 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJAM: Controllable and Responsible Text Generation via Causal Reasoning and Latent Vector Manipulation
Feb 28, 2025



While large language models (LLMs) have made significant strides in generating coherent and contextually relevant text, they often function as opaque black boxes, trained on vast unlabeled datasets with statistical objectives, lacking an interpretable framework for responsible control. In this paper, we introduce JAM (Just A Move), a novel framework that interprets and controls text generation by integrating cause-effect analysis within the latent space of LLMs. Based on our observations, we uncover the inherent causality in LLM generation, which is critical for producing responsible and realistic outputs. Moreover, we explore latent vectors as fundamental components in LLM architectures, aiming to understand and manipulate them for more effective and efficient controllable text generation. We evaluate our framework using a range of tools, including the HHH criteria, toxicity reduction benchmarks, and GPT-4 alignment measures. Our results show that JAM achieves up to a 22% improvement over previous Controllable Text Generation (CTG) methods across multiple quantitative metrics and human-centric evaluations. Furthermore, JAM demonstrates greater computational efficiency compared to other CTG methods. These results highlight the effectiveness and efficiency of JAM for responsible and realistic text generation, paving the way for more interpretable and controllable models.
New Solutions on LLM Acceleration, Optimization, and Application
Jun 16, 2024
Large Language Models (LLMs) have become extremely potent instruments with exceptional capacities for comprehending and producing human-like text in a wide range of applications. However, the increasing size and complexity of LLMs present significant challenges in both training and deployment, leading to substantial computational and storage costs as well as heightened energy consumption. In this paper, we provide a review of recent advancements and research directions aimed at addressing these challenges and enhancing the efficiency of LLM-based systems. We begin by discussing algorithm-level acceleration techniques focused on optimizing LLM inference speed and resource utilization. We also explore LLM-hardware co-design strategies with a vision to improve system efficiency by tailoring hardware architectures to LLM requirements. Further, we delve into LLM-to-accelerator compilation approaches, which involve customizing hardware accelerators for efficient LLM deployment. Finally, as a case study to leverage LLMs for assisting circuit design, we examine LLM-aided design methodologies for an important task: High-Level Synthesis (HLS) functional verification, by creating a new dataset that contains a large number of buggy and bug-free codes, which can be essential for training LLMs to specialize on HLS verification and debugging. For each aspect mentioned above, we begin with a detailed background study, followed by the presentation of several novel solutions proposed to overcome specific challenges. We then outline future research directions to drive further advancements. Through these efforts, we aim to pave the way for more efficient and scalable deployment of LLMs across a diverse range of applications.
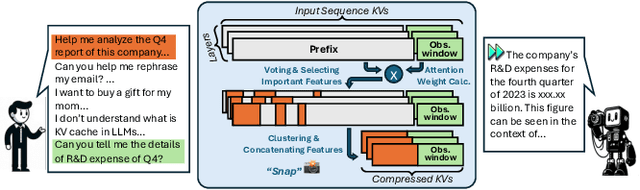
SnapKV: LLM Knows What You are Looking for Before Generation
Apr 22, 2024



Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications. We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an `observation' window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV's potential for practical applications.
Adversarial Imitation Learning via Boosting
Apr 12, 2024
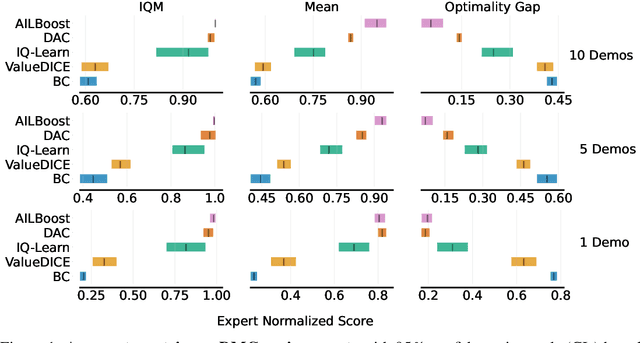
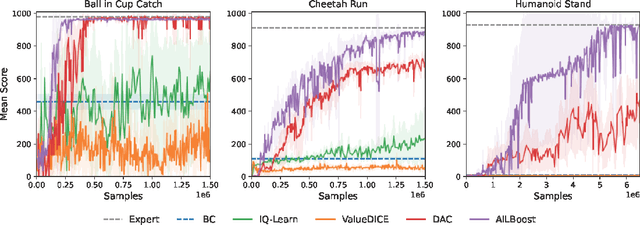

Adversarial imitation learning (AIL) has stood out as a dominant framework across various imitation learning (IL) applications, with Discriminator Actor Critic (DAC) (Kostrikov et al.,, 2019) demonstrating the effectiveness of off-policy learning algorithms in improving sample efficiency and scalability to higher-dimensional observations. Despite DAC's empirical success, the original AIL objective is on-policy and DAC's ad-hoc application of off-policy training does not guarantee successful imitation (Kostrikov et al., 2019; 2020). Follow-up work such as ValueDICE (Kostrikov et al., 2020) tackles this issue by deriving a fully off-policy AIL objective. Instead in this work, we develop a novel and principled AIL algorithm via the framework of boosting. Like boosting, our new algorithm, AILBoost, maintains an ensemble of properly weighted weak learners (i.e., policies) and trains a discriminator that witnesses the maximum discrepancy between the distributions of the ensemble and the expert policy. We maintain a weighted replay buffer to represent the state-action distribution induced by the ensemble, allowing us to train discriminators using the entire data collected so far. In the weighted replay buffer, the contribution of the data from older policies are properly discounted with the weight computed based on the boosting framework. Empirically, we evaluate our algorithm on both controller state-based and pixel-based environments from the DeepMind Control Suite. AILBoost outperforms DAC on both types of environments, demonstrating the benefit of properly weighting replay buffer data for off-policy training. On state-based environments, DAC outperforms ValueDICE and IQ-Learn (Gary et al., 2021), achieving competitive performance with as little as one expert trajectory.
Active Representation Learning for General Task Space with Applications in Robotics
Jun 15, 2023Representation learning based on multi-task pretraining has become a powerful approach in many domains. In particular, task-aware representation learning aims to learn an optimal representation for a specific target task by sampling data from a set of source tasks, while task-agnostic representation learning seeks to learn a universal representation for a class of tasks. In this paper, we propose a general and versatile algorithmic and theoretic framework for \textit{active representation learning}, where the learner optimally chooses which source tasks to sample from. This framework, along with a tractable meta algorithm, allows most arbitrary target and source task spaces (from discrete to continuous), covers both task-aware and task-agnostic settings, and is compatible with deep representation learning practices. We provide several instantiations under this framework, from bilinear and feature-based nonlinear to general nonlinear cases. In the bilinear case, by leveraging the non-uniform spectrum of the task representation and the calibrated source-target relevance, we prove that the sample complexity to achieve $\varepsilon$-excess risk on target scales with $ (k^*)^2 \|v^*\|_2^2 \varepsilon^{-2}$ where $k^*$ is the effective dimension of the target and $\|v^*\|_2^2 \in (0,1]$ represents the connection between source and target space. Compared to the passive one, this can save up to $\frac{1}{d_W}$ of sample complexity, where $d_W$ is the task space dimension. Finally, we demonstrate different instantiations of our meta algorithm in synthetic datasets and robotics problems, from pendulum simulations to real-world drone flight datasets. On average, our algorithms outperform baselines by $20\%-70\%$.