and autonomous vehicles. Unfortunately, it is also vulnerable to adversarial message attacks from malicious agents, resulting in severe performance degradation. While existing defenses employ hypothesis-and-verification frameworks to detect malicious agents based on single-shot outliers, they overlook temporal message correlations, which can be circumvented by subtle yet harmful perturbations in model input and output spaces. This paper reveals a novel blind area confusion (BAC) attack that compromises existing single-shot outlier-based detection methods. As a countermeasure, we propose GCP, a Guarded Collaborative Perception framework based on spatial-temporal aware malicious agent detection, which maintains single-shot spatial consistency through a confidence-scaled spatial concordance loss, while simultaneously examining temporal anomalies by reconstructing historical bird's eye view motion flows in low-confidence regions. We also employ a joint spatial-temporal Benjamini-Hochberg test to synthesize dual-domain anomaly results for reliable malicious agent detection. Extensive experiments demonstrate GCP's superior performance under diverse attack scenarios, achieving up to 34.69% improvements in AP@0.5 compared to the state-of-the-art CP defense strategies under BAC attacks, while maintaining consistent 5-8% improvements under other typical attacks. Code will be released at https://github.com/CP-Security/GCP.git.
Channel-Aware Throughput Maximization for Cooperative Data Fusion in CAV
Oct 06, 2024Connected and autonomous vehicles (CAVs) have garnered significant attention due to their extended perception range and enhanced sensing coverage. To address challenges such as blind spots and obstructions, CAVs employ vehicle-to-vehicle (V2V) communications to aggregate sensory data from surrounding vehicles. However, cooperative perception is often constrained by the limitations of achievable network throughput and channel quality. In this paper, we propose a channel-aware throughput maximization approach to facilitate CAV data fusion, leveraging a self-supervised autoencoder for adaptive data compression. We formulate the problem as a mixed integer programming (MIP) model, which we decompose into two sub-problems to derive optimal data rate and compression ratio solutions under given link conditions. An autoencoder is then trained to minimize bitrate with the determined compression ratio, and a fine-tuning strategy is employed to further reduce spectrum resource consumption. Experimental evaluation on the OpenCOOD platform demonstrates the effectiveness of our proposed algorithm, showing more than 20.19\% improvement in network throughput and a 9.38\% increase in average precision (AP@IoU) compared to state-of-the-art methods, with an optimal latency of 19.99 ms.