 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport for NSF Workshop on AI for Electronic Design Automation
Jan 20, 2026This report distills the discussions and recommendations from the NSF Workshop on AI for Electronic Design Automation (EDA), held on December 10, 2024 in Vancouver alongside NeurIPS 2024. Bringing together experts across machine learning and EDA, the workshop examined how AI-spanning large language models (LLMs), graph neural networks (GNNs), reinforcement learning (RL), neurosymbolic methods, etc.-can facilitate EDA and shorten design turnaround. The workshop includes four themes: (1) AI for physical synthesis and design for manufacturing (DFM), discussing challenges in physical manufacturing process and potential AI applications; (2) AI for high-level and logic-level synthesis (HLS/LLS), covering pragma insertion, program transformation, RTL code generation, etc.; (3) AI toolbox for optimization and design, discussing frontier AI developments that could potentially be applied to EDA tasks; and (4) AI for test and verification, including LLM-assisted verification tools, ML-augmented SAT solving, security/reliability challenges, etc. The report recommends NSF to foster AI/EDA collaboration, invest in foundational AI for EDA, develop robust data infrastructures, promote scalable compute infrastructure, and invest in workforce development to democratize hardware design and enable next-generation hardware systems. The workshop information can be found on the website https://ai4eda-workshop.github.io/.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
JAM: Controllable and Responsible Text Generation via Causal Reasoning and Latent Vector Manipulation
Feb 28, 2025



While large language models (LLMs) have made significant strides in generating coherent and contextually relevant text, they often function as opaque black boxes, trained on vast unlabeled datasets with statistical objectives, lacking an interpretable framework for responsible control. In this paper, we introduce JAM (Just A Move), a novel framework that interprets and controls text generation by integrating cause-effect analysis within the latent space of LLMs. Based on our observations, we uncover the inherent causality in LLM generation, which is critical for producing responsible and realistic outputs. Moreover, we explore latent vectors as fundamental components in LLM architectures, aiming to understand and manipulate them for more effective and efficient controllable text generation. We evaluate our framework using a range of tools, including the HHH criteria, toxicity reduction benchmarks, and GPT-4 alignment measures. Our results show that JAM achieves up to a 22% improvement over previous Controllable Text Generation (CTG) methods across multiple quantitative metrics and human-centric evaluations. Furthermore, JAM demonstrates greater computational efficiency compared to other CTG methods. These results highlight the effectiveness and efficiency of JAM for responsible and realistic text generation, paving the way for more interpretable and controllable models.
Large Language Model Strategic Reasoning Evaluation through Behavioral Game Theory
Feb 27, 2025Strategic decision-making involves interactive reasoning where agents adapt their choices in response to others, yet existing evaluations of large language models (LLMs) often emphasize Nash Equilibrium (NE) approximation, overlooking the mechanisms driving their strategic choices. To bridge this gap, we introduce an evaluation framework grounded in behavioral game theory, disentangling reasoning capability from contextual effects. Testing 22 state-of-the-art LLMs, we find that GPT-o3-mini, GPT-o1, and DeepSeek-R1 dominate most games yet also demonstrate that the model scale alone does not determine performance. In terms of prompting enhancement, Chain-of-Thought (CoT) prompting is not universally effective, as it increases strategic reasoning only for models at certain levels while providing limited gains elsewhere. Additionally, we investigate the impact of encoded demographic features on the models, observing that certain assignments impact the decision-making pattern. For instance, GPT-4o shows stronger strategic reasoning with female traits than males, while Gemma assigns higher reasoning levels to heterosexual identities compared to other sexual orientations, indicating inherent biases. These findings underscore the need for ethical standards and contextual alignment to balance improved reasoning with fairness.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024



This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
New Solutions on LLM Acceleration, Optimization, and Application
Jun 16, 2024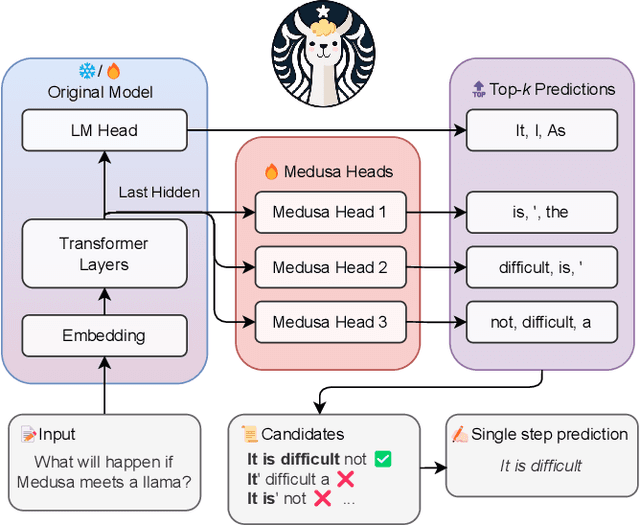
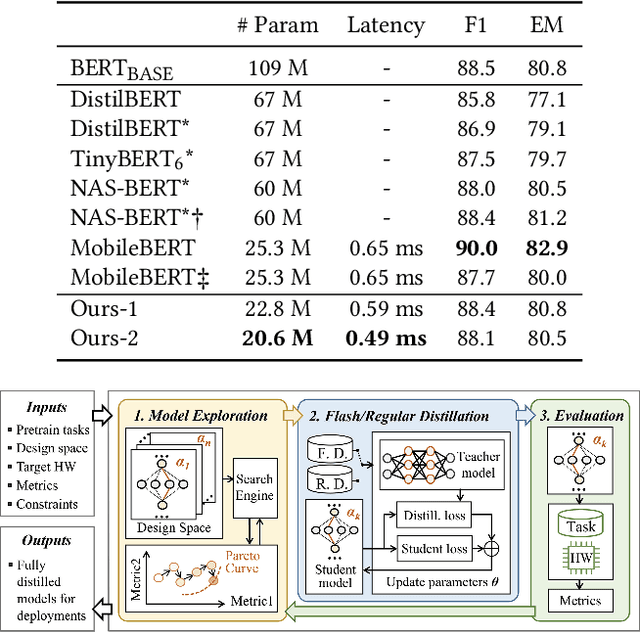
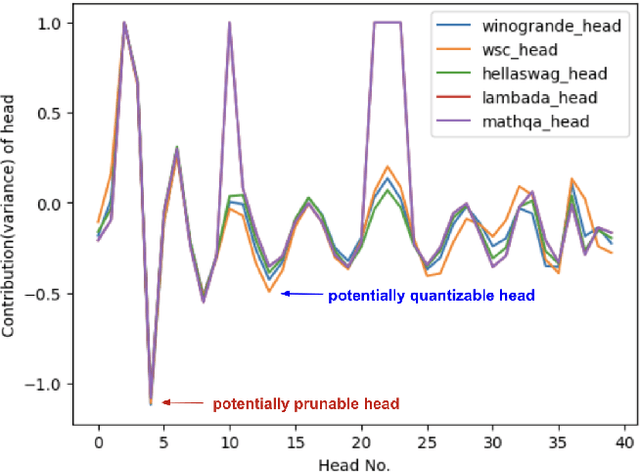
Large Language Models (LLMs) have become extremely potent instruments with exceptional capacities for comprehending and producing human-like text in a wide range of applications. However, the increasing size and complexity of LLMs present significant challenges in both training and deployment, leading to substantial computational and storage costs as well as heightened energy consumption. In this paper, we provide a review of recent advancements and research directions aimed at addressing these challenges and enhancing the efficiency of LLM-based systems. We begin by discussing algorithm-level acceleration techniques focused on optimizing LLM inference speed and resource utilization. We also explore LLM-hardware co-design strategies with a vision to improve system efficiency by tailoring hardware architectures to LLM requirements. Further, we delve into LLM-to-accelerator compilation approaches, which involve customizing hardware accelerators for efficient LLM deployment. Finally, as a case study to leverage LLMs for assisting circuit design, we examine LLM-aided design methodologies for an important task: High-Level Synthesis (HLS) functional verification, by creating a new dataset that contains a large number of buggy and bug-free codes, which can be essential for training LLMs to specialize on HLS verification and debugging. For each aspect mentioned above, we begin with a detailed background study, followed by the presentation of several novel solutions proposed to overcome specific challenges. We then outline future research directions to drive further advancements. Through these efforts, we aim to pave the way for more efficient and scalable deployment of LLMs across a diverse range of applications.
Decision-Making Behavior Evaluation Framework for LLMs under Uncertain Context
Jun 10, 2024



When making decisions under uncertainty, individuals often deviate from rational behavior, which can be evaluated across three dimensions: risk preference, probability weighting, and loss aversion. Given the widespread use of large language models (LLMs) in decision-making processes, it is crucial to assess whether their behavior aligns with human norms and ethical expectations or exhibits potential biases. Several empirical studies have investigated the rationality and social behavior performance of LLMs, yet their internal decision-making tendencies and capabilities remain inadequately understood. This paper proposes a framework, grounded in behavioral economics, to evaluate the decision-making behaviors of LLMs. Through a multiple-choice-list experiment, we estimate the degree of risk preference, probability weighting, and loss aversion in a context-free setting for three commercial LLMs: ChatGPT-4.0-Turbo, Claude-3-Opus, and Gemini-1.0-pro. Our results reveal that LLMs generally exhibit patterns similar to humans, such as risk aversion and loss aversion, with a tendency to overweight small probabilities. However, there are significant variations in the degree to which these behaviors are expressed across different LLMs. We also explore their behavior when embedded with socio-demographic features, uncovering significant disparities. For instance, when modeled with attributes of sexual minority groups or physical disabilities, Claude-3-Opus displays increased risk aversion, leading to more conservative choices. These findings underscore the need for careful consideration of the ethical implications and potential biases in deploying LLMs in decision-making scenarios. Therefore, this study advocates for developing standards and guidelines to ensure that LLMs operate within ethical boundaries while enhancing their utility in complex decision-making environments.
SnapKV: LLM Knows What You are Looking for Before Generation
Apr 22, 2024



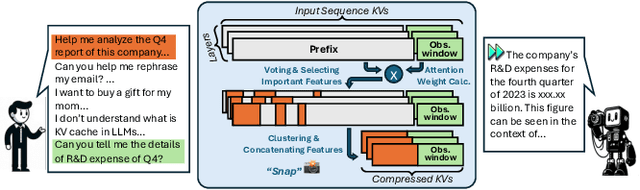
Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications. We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an `observation' window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV's potential for practical applications.
On the Surprising Efficacy of Distillation as an Alternative to Pre-Training Small Models
Apr 04, 2024



In this paper, we propose that small models may not need to absorb the cost of pre-training to reap its benefits. Instead, they can capitalize on the astonishing results achieved by modern, enormous models to a surprising degree. We observe that, when distilled on a task from a pre-trained teacher model, a small model can achieve or surpass the performance it would achieve if it was pre-trained then finetuned on that task. To allow this phenomenon to be easily leveraged, we establish a connection reducing knowledge distillation to modern contrastive learning, opening two doors: (1) vastly different model architecture pairings can work for the distillation, and (2) most contrastive learning algorithms rooted in the theory of Noise Contrastive Estimation can be easily applied and used. We demonstrate this paradigm using pre-trained teacher models from open-source model hubs, Transformer and convolution based model combinations, and a novel distillation algorithm that massages the Alignment/Uniformity perspective of contrastive learning by Wang & Isola (2020) into a distillation objective. We choose this flavor of contrastive learning due to its low computational cost, an overarching theme of this work. We also observe that this phenomenon tends not to occur if the task is data-limited. However, this can be alleviated by leveraging yet another scale-inspired development: large, pre-trained generative models for dataset augmentation. Again, we use an open-source model, and our rudimentary prompts are sufficient to boost the small model`s performance. Thus, we highlight a training method for small models that is up to 94% faster than the standard pre-training paradigm without sacrificing performance. For practitioners discouraged from fully utilizing modern foundation datasets for their small models due to the prohibitive scale, we believe our work keeps that door open.
FedCore: Straggler-Free Federated Learning with Distributed Coresets
Jan 31, 2024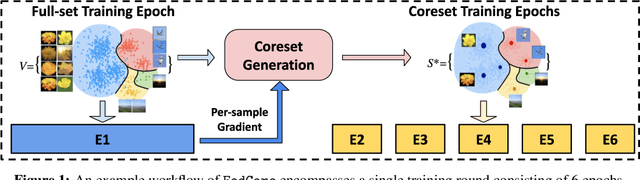

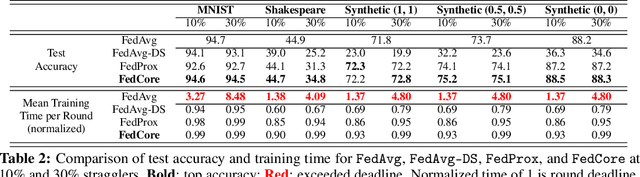
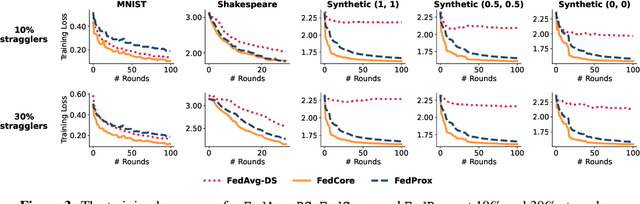
Federated learning (FL) is a machine learning paradigm that allows multiple clients to collaboratively train a shared model while keeping their data on-premise. However, the straggler issue, due to slow clients, often hinders the efficiency and scalability of FL. This paper presents FedCore, an algorithm that innovatively tackles the straggler problem via the decentralized selection of coresets, representative subsets of a dataset. Contrary to existing centralized coreset methods, FedCore creates coresets directly on each client in a distributed manner, ensuring privacy preservation in FL. FedCore translates the coreset optimization problem into a more tractable k-medoids clustering problem and operates distributedly on each client. Theoretical analysis confirms FedCore's convergence, and practical evaluations demonstrate an 8x reduction in FL training time, without compromising model accuracy. Our extensive evaluations also show that FedCore generalizes well to existing FL frameworks.