 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAU-R1: Visual Language Model for Traffic Anomaly Understanding
Mar 19, 2026Traffic Anomaly Understanding (TAU) is important for traffic safety in Intelligent Transportation Systems. Recent vision-language models (VLMs) have shown strong capabilities in video understanding. However, progress on TAU remains limited due to the lack of benchmarks and task-specific methodologies. To address this limitation, we introduce Roundabout-TAU, a dataset constructed from real-world roundabout videos collected in collaboration with the City of Carmel, Indiana. The dataset contains 342 clips and is annotated with more than 2,000 question-answer pairs covering multiple aspects of traffic anomaly understanding. Building on this benchmark, we propose TAU-R1, a two-layer vision-language framework for TAU. The first layer is a lightweight anomaly classifier that performs coarse anomaly categorisation, while the second layer is a larger anomaly reasoner that generates detailed event summaries. To improve task-specific reasoning, we introduce a two-stage training strategy consisting of decomposed-QA-enhanced supervised fine-tuning followed by TAU-GRPO, a GRPO-based post-training method with TAU-specific reward functions. Experimental results show that TAU-R1 achieves strong performance on both anomaly classification and reasoning tasks while maintaining deployment efficiency. The dataset and code are available at: https://github.com/siri-rouser/TAU-R1
DCDM: Divide-and-Conquer Diffusion Models for Consistency-Preserving Video Generation
Feb 14, 2026Recent video generative models have demonstrated impressive visual fidelity, yet they often struggle with semantic, geometric, and identity consistency. In this paper, we propose a system-level framework, termed the Divide-and-Conquer Diffusion Model (DCDM), to address three key challenges: (1) intra-clip world knowledge consistency, (2) inter-clip camera consistency, and (3) inter-shot element consistency. DCDM decomposes video consistency modeling under these scenarios into three dedicated components while sharing a unified video generation backbone. For intra-clip consistency, DCDM leverages a large language model to parse input prompts into structured semantic representations, which are subsequently translated into coherent video content by a diffusion transformer. For inter-clip camera consistency, we propose a temporal camera representation in the noise space that enables precise and stable camera motion control, along with a text-to-image initialization mechanism to further enhance controllability. For inter-shot consistency, DCDM adopts a holistic scene generation paradigm with windowed cross-attention and sparse inter-shot self-attention, ensuring long-range narrative coherence while maintaining computational efficiency. We validate our framework on the test set of the CVM Competition at AAAI'26, and the results demonstrate that the proposed strategies effectively address these challenges.
Shared Spatial Memory Through Predictive Coding
Nov 06, 2025

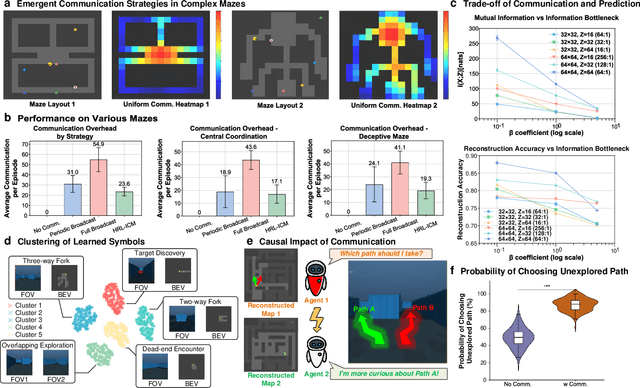
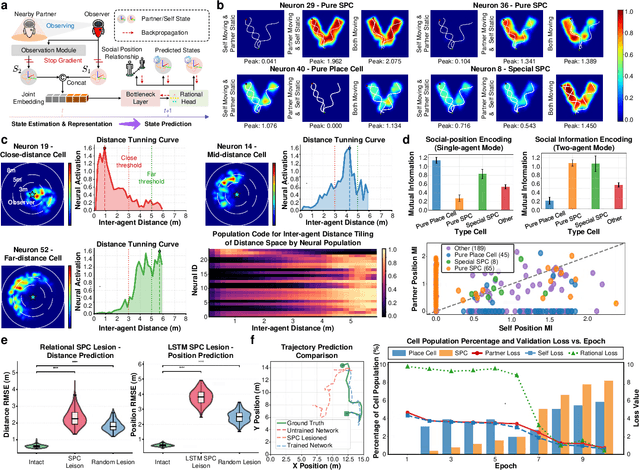
Sharing and reconstructing a consistent spatial memory is a critical challenge in multi-agent systems, where partial observability and limited bandwidth often lead to catastrophic failures in coordination. We introduce a multi-agent predictive coding framework that formulate coordination as the minimization of mutual uncertainty among agents. Instantiated as an information bottleneck objective, it prompts agents to learn not only who and what to communicate but also when. At the foundation of this framework lies a grid-cell-like metric as internal spatial coding for self-localization, emerging spontaneously from self-supervised motion prediction. Building upon this internal spatial code, agents gradually develop a bandwidth-efficient communication mechanism and specialized neural populations that encode partners' locations: an artificial analogue of hippocampal social place cells (SPCs). These social representations are further enacted by a hierarchical reinforcement learning policy that actively explores to reduce joint uncertainty. On the Memory-Maze benchmark, our approach shows exceptional resilience to bandwidth constraints: success degrades gracefully from 73.5% to 64.4% as bandwidth shrinks from 128 to 4 bits/step, whereas a full-broadcast baseline collapses from 67.6% to 28.6%. Our findings establish a theoretically principled and biologically plausible basis for how complex social representations emerge from a unified predictive drive, leading to social collective intelligence.
Diffusion^2: Dual Diffusion Model with Uncertainty-Aware Adaptive Noise for Momentary Trajectory Prediction
Oct 05, 2025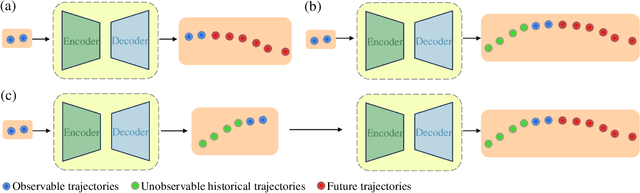
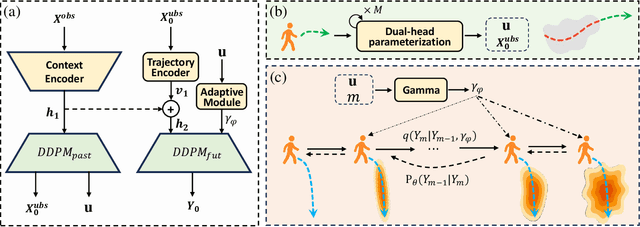
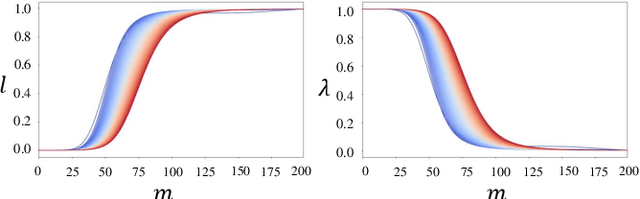
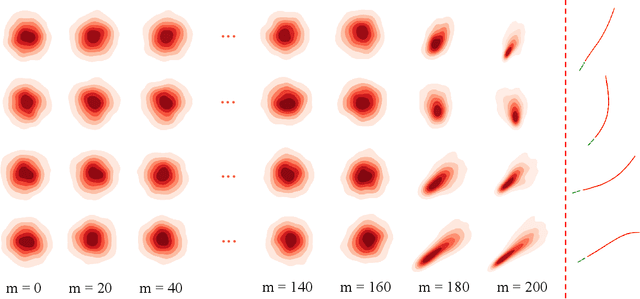
Accurate pedestrian trajectory prediction is crucial for ensuring safety and efficiency in autonomous driving and human-robot interaction scenarios. Earlier studies primarily utilized sufficient observational data to predict future trajectories. However, in real-world scenarios, such as pedestrians suddenly emerging from blind spots, sufficient observational data is often unavailable (i.e. momentary trajectory), making accurate prediction challenging and increasing the risk of traffic accidents. Therefore, advancing research on pedestrian trajectory prediction under extreme scenarios is critical for enhancing traffic safety. In this work, we propose a novel framework termed Diffusion^2, tailored for momentary trajectory prediction. Diffusion^2 consists of two sequentially connected diffusion models: one for backward prediction, which generates unobserved historical trajectories, and the other for forward prediction, which forecasts future trajectories. Given that the generated unobserved historical trajectories may introduce additional noise, we propose a dual-head parameterization mechanism to estimate their aleatoric uncertainty and design a temporally adaptive noise module that dynamically modulates the noise scale in the forward diffusion process. Empirically, Diffusion^2 sets a new state-of-the-art in momentary trajectory prediction on ETH/UCY and Stanford Drone datasets.
ShoulderShot: Generating Over-the-Shoulder Dialogue Videos
Aug 11, 2025



Over-the-shoulder dialogue videos are essential in films, short dramas, and advertisements, providing visual variety and enhancing viewers' emotional connection. Despite their importance, such dialogue scenes remain largely underexplored in video generation research. The main challenges include maintaining character consistency across different shots, creating a sense of spatial continuity, and generating long, multi-turn dialogues within limited computational budgets. Here, we present ShoulderShot, a framework that combines dual-shot generation with looping video, enabling extended dialogues while preserving character consistency. Our results demonstrate capabilities that surpass existing methods in terms of shot-reverse-shot layout, spatial continuity, and flexibility in dialogue length, thereby opening up new possibilities for practical dialogue video generation. Videos and comparisons are available at https://shouldershot.github.io.
Consistent Video Colorization via Palette Guidance
Jan 31, 2025



Colorization is a traditional computer vision task and it plays an important role in many time-consuming tasks, such as old film restoration. Existing methods suffer from unsaturated color and temporally inconsistency. In this paper, we propose a novel pipeline to overcome the challenges. We regard the colorization task as a generative task and introduce Stable Video Diffusion (SVD) as our base model. We design a palette-based color guider to assist the model in generating vivid and consistent colors. The color context introduced by the palette not only provides guidance for color generation, but also enhances the stability of the generated colors through a unified color context across multiple sequences. Experiments demonstrate that the proposed method can provide vivid and stable colors for videos, surpassing previous methods.
GradStop: Exploring Training Dynamics in Unsupervised Outlier Detection through Gradient Cohesion
Dec 11, 2024



Unsupervised Outlier Detection (UOD) is a critical task in data mining and machine learning, aiming to identify instances that significantly deviate from the majority. Without any label, deep UOD methods struggle with the misalignment between the model's direct optimization goal and the final performance goal of Outlier Detection (OD) task. Through the perspective of training dynamics, this paper proposes an early stopping algorithm to optimize the training of deep UOD models, ensuring they perform optimally in OD rather than overfitting the entire contaminated dataset. Inspired by UOD mechanism and inlier priority phenomenon, where intuitively models fit inliers more quickly than outliers, we propose GradStop, a sampling-based label-free algorithm to estimate model's real-time performance during training. First, a sampling method generates two sets: one likely containing more outliers and the other more inliers, then a metric based on gradient cohesion is applied to probe into current training dynamics, which reflects model's performance on OD task. Experimental results on 4 deep UOD algorithms and 47 real-world datasets and theoretical proofs demonstrate the effectiveness of our proposed early stopping algorithm in enhancing the performance of deep UOD models. Auto Encoder (AE) enhanced by GradStop achieves better performance than itself, other SOTA UOD methods, and even ensemble AEs. Our method provides a robust and effective solution to the problem of performance degradation during training, enabling deep UOD models to achieve better potential in anomaly detection tasks.
Seeing Through Pixel Motion: Learning Obstacle Avoidance from Optical Flow with One Camera
Nov 07, 2024



Optical flow captures the motion of pixels in an image sequence over time, providing information about movement, depth, and environmental structure. Flying insects utilize this information to navigate and avoid obstacles, allowing them to execute highly agile maneuvers even in complex environments. Despite its potential, autonomous flying robots have yet to fully leverage this motion information to achieve comparable levels of agility and robustness. Challenges of control from optical flow include extracting accurate optical flow at high speeds, handling noisy estimation, and ensuring robust performance in complex environments. To address these challenges, we propose a novel end-to-end system for quadrotor obstacle avoidance using monocular optical flow. We develop an efficient differentiable simulator coupled with a simplified quadrotor model, allowing our policy to be trained directly through first-order gradient optimization. Additionally, we introduce a central flow attention mechanism and an action-guided active sensing strategy that enhances the policy's focus on task-relevant optical flow observations to enable more responsive decision-making during flight. Our system is validated both in simulation and the real world using an FPV racing drone. Despite being trained in a simple environment in simulation, our system is validated both in simulation and the real world using an FPV racing drone. Despite being trained in a simple environment in simulation, our system demonstrates agile and robust flight in various unknown, cluttered environments in the real world at speeds of up to 6m/s.
Channel-Aware Throughput Maximization for Cooperative Data Fusion in CAV
Oct 06, 2024Connected and autonomous vehicles (CAVs) have garnered significant attention due to their extended perception range and enhanced sensing coverage. To address challenges such as blind spots and obstructions, CAVs employ vehicle-to-vehicle (V2V) communications to aggregate sensory data from surrounding vehicles. However, cooperative perception is often constrained by the limitations of achievable network throughput and channel quality. In this paper, we propose a channel-aware throughput maximization approach to facilitate CAV data fusion, leveraging a self-supervised autoencoder for adaptive data compression. We formulate the problem as a mixed integer programming (MIP) model, which we decompose into two sub-problems to derive optimal data rate and compression ratio solutions under given link conditions. An autoencoder is then trained to minimize bitrate with the determined compression ratio, and a fine-tuning strategy is employed to further reduce spectrum resource consumption. Experimental evaluation on the OpenCOOD platform demonstrates the effectiveness of our proposed algorithm, showing more than 20.19\% improvement in network throughput and a 9.38\% increase in average precision (AP@IoU) compared to state-of-the-art methods, with an optimal latency of 19.99 ms.
Back to Newton's Laws: Learning Vision-based Agile Flight via Differentiable Physics
Jul 16, 2024
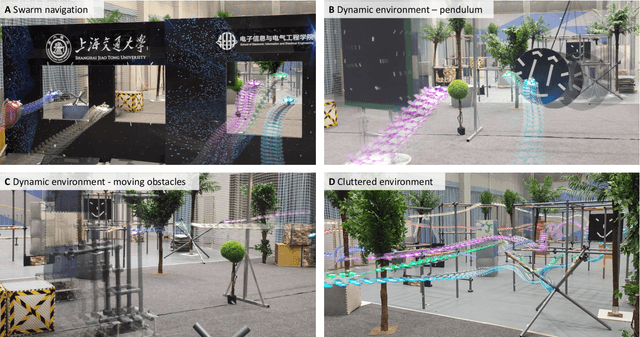
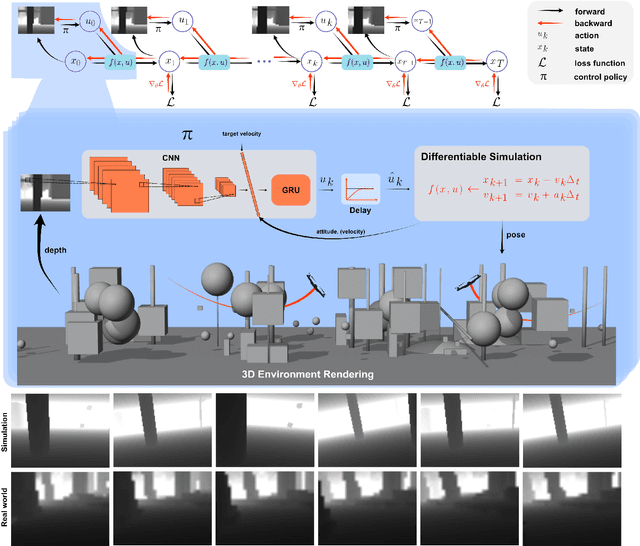
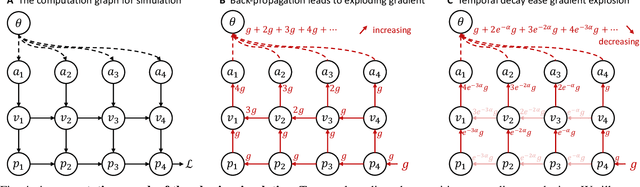
Swarm navigation in cluttered environments is a grand challenge in robotics. This work combines deep learning with first-principle physics through differentiable simulation to enable autonomous navigation of multiple aerial robots through complex environments at high speed. Our approach optimizes a neural network control policy directly by backpropagating loss gradients through the robot simulation using a simple point-mass physics model and a depth rendering engine. Despite this simplicity, our method excels in challenging tasks for both multi-agent and single-agent applications with zero-shot sim-to-real transfer. In multi-agent scenarios, our system demonstrates self-organized behavior, enabling autonomous coordination without communication or centralized planning - an achievement not seen in existing traditional or learning-based methods. In single-agent scenarios, our system achieves a 90% success rate in navigating through complex environments, significantly surpassing the 60% success rate of the previous state-of-the-art approach. Our system can operate without state estimation and adapt to dynamic obstacles. In real-world forest environments, it navigates at speeds up to 20 m/s, doubling the speed of previous imitation learning-based solutions. Notably, all these capabilities are deployed on a budget-friendly $21 computer, costing less than 5% of a GPU-equipped board used in existing systems. Video demonstrations are available at https://youtu.be/LKg9hJqc2cc.