 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Text and Image for Artist Style Transfer via Contrastive Learning
Oct 12, 2024



Image style transfer has attracted widespread attention in the past few years. Despite its remarkable results, it requires additional style images available as references, making it less flexible and inconvenient. Using text is the most natural way to describe the style. More importantly, text can describe implicit abstract styles, like styles of specific artists or art movements. In this paper, we propose a Contrastive Learning for Artistic Style Transfer (CLAST) that leverages advanced image-text encoders to control arbitrary style transfer. We introduce a supervised contrastive training strategy to effectively extract style descriptions from the image-text model (i.e., CLIP), which aligns stylization with the text description. To this end, we also propose a novel and efficient adaLN based state space models that explore style-content fusion. Finally, we achieve a text-driven image style transfer. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods in artistic style transfer. More importantly, it does not require online fine-tuning and can render a 512x512 image in 0.03s.
MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance
Jun 28, 2024



In recent years, generative artificial intelligence has achieved significant advancements in the field of image generation, spawning a variety of applications. However, video generation still faces considerable challenges in various aspects, such as controllability, video length, and richness of details, which hinder the application and popularization of this technology. In this work, we propose a controllable video generation framework, dubbed MimicMotion, which can generate high-quality videos of arbitrary length mimicking specific motion guidance. Compared with previous methods, our approach has several highlights. Firstly, we introduce confidence-aware pose guidance that ensures high frame quality and temporal smoothness. Secondly, we introduce regional loss amplification based on pose confidence, which significantly reduces image distortion. Lastly, for generating long and smooth videos, we propose a progressive latent fusion strategy. By this means, we can produce videos of arbitrary length with acceptable resource consumption. With extensive experiments and user studies, MimicMotion demonstrates significant improvements over previous approaches in various aspects. Detailed results and comparisons are available on our project page: https://tencent.github.io/MimicMotion .
Optimal Coded Diffraction Patterns for Practical Phase Retrieval
Mar 28, 2023Phase retrieval, a long-established challenge for recovering a complex-valued signal from its Fourier intensity measurements, has attracted significant interest because of its far-flung applications in optical imaging. To enhance accuracy, researchers introduce extra constraints to the measuring procedure by including a random aperture mask in the optical path that randomly modulates the light projected on the target object and gives the coded diffraction patterns (CDP). It is known that random masks are non-bandlimited and can lead to considerable high-frequency components in the Fourier intensity measurements. These high-frequency components can be beyond the Nyquist frequency of the optical system and are thus ignored by the phase retrieval optimization algorithms, resulting in degraded reconstruction performances. Recently, our team developed a binary green noise masking scheme that can significantly reduce the high-frequency components in the measurement. However, the scheme cannot be extended to generate multiple-level aperture masks. This paper proposes a two-stage optimization algorithm to generate multi-level random masks named $\textit{OptMask}$ that can also significantly reduce high-frequency components in the measurements but achieve higher accuracy than the binary masking scheme. Extensive experiments on a practical optical platform were conducted. The results demonstrate the superiority and practicality of the proposed $\textit{OptMask}$ over the existing masking schemes for CDP phase retrieval.
Towards Practical Single-shot Phase Retrieval with Physics-Driven Deep Neural Network
Aug 18, 2022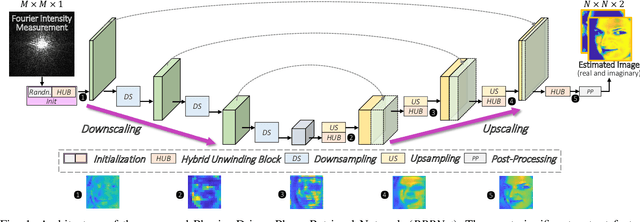

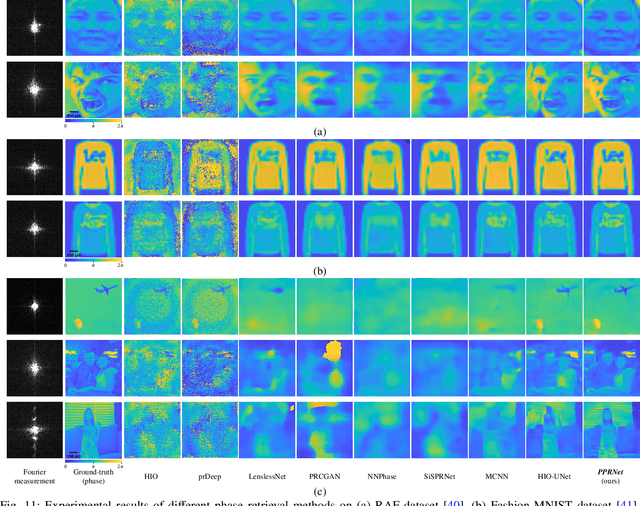
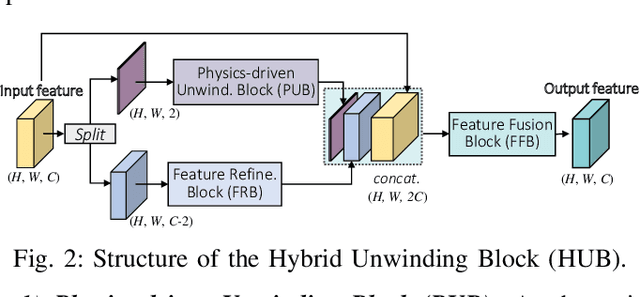
Phase retrieval (PR), a long-established challenge for recovering a complex-valued signal from its Fourier intensity-only measurements, has attracted considerable attention due to its widespread applications in digital imaging. Recently, deep learning-based approaches were developed that achieved some success in single-shot PR. These approaches require a single Fourier intensity measurement without the need to impose any additional constraints on the measured data. Nevertheless, vanilla deep neural networks (DNN) do not give good performance due to the substantial disparity between the input and output domains of the PR problems. Physics-informed approaches try to incorporate the Fourier intensity measurements into an iterative approach to increase the reconstruction accuracy. It, however, requires a lengthy computation process, and the accuracy still cannot be guaranteed. Besides, many of these approaches work on simulation data that ignore some common problems such as saturation and quantization errors in practical optical PR systems. In this paper, a novel physics-driven multi-scale DNN structure dubbed PPRNet is proposed. Similar to other deep learning-based PR methods, PPRNet requires only a single Fourier intensity measurement. It is physics-driven that the network is guided to follow the Fourier intensity measurement at different scales to enhance the reconstruction accuracy. PPRNet has a feedforward structure and can be end-to-end trained. Thus, it is much faster and more accurate than the traditional physics-driven PR approaches. Extensive simulations and experiments on a practical optical platform were conducted. The results demonstrate the superiority and practicality of the proposed PPRNet over the traditional learning-based PR methods.
SiPRNet: End-to-End Learning for Single-Shot Phase Retrieval
May 23, 2022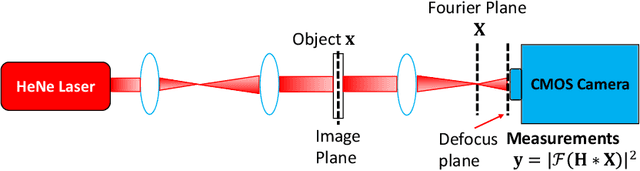
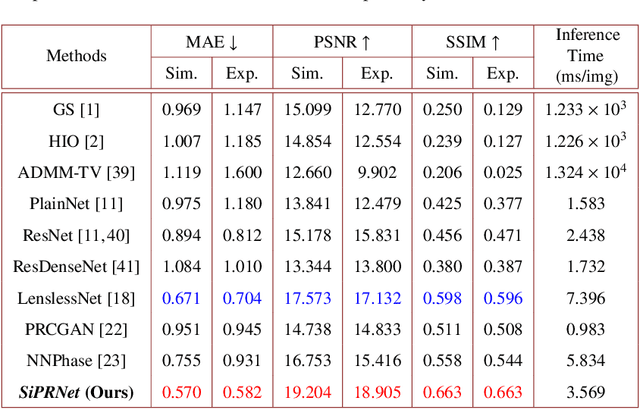
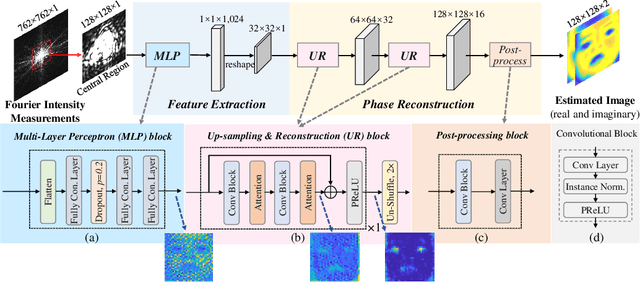
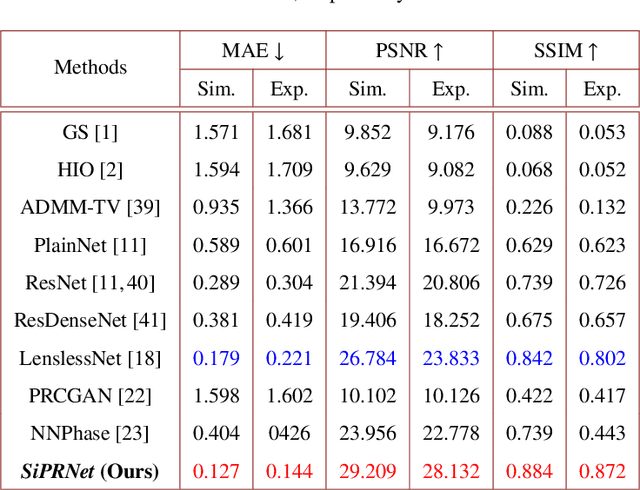
Traditional optimization algorithms have been developed to deal with the phase retrieval problem. However, multiple measurements with different random or non-random masks are needed for giving a satisfactory performance. This brings a burden to the implementation of the algorithms in practical systems. Even worse, expensive optical devices are required to implement the optical masks. Recently, deep learning, especially convolutional neural networks (CNN), has played important roles in various image reconstruction tasks. However, traditional CNN structure fails to reconstruct the original images from their Fourier measurements because of tremendous domain discrepancy. In this paper, we design a novel CNN structure, named SiPRNet, to recover a signal from a single Fourier intensity measurement. To effectively utilize the spectral information of the measurements, we propose a new Multi-Layer Perception block embedded with the dropout layer to extract the global representations. Two Up-sampling and Reconstruction blocks with self-attention are utilized to recover the signals from the extracted features. Extensive evaluations of the proposed model are performed using different testing datasets on both simulation and optical experimentation platforms. The results demonstrate that the proposed approach consistently outperforms other CNN-based and traditional optimization-based methods in single-shot maskless phase retrieval. The source codes of the proposed method have been released on Github: https://github.com/Qiustander/SiPRNet.
Name Your Style: An Arbitrary Artist-aware Image Style Transfer
Mar 05, 2022
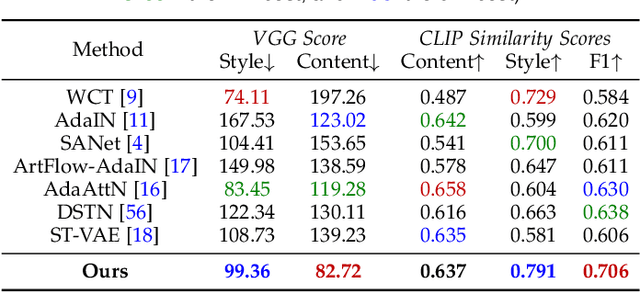
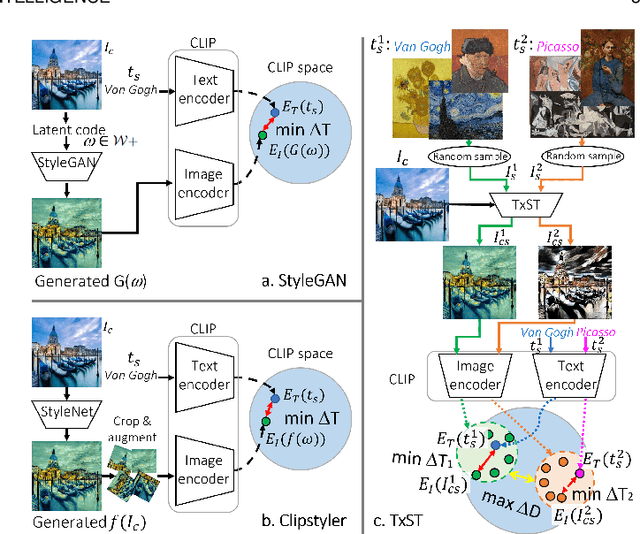
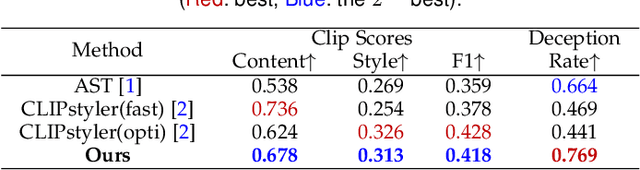
Image style transfer has attracted widespread attention in the past few years. Despite its remarkable results, it requires additional style images available as references, making it less flexible and inconvenient. Using text is the most natural way to describe the style. More importantly, text can describe implicit abstract styles, like styles of specific artists or art movements. In this paper, we propose a text-driven image style transfer (TxST) that leverages advanced image-text encoders to control arbitrary style transfer. We introduce a contrastive training strategy to effectively extract style descriptions from the image-text model (i.e., CLIP), which aligns stylization with the text description. To this end, we also propose a novel and efficient attention module that explores cross-attentions to fuse style and content features. Finally, we achieve an arbitrary artist-aware image style transfer to learn and transfer specific artistic characters such as Picasso, oil painting, or a rough sketch. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods on both image and textual styles. Moreover, it can mimic the styles of one or many artists to achieve attractive results, thus highlighting a promising direction in image style transfer.
Variational AutoEncoder for Reference based Image Super-Resolution
Jun 08, 2021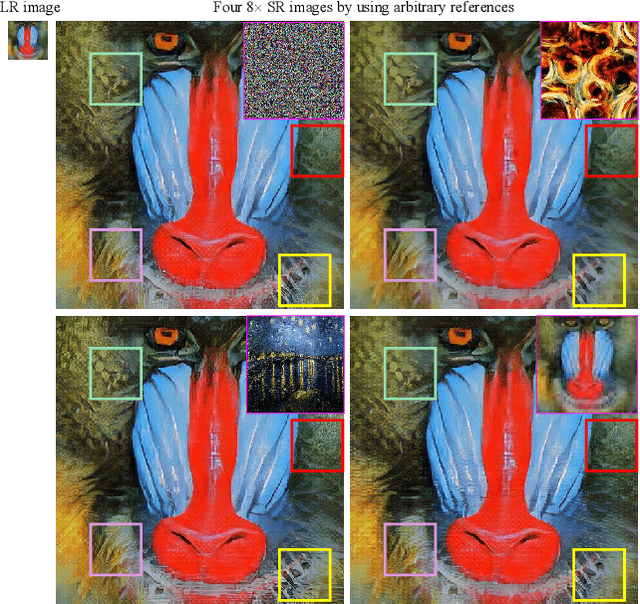

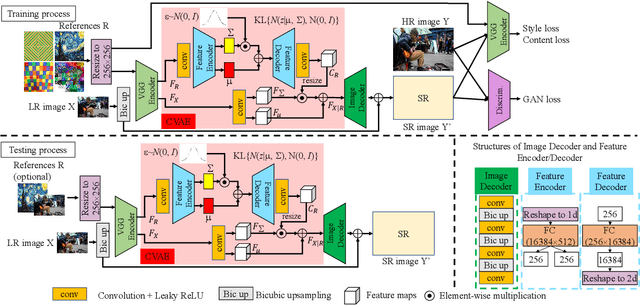
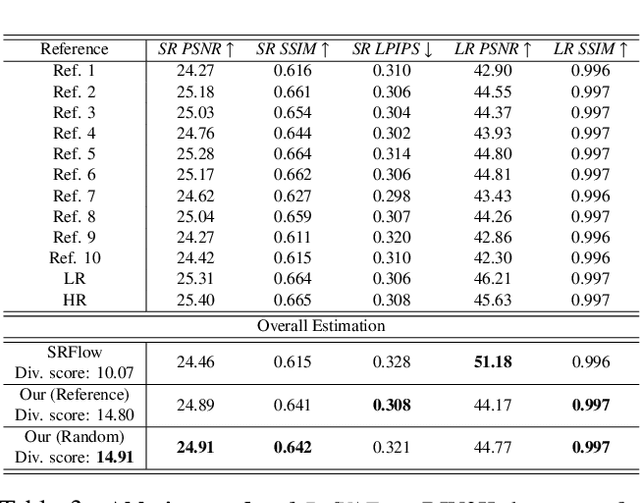
In this paper, we propose a novel reference based image super-resolution approach via Variational AutoEncoder (RefVAE). Existing state-of-the-art methods mainly focus on single image super-resolution which cannot perform well on large upsampling factors, e.g., 8$\times$. We propose a reference based image super-resolution, for which any arbitrary image can act as a reference for super-resolution. Even using random map or low-resolution image itself, the proposed RefVAE can transfer the knowledge from the reference to the super-resolved images. Depending upon different references, the proposed method can generate different versions of super-resolved images from a hidden super-resolution space. Besides using different datasets for some standard evaluations with PSNR and SSIM, we also took part in the NTIRE2021 SR Space challenge and have provided results of the randomness evaluation of our approach. Compared to other state-of-the-art methods, our approach achieves higher diverse scores.
* 10 pages, 6 figures
Bone Feature Segmentation in Ultrasound Spine Image with Robustness to Speckle and Regular Occlusion Noise
Oct 08, 2020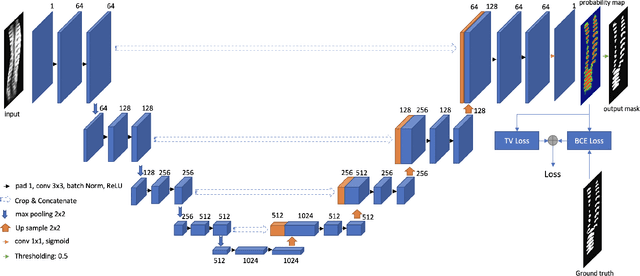
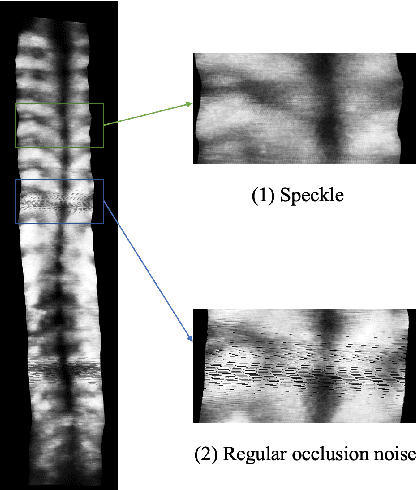

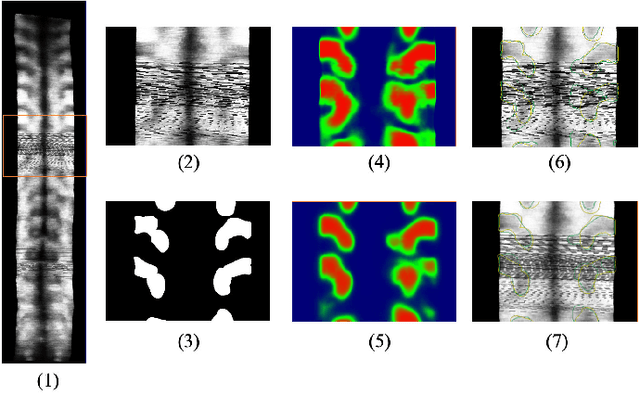
3D ultrasound imaging shows great promise for scoliosis diagnosis thanks to its low-costing, radiation-free and real-time characteristics. The key to accessing scoliosis by ultrasound imaging is to accurately segment the bone area and measure the scoliosis degree based on the symmetry of the bone features. The ultrasound images tend to contain many speckles and regular occlusion noise which is difficult, tedious and time-consuming for experts to find out the bony feature. In this paper, we propose a robust bone feature segmentation method based on the U-net structure for ultrasound spine Volume Projection Imaging (VPI) images. The proposed segmentation method introduces a total variance loss to reduce the sensitivity of the model to small-scale and regular occlusion noise. The proposed approach improves 2.3% of Dice score and 1% of AUC score as compared with the u-net model and shows high robustness to speckle and regular occlusion noise.
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020

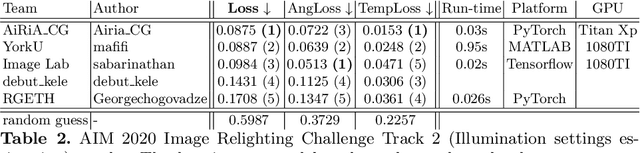

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020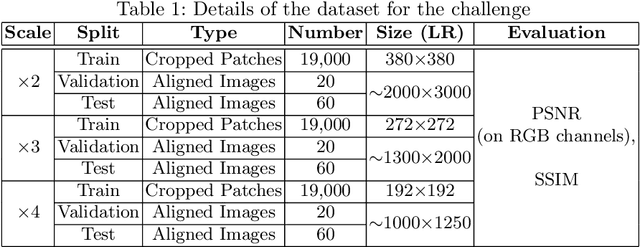
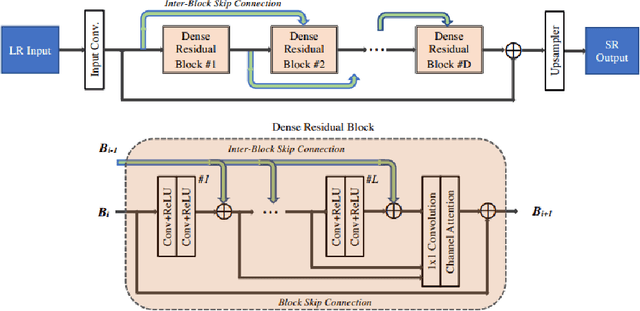
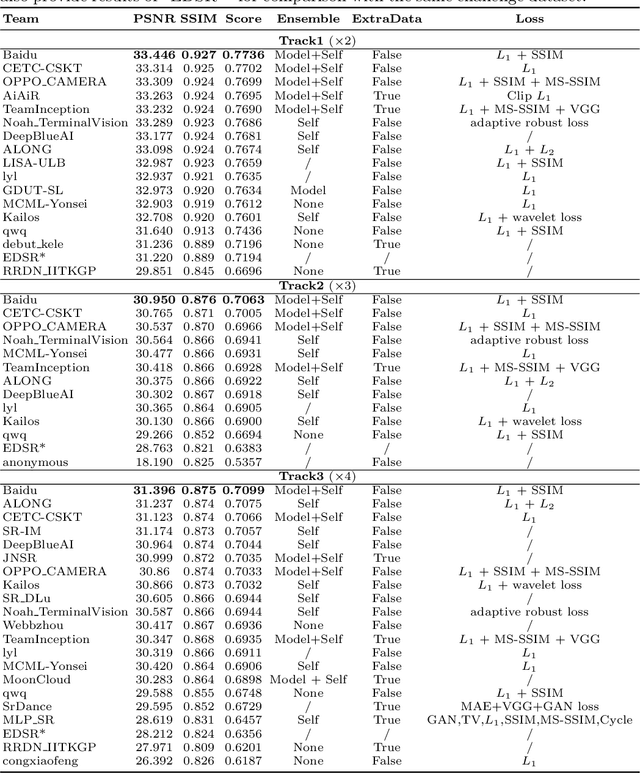
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.