 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeV-R1: Reasoning-Enhanced Verilog Generation
May 30, 2025Large language models (LLMs) trained via reinforcement learning with verifiable reward (RLVR) have achieved breakthroughs on tasks with explicit, automatable verification, such as software programming and mathematical problems. Extending RLVR to electronic design automation (EDA), especially automatically generating hardware description languages (HDLs) like Verilog from natural-language (NL) specifications, however, poses three key challenges: the lack of automated and accurate verification environments, the scarcity of high-quality NL-code pairs, and the prohibitive computation cost of RLVR. To this end, we introduce CodeV-R1, an RLVR framework for training Verilog generation LLMs. First, we develop a rule-based testbench generator that performs robust equivalence checking against golden references. Second, we propose a round-trip data synthesis method that pairs open-source Verilog snippets with LLM-generated NL descriptions, verifies code-NL-code consistency via the generated testbench, and filters out inequivalent examples to yield a high-quality dataset. Third, we employ a two-stage "distill-then-RL" training pipeline: distillation for the cold start of reasoning abilities, followed by adaptive DAPO, our novel RLVR algorithm that can reduce training cost by adaptively adjusting sampling rate. The resulting model, CodeV-R1-7B, achieves 68.6% and 72.9% pass@1 on VerilogEval v2 and RTLLM v1.1, respectively, surpassing prior state-of-the-art by 12~20%, while matching or even exceeding the performance of 671B DeepSeek-R1. We will release our model, training pipeline, and dataset to facilitate research in EDA and LLM communities.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
New Solutions on LLM Acceleration, Optimization, and Application
Jun 16, 2024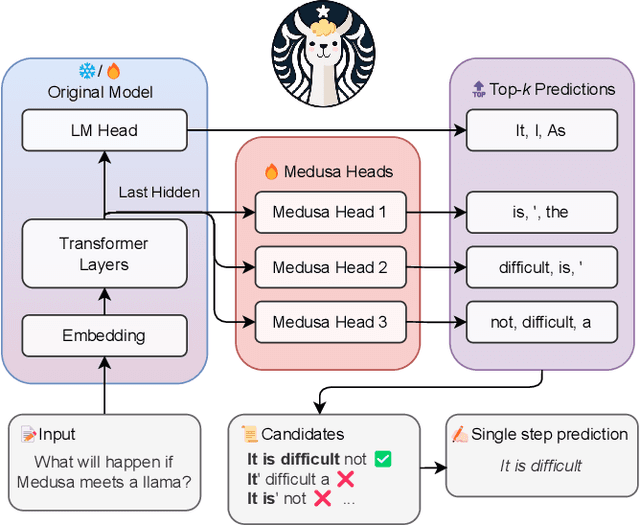
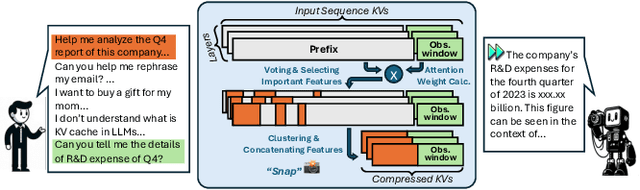
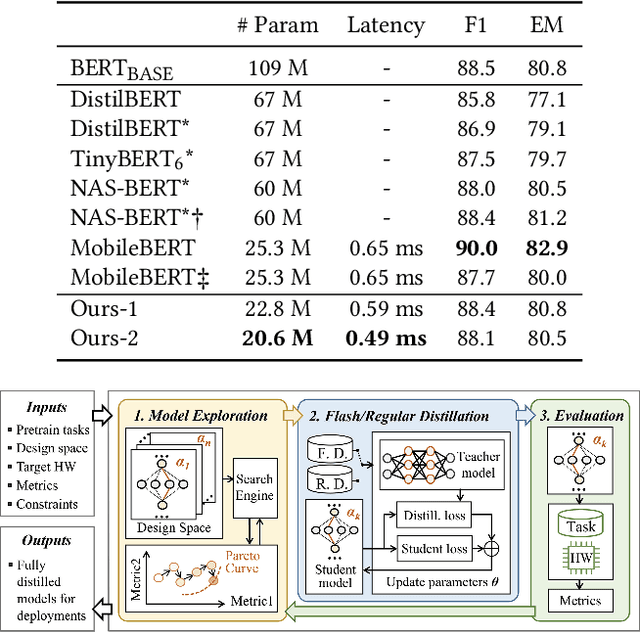
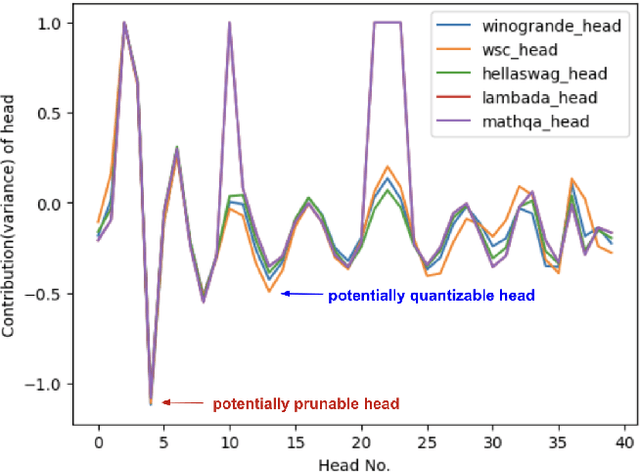
Large Language Models (LLMs) have become extremely potent instruments with exceptional capacities for comprehending and producing human-like text in a wide range of applications. However, the increasing size and complexity of LLMs present significant challenges in both training and deployment, leading to substantial computational and storage costs as well as heightened energy consumption. In this paper, we provide a review of recent advancements and research directions aimed at addressing these challenges and enhancing the efficiency of LLM-based systems. We begin by discussing algorithm-level acceleration techniques focused on optimizing LLM inference speed and resource utilization. We also explore LLM-hardware co-design strategies with a vision to improve system efficiency by tailoring hardware architectures to LLM requirements. Further, we delve into LLM-to-accelerator compilation approaches, which involve customizing hardware accelerators for efficient LLM deployment. Finally, as a case study to leverage LLMs for assisting circuit design, we examine LLM-aided design methodologies for an important task: High-Level Synthesis (HLS) functional verification, by creating a new dataset that contains a large number of buggy and bug-free codes, which can be essential for training LLMs to specialize on HLS verification and debugging. For each aspect mentioned above, we begin with a detailed background study, followed by the presentation of several novel solutions proposed to overcome specific challenges. We then outline future research directions to drive further advancements. Through these efforts, we aim to pave the way for more efficient and scalable deployment of LLMs across a diverse range of applications.
A Chebyshev Confidence Guided Source-Free Domain Adaptation Framework for Medical Image Segmentation
Oct 27, 2023



Source-free domain adaptation (SFDA) aims to adapt models trained on a labeled source domain to an unlabeled target domain without the access to source data. In medical imaging scenarios, the practical significance of SFDA methods has been emphasized due to privacy concerns. Recent State-of-the-art SFDA methods primarily rely on self-training based on pseudo-labels (PLs). Unfortunately, PLs suffer from accuracy deterioration caused by domain shift, and thus limit the effectiveness of the adaptation process. To address this issue, we propose a Chebyshev confidence guided SFDA framework to accurately assess the reliability of PLs and generate self-improving PLs for self-training. The Chebyshev confidence is estimated by calculating probability lower bound of the PL confidence, given the prediction and the corresponding uncertainty. Leveraging the Chebyshev confidence, we introduce two confidence-guided denoising methods: direct denoising and prototypical denoising. Additionally, we propose a novel teacher-student joint training scheme (TJTS) that incorporates a confidence weighting module to improve PLs iteratively. The TJTS, in collaboration with the denoising methods, effectively prevents the propagation of noise and enhances the accuracy of PLs. Extensive experiments in diverse domain scenarios validate the effectiveness of our proposed framework and establish its superiority over state-of-the-art SFDA methods. Our paper contributes to the field of SFDA by providing a novel approach for precisely estimating the reliability of pseudo-labels and a framework for obtaining high-quality PLs, resulting in improved adaptation performance.
Few-Shot Classification with Contrastive Learning
Sep 17, 2022


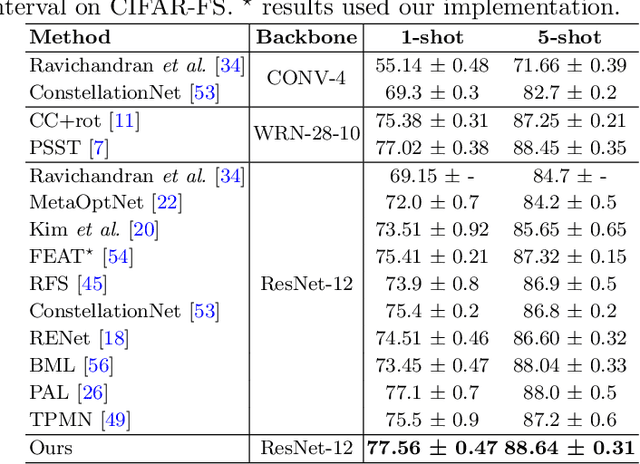
A two-stage training paradigm consisting of sequential pre-training and meta-training stages has been widely used in current few-shot learning (FSL) research. Many of these methods use self-supervised learning and contrastive learning to achieve new state-of-the-art results. However, the potential of contrastive learning in both stages of FSL training paradigm is still not fully exploited. In this paper, we propose a novel contrastive learning-based framework that seamlessly integrates contrastive learning into both stages to improve the performance of few-shot classification. In the pre-training stage, we propose a self-supervised contrastive loss in the forms of feature vector vs. feature map and feature map vs. feature map, which uses global and local information to learn good initial representations. In the meta-training stage, we propose a cross-view episodic training mechanism to perform the nearest centroid classification on two different views of the same episode and adopt a distance-scaled contrastive loss based on them. These two strategies force the model to overcome the bias between views and promote the transferability of representations. Extensive experiments on three benchmark datasets demonstrate that our method achieves competitive results.
Dynamic Spatio-Temporal Specialization Learning for Fine-Grained Action Recognition
Sep 03, 2022
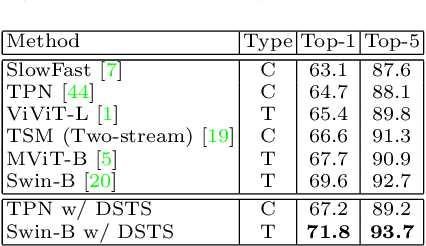
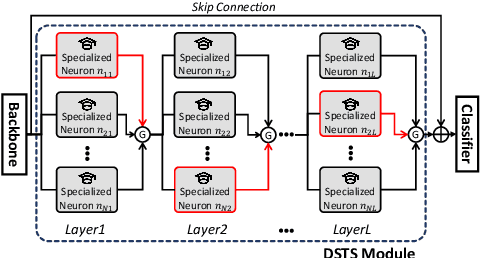
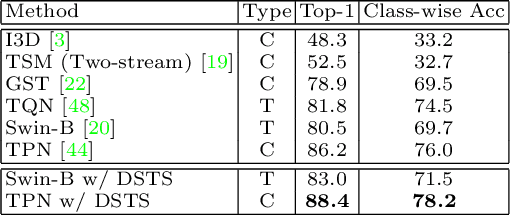
The goal of fine-grained action recognition is to successfully discriminate between action categories with subtle differences. To tackle this, we derive inspiration from the human visual system which contains specialized regions in the brain that are dedicated towards handling specific tasks. We design a novel Dynamic Spatio-Temporal Specialization (DSTS) module, which consists of specialized neurons that are only activated for a subset of samples that are highly similar. During training, the loss forces the specialized neurons to learn discriminative fine-grained differences to distinguish between these similar samples, improving fine-grained recognition. Moreover, a spatio-temporal specialization method further optimizes the architectures of the specialized neurons to capture either more spatial or temporal fine-grained information, to better tackle the large range of spatio-temporal variations in the videos. Lastly, we design an Upstream-Downstream Learning algorithm to optimize our model's dynamic decisions during training, improving the performance of our DSTS module. We obtain state-of-the-art performance on two widely-used fine-grained action recognition datasets.
Exploiting Spline Models for the Training of Fully Connected Layers in Neural Network
Feb 12, 2021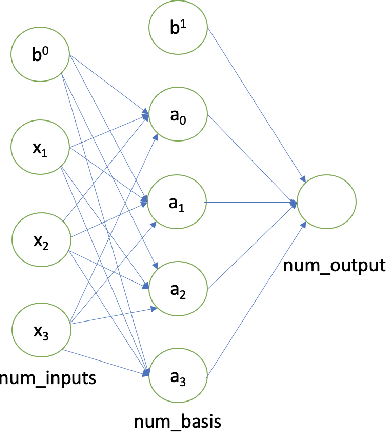

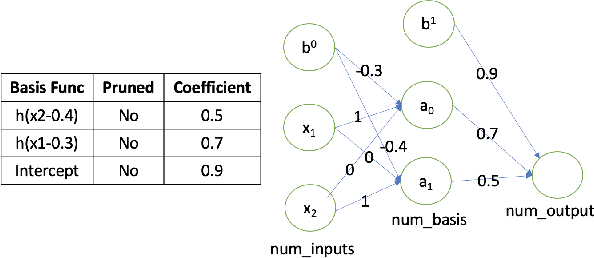
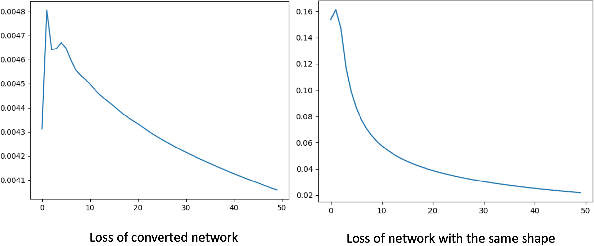
The fully connected (FC) layer, one of the most fundamental modules in artificial neural networks (ANN), is often considered difficult and inefficient to train due to issues including the risk of overfitting caused by its large amount of parameters. Based on previous work studying ANN from linear spline perspectives, we propose a spline-based approach that eases the difficulty of training FC layers. Given some dataset, we first obtain a continuous piece-wise linear (CPWL) fit through spline methods such as multivariate adaptive regression spline (MARS). Next, we construct an ANN model from the linear spline model and continue to train the ANN model on the dataset using gradient descent optimization algorithms. Our experimental results and theoretical analysis show that our approach reduces the computational cost, accelerates the convergence of FC layers, and significantly increases the interpretability of the resulting model (FC layers) compared with standard ANN training with random parameter initialization followed by gradient descent optimizations.
SA-Net: A deep spectral analysis network for image clustering
Sep 11, 2020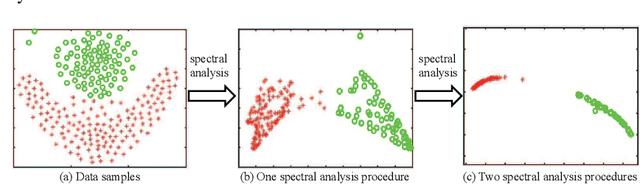
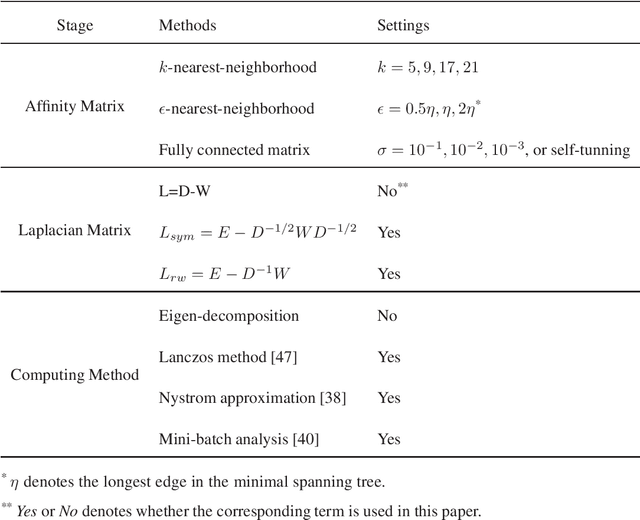
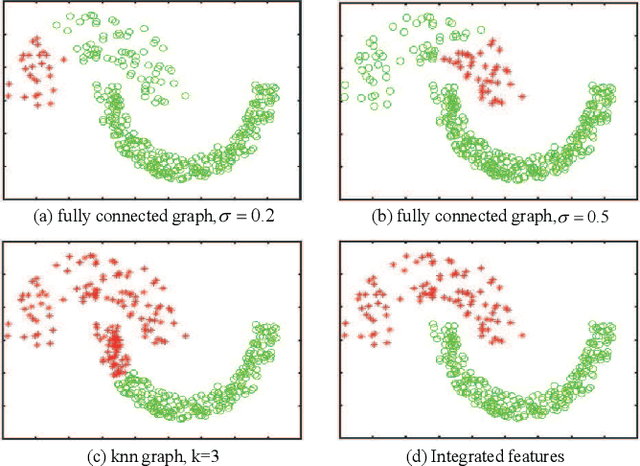
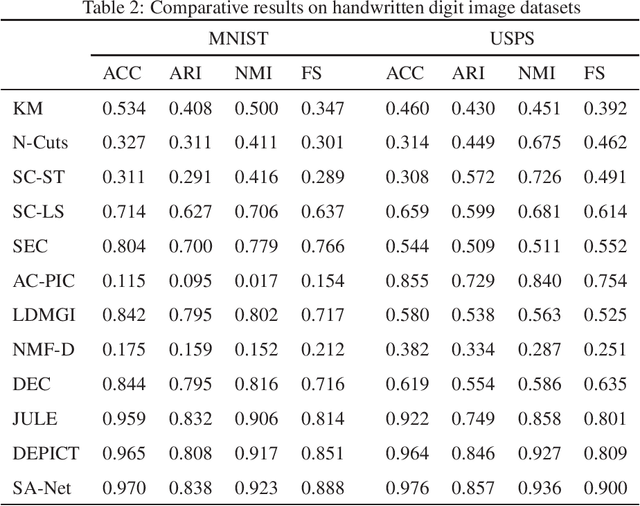
Although supervised deep representation learning has attracted enormous attentions across areas of pattern recognition and computer vision, little progress has been made towards unsupervised deep representation learning for image clustering. In this paper, we propose a deep spectral analysis network for unsupervised representation learning and image clustering. While spectral analysis is established with solid theoretical foundations and has been widely applied to unsupervised data mining, its essential weakness lies in the fact that it is difficult to construct a proper affinity matrix and determine the involving Laplacian matrix for a given dataset. In this paper, we propose a SA-Net to overcome these weaknesses and achieve improved image clustering by extending the spectral analysis procedure into a deep learning framework with multiple layers. The SA-Net has the capability to learn deep representations and reveal deep correlations among data samples. Compared with the existing spectral analysis, the SA-Net achieves two advantages: (i) Given the fact that one spectral analysis procedure can only deal with one subset of the given dataset, our proposed SA-Net elegantly integrates multiple parallel and consecutive spectral analysis procedures together to enable interactive learning across different units towards a coordinated clustering model; (ii) Our SA-Net can identify the local similarities among different images at patch level and hence achieves a higher level of robustness against occlusions. Extensive experiments on a number of popular datasets support that our proposed SA-Net outperforms 11 benchmarks across a number of image clustering applications.
* arXiv admin note: text overlap with arXiv:2009.05235
Spectral Analysis Network for Deep Representation Learning and Image Clustering
Sep 11, 2020


Deep representation learning is a crucial procedure in multimedia analysis and attracts increasing attention. Most of the popular techniques rely on convolutional neural network and require a large amount of labeled data in the training procedure. However, it is time consuming or even impossible to obtain the label information in some tasks due to cost limitation. Thus, it is necessary to develop unsupervised deep representation learning techniques. This paper proposes a new network structure for unsupervised deep representation learning based on spectral analysis, which is a popular technique with solid theory foundations. Compared with the existing spectral analysis methods, the proposed network structure has at least three advantages. Firstly, it can identify the local similarities among images in patch level and thus more robust against occlusion. Secondly, through multiple consecutive spectral analysis procedures, the proposed network can learn more clustering-friendly representations and is capable to reveal the deep correlations among data samples. Thirdly, it can elegantly integrate different spectral analysis procedures, so that each spectral analysis procedure can have their individual strengths in dealing with different data sample distributions. Extensive experimental results show the effectiveness of the proposed methods on various image clustering tasks.
An unsupervised deep learning framework via integrated optimization of representation learning and GMM-based modeling
Sep 11, 2020
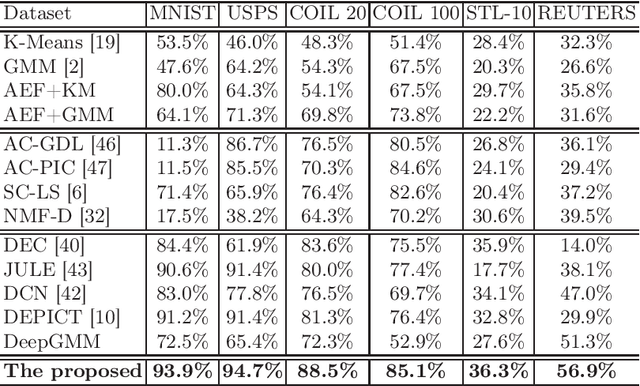


While supervised deep learning has achieved great success in a range of applications, relatively little work has studied the discovery of knowledge from unlabeled data. In this paper, we propose an unsupervised deep learning framework to provide a potential solution for the problem that existing deep learning techniques require large labeled data sets for completing the training process. Our proposed introduces a new principle of joint learning on both deep representations and GMM (Gaussian Mixture Model)-based deep modeling, and thus an integrated objective function is proposed to facilitate the principle. In comparison with the existing work in similar areas, our objective function has two learning targets, which are created to be jointly optimized to achieve the best possible unsupervised learning and knowledge discovery from unlabeled data sets. While maximizing the first target enables the GMM to achieve the best possible modeling of the data representations and each Gaussian component corresponds to a compact cluster, maximizing the second term will enhance the separability of the Gaussian components and hence the inter-cluster distances. As a result, the compactness of clusters is significantly enhanced by reducing the intra-cluster distances, and the separability is improved by increasing the inter-cluster distances. Extensive experimental results show that the propose method can improve the clustering performance compared with benchmark methods.