 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity and Long-Duration Human Image Animation with Diffusion Transformer
Dec 26, 2025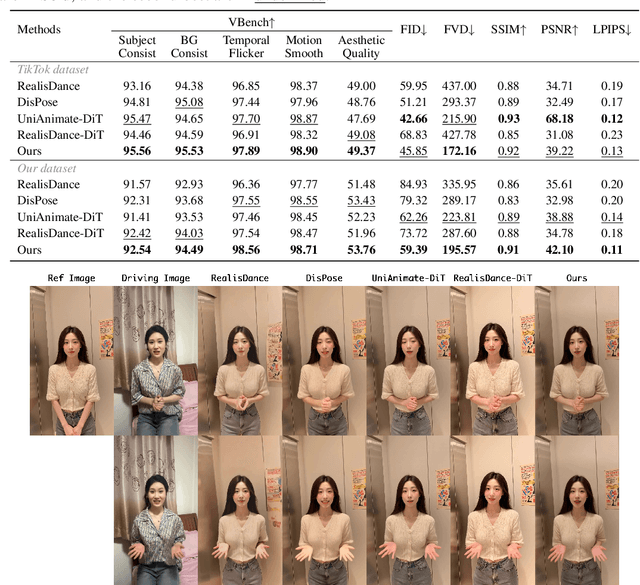

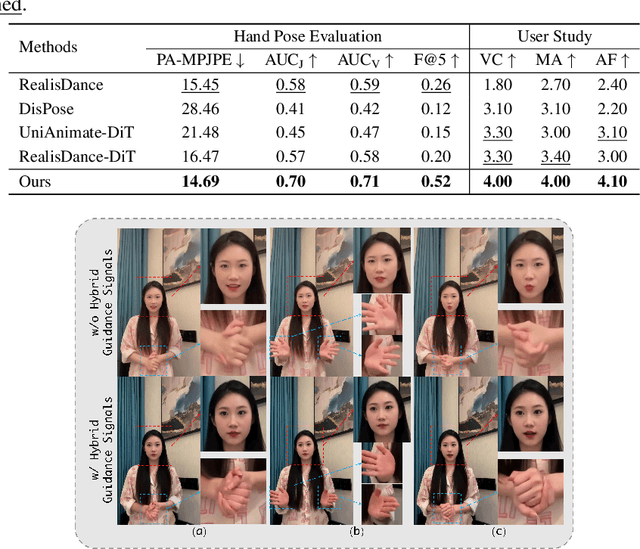
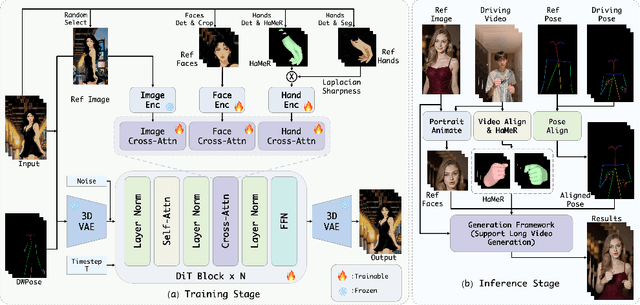
Recent progress in diffusion models has significantly advanced the field of human image animation. While existing methods can generate temporally consistent results for short or regular motions, significant challenges remain, particularly in generating long-duration videos. Furthermore, the synthesis of fine-grained facial and hand details remains under-explored, limiting the applicability of current approaches in real-world, high-quality applications. To address these limitations, we propose a diffusion transformer (DiT)-based framework which focuses on generating high-fidelity and long-duration human animation videos. First, we design a set of hybrid implicit guidance signals and a sharpness guidance factor, enabling our framework to additionally incorporate detailed facial and hand features as guidance. Next, we incorporate the time-aware position shift fusion module, modify the input format within the DiT backbone, and refer to this mechanism as the Position Shift Adaptive Module, which enables video generation of arbitrary length. Finally, we introduce a novel data augmentation strategy and a skeleton alignment model to reduce the impact of human shape variations across different identities. Experimental results demonstrate that our method outperforms existing state-of-the-art approaches, achieving superior performance in both high-fidelity and long-duration human image animation.
BFS-Prover: Scalable Best-First Tree Search for LLM-based Automatic Theorem Proving
Feb 05, 2025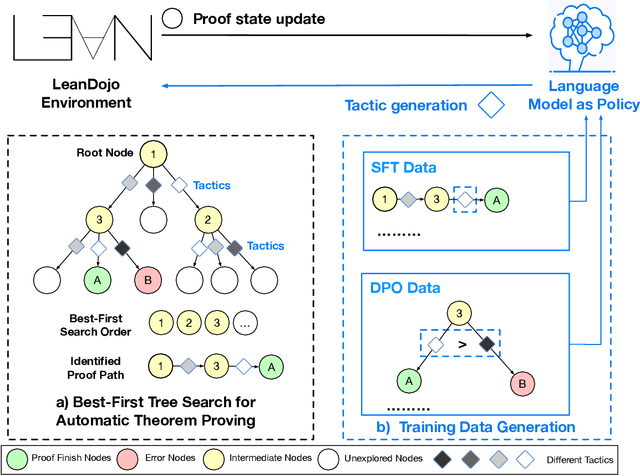
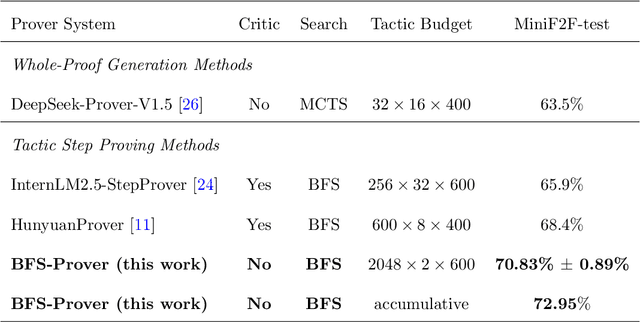
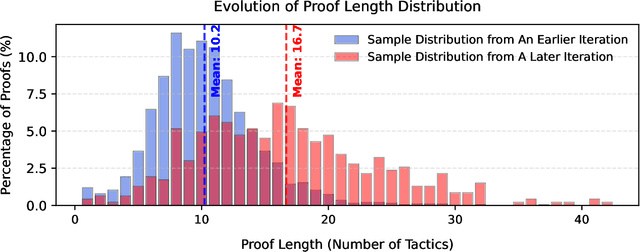
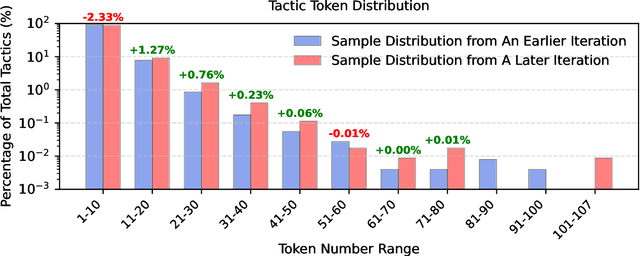
Recent advancements in large language models (LLMs) have spurred growing interest in automatic theorem proving using Lean4, where effective tree search methods are crucial for navigating proof search spaces. While the existing approaches primarily rely on value functions and Monte Carlo Tree Search (MCTS), the potential of simpler methods like Best-First Search (BFS) remains underexplored. This paper investigates whether BFS can achieve competitive performance in large-scale theorem proving tasks. We present \texttt{BFS-Prover}, a scalable expert iteration framework, featuring three key innovations. First, we implement strategic data filtering at each expert iteration round, excluding problems solvable via beam search node expansion to focus on harder cases. Second, we improve the sample efficiency of BFS through Direct Preference Optimization (DPO) applied to state-tactic pairs automatically annotated with compiler error feedback, refining the LLM's policy to prioritize productive expansions. Third, we employ length normalization in BFS to encourage exploration of deeper proof paths. \texttt{BFS-Prover} achieves a score of $71.31$ on the MiniF2F test set and therefore challenges the perceived necessity of complex tree search methods, demonstrating that BFS can achieve competitive performance when properly scaled.
ROADWork Dataset: Learning to Recognize, Observe, Analyze and Drive Through Work Zones
Jun 11, 2024



Perceiving and navigating through work zones is challenging and under-explored, even with major strides in self-driving research. An important reason is the lack of open datasets for developing new algorithms to address this long-tailed scenario. We propose the ROADWork dataset to learn how to recognize, observe and analyze and drive through work zones. We find that state-of-the-art foundation models perform poorly on work zones. With our dataset, we improve upon detecting work zone objects (+26.2 AP), while discovering work zones with higher precision (+32.5%) at a much higher discovery rate (12.8 times), significantly improve detecting (+23.9 AP) and reading (+14.2% 1-NED) work zone signs and describing work zones (+36.7 SPICE). We also compute drivable paths from work zone navigation videos and show that it is possible to predict navigational goals and pathways such that 53.6% goals have angular error (AE) < 0.5 degrees (+9.9 %) and 75.3% pathways have AE < 0.5 degrees (+8.1 %).
Addressing Source Scale Bias via Image Warping for Domain Adaptation
Mar 19, 2024



In visual recognition, scale bias is a key challenge due to the imbalance of object and image size distribution inherent in real scene datasets. Conventional solutions involve injecting scale invariance priors, oversampling the dataset at different scales during training, or adjusting scale at inference. While these strategies mitigate scale bias to some extent, their ability to adapt across diverse datasets is limited. Besides, they increase computational load during training and latency during inference. In this work, we use adaptive attentional processing -- oversampling salient object regions by warping images in-place during training. Discovering that shifting the source scale distribution improves backbone features, we developed a instance-level warping guidance aimed at object region sampling to mitigate source scale bias in domain adaptation. Our approach improves adaptation across geographies, lighting and weather conditions, is agnostic to the task, domain adaptation algorithm, saliency guidance, and underlying model architecture. Highlights include +6.1 mAP50 for BDD100K Clear $\rightarrow$ DENSE Foggy, +3.7 mAP50 for BDD100K Day $\rightarrow$ Night, +3.0 mAP50 for BDD100K Clear $\rightarrow$ Rainy, and +6.3 mIoU for Cityscapes $\rightarrow$ ACDC. Our approach adds minimal memory during training and has no additional latency at inference time. Please see Appendix for more results and analysis.
TPSeNCE: Towards Artifact-Free Realistic Rain Generation for Deraining and Object Detection in Rain
Nov 08, 2023



Rain generation algorithms have the potential to improve the generalization of deraining methods and scene understanding in rainy conditions. However, in practice, they produce artifacts and distortions and struggle to control the amount of rain generated due to a lack of proper constraints. In this paper, we propose an unpaired image-to-image translation framework for generating realistic rainy images. We first introduce a Triangular Probability Similarity (TPS) constraint to guide the generated images toward clear and rainy images in the discriminator manifold, thereby minimizing artifacts and distortions during rain generation. Unlike conventional contrastive learning approaches, which indiscriminately push negative samples away from the anchors, we propose a Semantic Noise Contrastive Estimation (SeNCE) strategy and reassess the pushing force of negative samples based on the semantic similarity between the clear and the rainy images and the feature similarity between the anchor and the negative samples. Experiments demonstrate realistic rain generation with minimal artifacts and distortions, which benefits image deraining and object detection in rain. Furthermore, the method can be used to generate realistic snowy and night images, underscoring its potential for broader applicability. Code is available at https://github.com/ShenZheng2000/TPSeNCE.
GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond
Oct 10, 2023With the rapid advancement of large language models (LLMs), there is a pressing need for a comprehensive evaluation suite to assess their capabilities and limitations. Existing LLM leaderboards often reference scores reported in other papers without consistent settings and prompts, which may inadvertently encourage cherry-picking favored settings and prompts for better results. In this work, we introduce GPT-Fathom, an open-source and reproducible LLM evaluation suite built on top of OpenAI Evals. We systematically evaluate 10+ leading LLMs as well as OpenAI's legacy models on 20+ curated benchmarks across 7 capability categories, all under aligned settings. Our retrospective study on OpenAI's earlier models offers valuable insights into the evolutionary path from GPT-3 to GPT-4. Currently, the community is eager to know how GPT-3 progressively improves to GPT-4, including technical details like whether adding code data improves LLM's reasoning capability, which aspects of LLM capability can be improved by SFT and RLHF, how much is the alignment tax, etc. Our analysis sheds light on many of these questions, aiming to improve the transparency of advanced LLMs.
Quantifying Association Capabilities of Large Language Models and Its Implications on Privacy Leakage
May 22, 2023



The advancement of large language models (LLMs) brings notable improvements across various applications, while simultaneously raising concerns about potential private data exposure. One notable capability of LLMs is their ability to form associations between different pieces of information, but this raises concerns when it comes to personally identifiable information (PII). This paper delves into the association capabilities of language models, aiming to uncover the factors that influence their proficiency in associating information. Our study reveals that as models scale up, their capacity to associate entities/information intensifies, particularly when target pairs demonstrate shorter co-occurrence distances or higher co-occurrence frequencies. However, there is a distinct performance gap when associating commonsense knowledge versus PII, with the latter showing lower accuracy. Despite the proportion of accurately predicted PII being relatively small, LLMs still demonstrate the capability to predict specific instances of email addresses and phone numbers when provided with appropriate prompts. These findings underscore the potential risk to PII confidentiality posed by the evolving capabilities of LLMs, especially as they continue to expand in scale and power.
Why Does ChatGPT Fall Short in Answering Questions Faithfully?
Apr 20, 2023
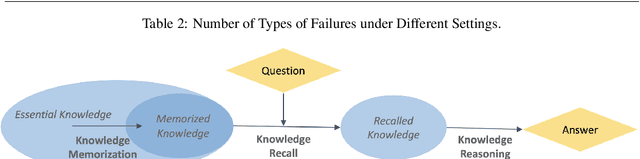

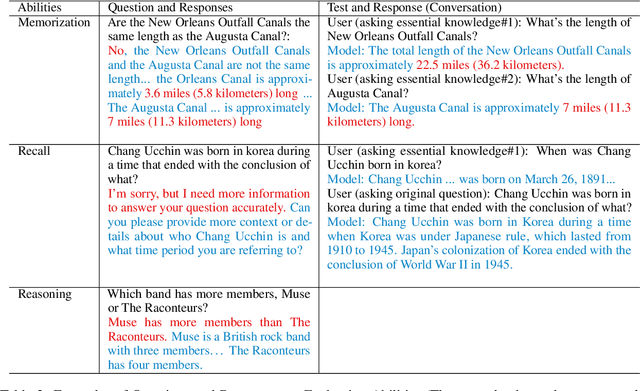
Recent advancements in Large Language Models, such as ChatGPT, have demonstrated significant potential to impact various aspects of human life. However, ChatGPT still faces challenges in aspects like faithfulness. Taking question answering as a representative application, we seek to understand why ChatGPT falls short in answering questions faithfully. To address this question, we attempt to analyze the failures of ChatGPT in complex open-domain question answering and identifies the abilities under the failures. Specifically, we categorize ChatGPT's failures into four types: comprehension, factualness, specificity, and inference. We further pinpoint three critical abilities associated with QA failures: knowledge memorization, knowledge association, and knowledge reasoning. Additionally, we conduct experiments centered on these abilities and propose potential approaches to enhance faithfulness. The results indicate that furnishing the model with fine-grained external knowledge, hints for knowledge association, and guidance for reasoning can empower the model to answer questions more faithfully.
Low-Light Image and Video Enhancement: A Comprehensive Survey and Beyond
Dec 21, 2022

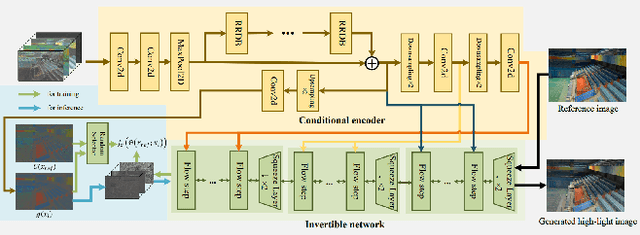
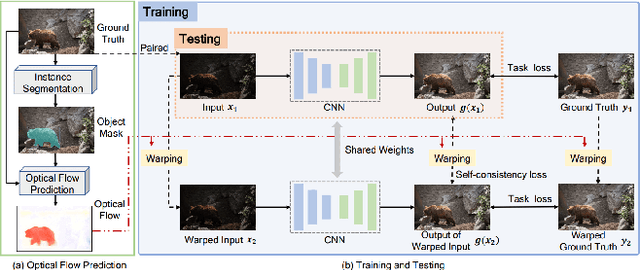
This paper presents a comprehensive survey of low-light image and video enhancement. We begin with the challenging mixed over-/under-exposed images, which are under-performed by existing methods. To this end, we propose two variants of the SICE dataset named SICE_Grad and SICE_Mix. Next, we introduce Night Wenzhou, a large-scale, high-resolution video dataset, to address the issue of the lack of a low-light video dataset that discount the use of low-light image enhancement (LLIE) to videos. The Night Wenzhou dataset is challenging since it consists of fast-moving aerial scenes and streetscapes with varying illuminations and degradation. We conduct extensive key technique analysis and experimental comparisons for representative LLIE approaches using these newly proposed datasets and the current benchmark datasets. Finally, we address unresolved issues and propose future research topics for the LLIE community.
PointNorm: Normalization is All You Need for Point Cloud Analysis
Jul 13, 2022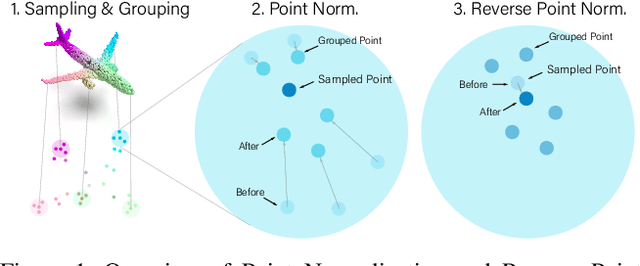
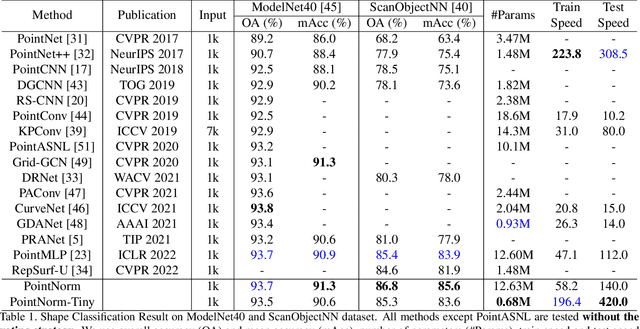
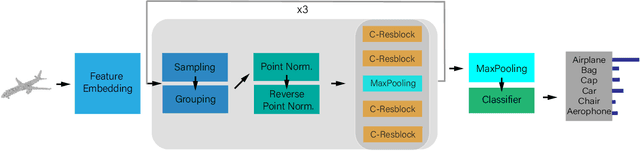
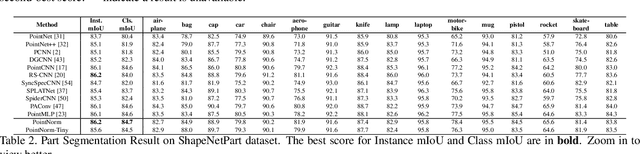
Point cloud analysis is challenging due to the irregularity of the point cloud data structure. Existing works typically employ the ad-hoc sampling-grouping operation of PointNet++, followed by sophisticated local and/or global feature extractors for leveraging the 3D geometry of the point cloud. Unfortunately, those intricate hand-crafted model designs have led to poor inference latency and performance saturation in the last few years. In this paper, we point out that the classical sampling-grouping operations on the irregular point cloud cause learning difficulty for the subsequent MLP layers. To reduce the irregularity of the point cloud, we introduce a DualNorm module after the sampling-grouping operation. The DualNorm module consists of Point Normalization, which normalizes the grouped points to the sampled points, and Reverse Point Normalization, which normalizes the sampled points to the grouped points. The proposed PointNorm utilizes local mean and global standard deviation to benefit from both local and global features while maintaining a faithful inference speed. Experiments on point cloud classification show that we achieved state-of-the-art accuracy on ModelNet40 and ScanObjectNN datasets. We also generalize our model to point cloud part segmentation and demonstrate competitive performance on the ShapeNetPart dataset. Code is available at https://github.com/ShenZheng2000/PointNorm-for-Point-Cloud-Analysis.