 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion of Various Optimization Based Feature Smoothing Methods for Wearable and Non-invasive Blood Glucose Estimation
Mar 06, 2025



Recently, the wearable and non-invasive blood glucose estimation approach has been proposed. However, due to the unreliability of the acquisition device, the presence of the noise and the variations of the acquisition environments, the obtained features and the reference blood glucose values are highly unreliable. To address this issue, this paper proposes a polynomial fitting approach to smooth the obtained features or the reference blood glucose values. First, the blood glucose values are estimated based on the individual optimization approaches. Second, the absolute difference values between the estimated blood glucose values and the actual blood glucose values based on each optimization approach are computed. Third, these absolute difference values for each optimization approach are sorted in the ascending order. Fourth, for each sorted blood glucose value, the optimization method corresponding to the minimum absolute difference value is selected. Fifth, the accumulate probability of each selected optimization method is computed. If the accumulate probability of any selected optimization method at a point is greater than a threshold value, then the accumulate probabilities of these three selected optimization methods at that point are reset to zero. A range of the sorted blood glucose values are defined as that with the corresponding boundaries points being the previous reset point and this reset point. Hence, after performing the above procedures for all the sorted reference blood glucose values in the validation set, the regions of the sorted reference blood glucose values and the corresponding optimization methods in these regions are determined. The computer numerical simulation results show that our proposed method yields the mean absolute relative deviation (MARD) at 0.0930 and the percentage of the test data falling in the zone A of the Clarke error grid at 94.1176%.
* This version corrects several typos
Optimal Coded Diffraction Patterns for Practical Phase Retrieval
Mar 28, 2023Phase retrieval, a long-established challenge for recovering a complex-valued signal from its Fourier intensity measurements, has attracted significant interest because of its far-flung applications in optical imaging. To enhance accuracy, researchers introduce extra constraints to the measuring procedure by including a random aperture mask in the optical path that randomly modulates the light projected on the target object and gives the coded diffraction patterns (CDP). It is known that random masks are non-bandlimited and can lead to considerable high-frequency components in the Fourier intensity measurements. These high-frequency components can be beyond the Nyquist frequency of the optical system and are thus ignored by the phase retrieval optimization algorithms, resulting in degraded reconstruction performances. Recently, our team developed a binary green noise masking scheme that can significantly reduce the high-frequency components in the measurement. However, the scheme cannot be extended to generate multiple-level aperture masks. This paper proposes a two-stage optimization algorithm to generate multi-level random masks named $\textit{OptMask}$ that can also significantly reduce high-frequency components in the measurements but achieve higher accuracy than the binary masking scheme. Extensive experiments on a practical optical platform were conducted. The results demonstrate the superiority and practicality of the proposed $\textit{OptMask}$ over the existing masking schemes for CDP phase retrieval.
Hybrid Low-order and Higher-order Graph Convolutional Networks
Aug 02, 2019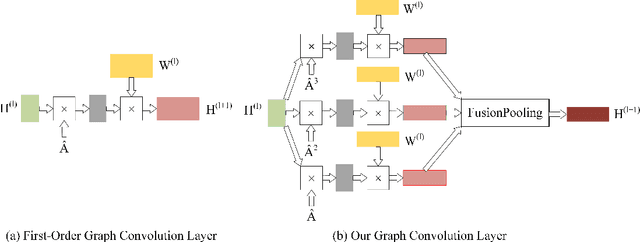
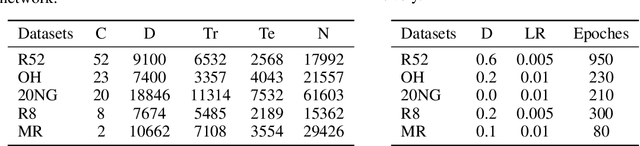
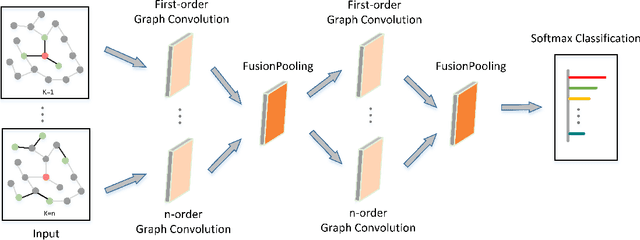
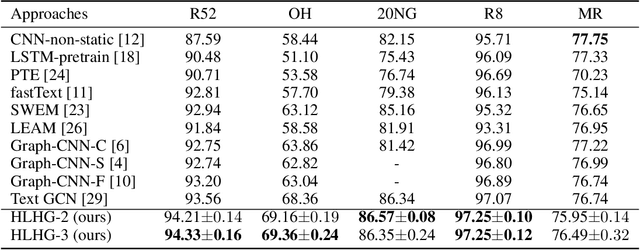
With higher-order neighborhood information of graph network, the accuracy of graph representation learning classification can be significantly improved. However, the current higher order graph convolutional network has a large number of parameters and high computational complexity. Therefore, we propose a Hybrid Lower order and Higher order Graph convolutional networks (HLHG) learning model, which uses weight sharing mechanism to reduce the number of network parameters. To reduce computational complexity, we propose a novel fusion pooling layer to combine the neighborhood information of high order and low order. Theoretically, we compare the model complexity of the proposed model with the other state-of-the-art model. Experimentally, we verify the proposed model on the large-scale text network datasets by supervised learning, and on the citation network datasets by semi-supervised learning. The experimental results show that the proposed model achieves highest classification accuracy with a small set of trainable weight parameters.