 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusDreamer: Label-efficient Remote Sensing World Model for Multimodal Data Classification
Mar 18, 2025World models significantly enhance hierarchical understanding, improving data integration and learning efficiency. To explore the potential of the world model in the remote sensing (RS) field, this paper proposes a label-efficient remote sensing world model for multimodal data fusion (FusDreamer). The FusDreamer uses the world model as a unified representation container to abstract common and high-level knowledge, promoting interactions across different types of data, \emph{i.e.}, hyperspectral (HSI), light detection and ranging (LiDAR), and text data. Initially, a new latent diffusion fusion and multimodal generation paradigm (LaMG) is utilized for its exceptional information integration and detail retention capabilities. Subsequently, an open-world knowledge-guided consistency projection (OK-CP) module incorporates prompt representations for visually described objects and aligns language-visual features through contrastive learning. In this way, the domain gap can be bridged by fine-tuning the pre-trained world models with limited samples. Finally, an end-to-end multitask combinatorial optimization (MuCO) strategy can capture slight feature bias and constrain the diffusion process in a collaboratively learnable direction. Experiments conducted on four typical datasets indicate the effectiveness and advantages of the proposed FusDreamer. The corresponding code will be released at https://github.com/Cimy-wang/FusDreamer.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024



This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
Gene-Metabolite Association Prediction with Interactive Knowledge Transfer Enhanced Graph for Metabolite Production
Oct 24, 2024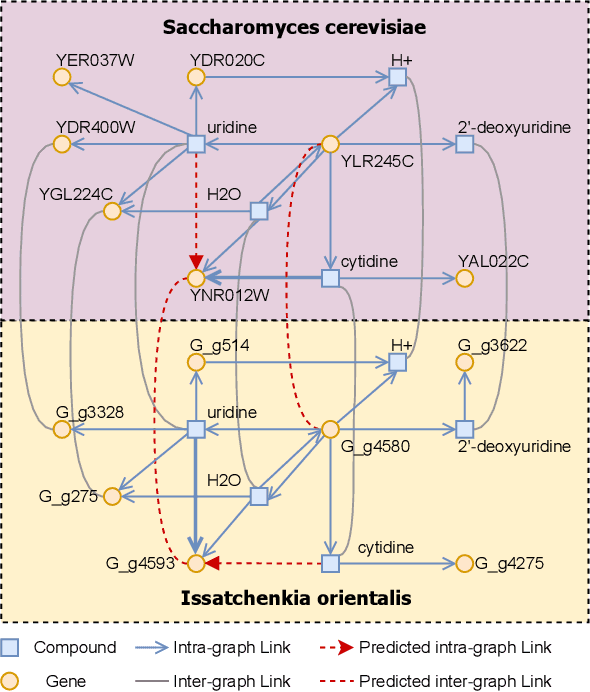
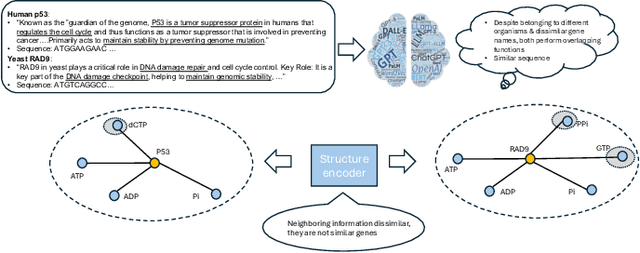
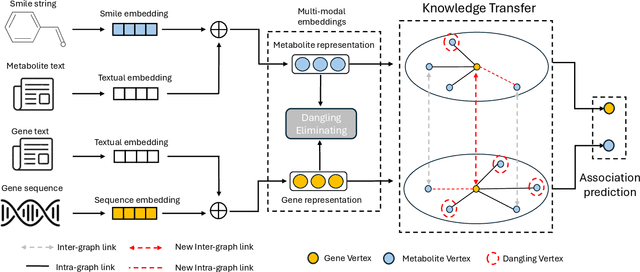
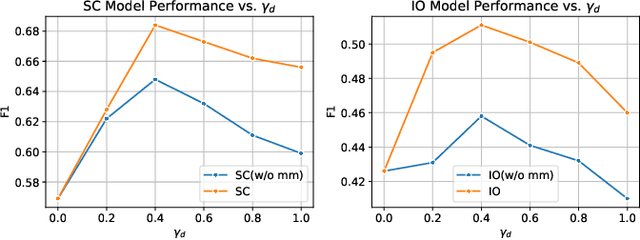
In the rapidly evolving field of metabolic engineering, the quest for efficient and precise gene target identification for metabolite production enhancement presents significant challenges. Traditional approaches, whether knowledge-based or model-based, are notably time-consuming and labor-intensive, due to the vast scale of research literature and the approximation nature of genome-scale metabolic model (GEM) simulations. Therefore, we propose a new task, Gene-Metabolite Association Prediction based on metabolic graphs, to automate the process of candidate gene discovery for a given pair of metabolite and candidate-associated genes, as well as presenting the first benchmark containing 2474 metabolites and 1947 genes of two commonly used microorganisms Saccharomyces cerevisiae (SC) and Issatchenkia orientalis (IO). This task is challenging due to the incompleteness of the metabolic graphs and the heterogeneity among distinct metabolisms. To overcome these limitations, we propose an Interactive Knowledge Transfer mechanism based on Metabolism Graph (IKT4Meta), which improves the association prediction accuracy by integrating the knowledge from different metabolism graphs. First, to build a bridge between two graphs for knowledge transfer, we utilize Pretrained Language Models (PLMs) with external knowledge of genes and metabolites to help generate inter-graph links, significantly alleviating the impact of heterogeneity. Second, we propagate intra-graph links from different metabolic graphs using inter-graph links as anchors. Finally, we conduct the gene-metabolite association prediction based on the enriched metabolism graphs, which integrate the knowledge from multiple microorganisms. Experiments on both types of organisms demonstrate that our proposed methodology outperforms baselines by up to 12.3% across various link prediction frameworks.
CMAB: A First National-Scale Multi-Attribute Building Dataset Derived from Open Source Data and GeoAI
Aug 12, 2024



Rapidly acquiring three-dimensional (3D) building data, including geometric attributes like rooftop, height, and structure, as well as indicative attributes like function, quality, and age, is essential for accurate urban analysis, simulations, and policy updates. Existing large-scale building datasets lack accuracy, extensibility and indicative attributes. This paper presents a geospatial artificial intelligence (GeoAI) framework for large-scale building modeling, introducing the first Multi-Attribute Building dataset (CMAB) in China at a national scale. The dataset covers 3,667 natural cities with a total rooftop area of 21.3 billion square meters with an F1-Score of 89.93% in rooftop extraction through the OCRNet. We trained bootstrap aggregated XGBoost models with city administrative classifications, incorporating building features such as morphology, location, and function. Using multi-source data, including billions of high-resolution Google Earth imagery and 60 million street view images (SVI), we generated rooftop, height, function, age, and quality attributes for each building. Accuracy was validated through model benchmarks, existing similar products, and manual SVI validation. The results support urban planning and sustainable development.
Chem-FINESE: Validating Fine-Grained Few-shot Entity Extraction through Text Reconstruction
Jan 25, 2024Fine-grained few-shot entity extraction in the chemical domain faces two unique challenges. First, compared with entity extraction tasks in the general domain, sentences from chemical papers usually contain more entities. Moreover, entity extraction models usually have difficulty extracting entities of long-tailed types. In this paper, we propose Chem-FINESE, a novel sequence-to-sequence (seq2seq) based few-shot entity extraction approach, to address these two challenges. Our Chem-FINESE has two components: a seq2seq entity extractor to extract named entities from the input sentence and a seq2seq self-validation module to reconstruct the original input sentence from extracted entities. Inspired by the fact that a good entity extraction system needs to extract entities faithfully, our new self-validation module leverages entity extraction results to reconstruct the original input sentence. Besides, we design a new contrastive loss to reduce excessive copying during the extraction process. Finally, we release ChemNER+, a new fine-grained chemical entity extraction dataset that is annotated by domain experts with the ChemNER schema. Experiments in few-shot settings with both ChemNER+ and CHEMET datasets show that our newly proposed framework has contributed up to 8.26% and 6.84% absolute F1-score gains respectively.
Hybrid Low-order and Higher-order Graph Convolutional Networks
Aug 02, 2019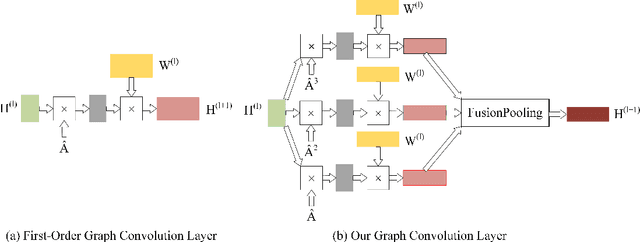
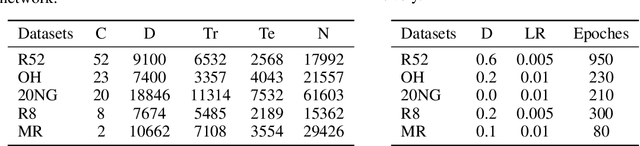
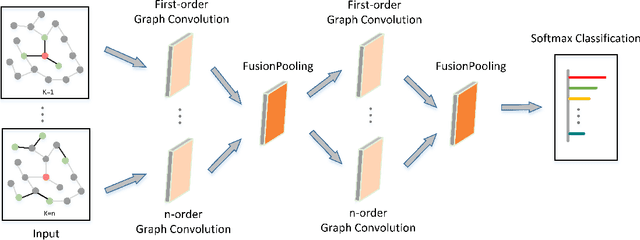
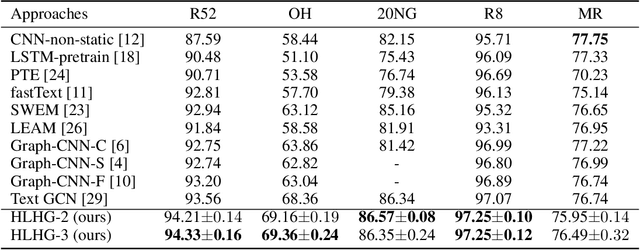
With higher-order neighborhood information of graph network, the accuracy of graph representation learning classification can be significantly improved. However, the current higher order graph convolutional network has a large number of parameters and high computational complexity. Therefore, we propose a Hybrid Lower order and Higher order Graph convolutional networks (HLHG) learning model, which uses weight sharing mechanism to reduce the number of network parameters. To reduce computational complexity, we propose a novel fusion pooling layer to combine the neighborhood information of high order and low order. Theoretically, we compare the model complexity of the proposed model with the other state-of-the-art model. Experimentally, we verify the proposed model on the large-scale text network datasets by supervised learning, and on the citation network datasets by semi-supervised learning. The experimental results show that the proposed model achieves highest classification accuracy with a small set of trainable weight parameters.