 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTPSeNCE: Towards Artifact-Free Realistic Rain Generation for Deraining and Object Detection in Rain
Nov 08, 2023



Rain generation algorithms have the potential to improve the generalization of deraining methods and scene understanding in rainy conditions. However, in practice, they produce artifacts and distortions and struggle to control the amount of rain generated due to a lack of proper constraints. In this paper, we propose an unpaired image-to-image translation framework for generating realistic rainy images. We first introduce a Triangular Probability Similarity (TPS) constraint to guide the generated images toward clear and rainy images in the discriminator manifold, thereby minimizing artifacts and distortions during rain generation. Unlike conventional contrastive learning approaches, which indiscriminately push negative samples away from the anchors, we propose a Semantic Noise Contrastive Estimation (SeNCE) strategy and reassess the pushing force of negative samples based on the semantic similarity between the clear and the rainy images and the feature similarity between the anchor and the negative samples. Experiments demonstrate realistic rain generation with minimal artifacts and distortions, which benefits image deraining and object detection in rain. Furthermore, the method can be used to generate realistic snowy and night images, underscoring its potential for broader applicability. Code is available at https://github.com/ShenZheng2000/TPSeNCE.
Low-Light Image and Video Enhancement: A Comprehensive Survey and Beyond
Dec 21, 2022

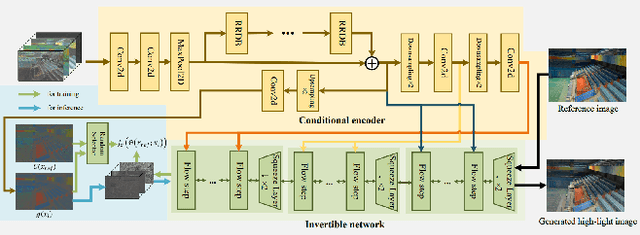
This paper presents a comprehensive survey of low-light image and video enhancement. We begin with the challenging mixed over-/under-exposed images, which are under-performed by existing methods. To this end, we propose two variants of the SICE dataset named SICE_Grad and SICE_Mix. Next, we introduce Night Wenzhou, a large-scale, high-resolution video dataset, to address the issue of the lack of a low-light video dataset that discount the use of low-light image enhancement (LLIE) to videos. The Night Wenzhou dataset is challenging since it consists of fast-moving aerial scenes and streetscapes with varying illuminations and degradation. We conduct extensive key technique analysis and experimental comparisons for representative LLIE approaches using these newly proposed datasets and the current benchmark datasets. Finally, we address unresolved issues and propose future research topics for the LLIE community.
A Survey on Causal Representation Learning and Future Work for Medical Image Analysis
Oct 28, 2022



Statistical machine learning algorithms have achieved state-of-the-art results on benchmark datasets, outperforming humans in many tasks. However, the out-of-distribution data and confounder, which have an unpredictable causal relationship, significantly degrade the performance of the existing models. Causal Representation Learning (CRL) has recently been a promising direction to address the causal relationship problem in vision understanding. This survey presents recent advances in CRL in vision. Firstly, we introduce the basic concept of causal inference. Secondly, we analyze the CRL theoretical work, especially in invariant risk minimization, and the practical work in feature understanding and transfer learning. Finally, we propose a future research direction in medical image analysis and CRL general theory.
PointNorm: Normalization is All You Need for Point Cloud Analysis
Jul 13, 2022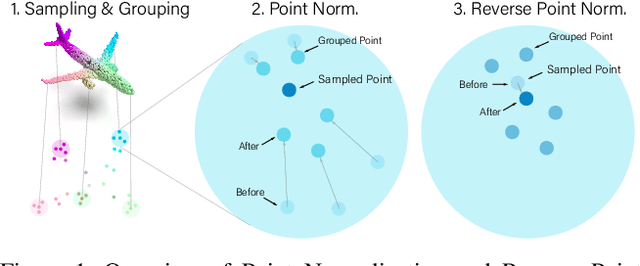
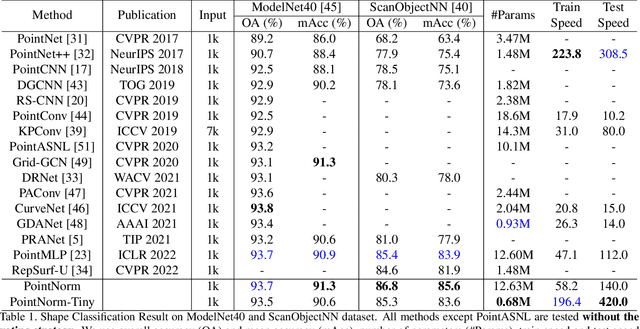
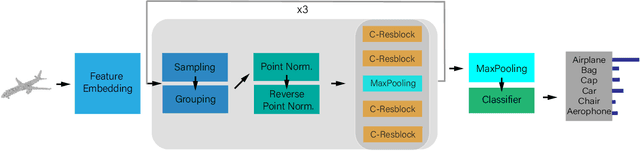
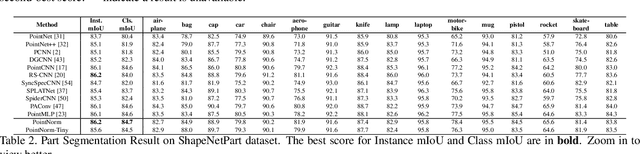
Point cloud analysis is challenging due to the irregularity of the point cloud data structure. Existing works typically employ the ad-hoc sampling-grouping operation of PointNet++, followed by sophisticated local and/or global feature extractors for leveraging the 3D geometry of the point cloud. Unfortunately, those intricate hand-crafted model designs have led to poor inference latency and performance saturation in the last few years. In this paper, we point out that the classical sampling-grouping operations on the irregular point cloud cause learning difficulty for the subsequent MLP layers. To reduce the irregularity of the point cloud, we introduce a DualNorm module after the sampling-grouping operation. The DualNorm module consists of Point Normalization, which normalizes the grouped points to the sampled points, and Reverse Point Normalization, which normalizes the sampled points to the grouped points. The proposed PointNorm utilizes local mean and global standard deviation to benefit from both local and global features while maintaining a faithful inference speed. Experiments on point cloud classification show that we achieved state-of-the-art accuracy on ModelNet40 and ScanObjectNN datasets. We also generalize our model to point cloud part segmentation and demonstrate competitive performance on the ShapeNetPart dataset. Code is available at https://github.com/ShenZheng2000/PointNorm-for-Point-Cloud-Analysis.
Functional Optimization Reinforcement Learning for Real-Time Bidding
Jul 03, 2022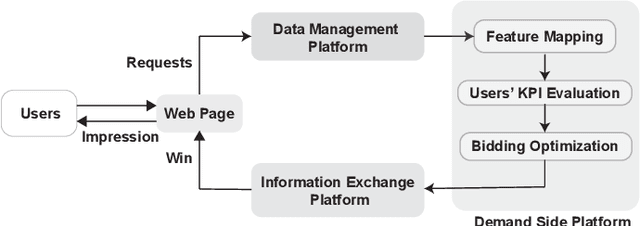
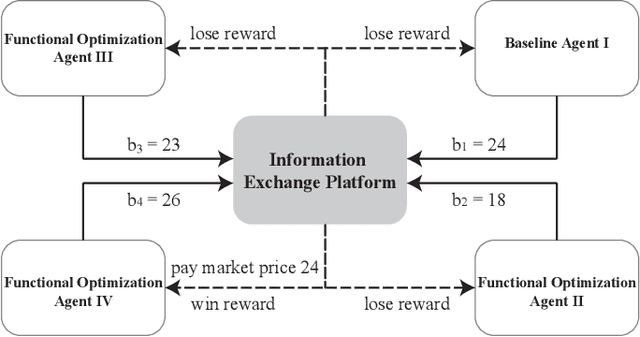
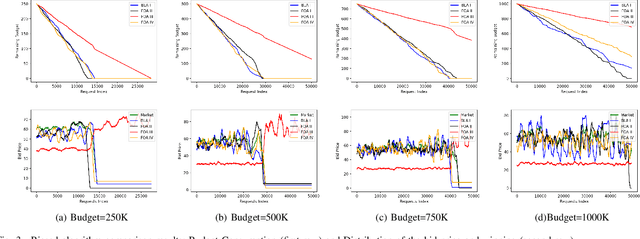
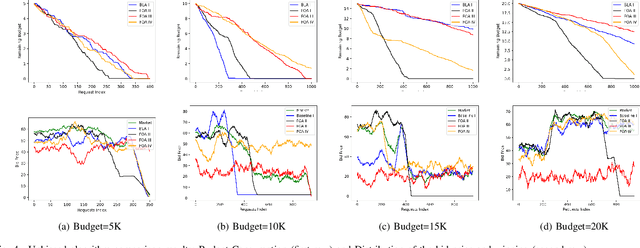
Real-time bidding is the new paradigm of programmatic advertising. An advertiser wants to make the intelligent choice of utilizing a \textbf{Demand-Side Platform} to improve the performance of their ad campaigns. Existing approaches are struggling to provide a satisfactory solution for bidding optimization due to stochastic bidding behavior. In this paper, we proposed a multi-agent reinforcement learning architecture for RTB with functional optimization. We designed four agents bidding environment: three Lagrange-multiplier based functional optimization agents and one baseline agent (without any attribute of functional optimization) First, numerous attributes have been assigned to each agent, including biased or unbiased win probability, Lagrange multiplier, and click-through rate. In order to evaluate the proposed RTB strategy's performance, we demonstrate the results on ten sequential simulated auction campaigns. The results show that agents with functional actions and rewards had the most significant average winning rate and winning surplus, given biased and unbiased winning information respectively. The experimental evaluations show that our approach significantly improve the campaign's efficacy and profitability.
AS-IntroVAE: Adversarial Similarity Distance Makes Robust IntroVAE
Jun 28, 2022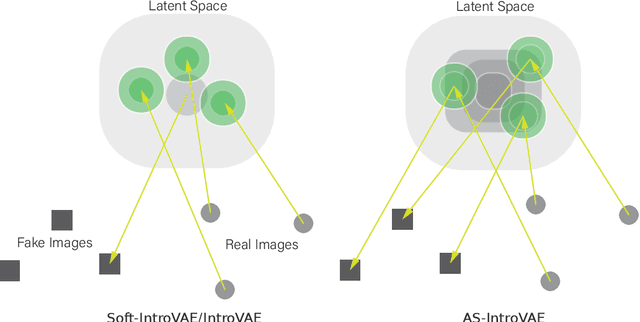
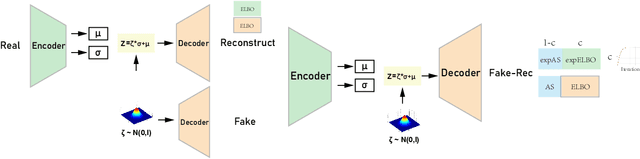
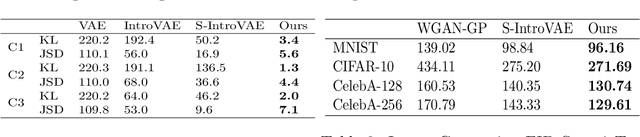

Recently, introspective models like IntroVAE and S-IntroVAE have excelled in image generation and reconstruction tasks. The principal characteristic of introspective models is the adversarial learning of VAE, where the encoder attempts to distinguish between the real and the fake (i.e., synthesized) images. However, due to the unavailability of an effective metric to evaluate the difference between the real and the fake images, the posterior collapse and the vanishing gradient problem still exist, reducing the fidelity of the synthesized images. In this paper, we propose a new variation of IntroVAE called Adversarial Similarity Distance Introspective Variational Autoencoder (AS-IntroVAE). We theoretically analyze the vanishing gradient problem and construct a new Adversarial Similarity Distance (AS-Distance) using the 2-Wasserstein distance and the kernel trick. With weight annealing on AS-Distance and KL-Divergence, the AS-IntroVAE are able to generate stable and high-quality images. The posterior collapse problem is addressed by making per-batch attempts to transform the image so that it better fits the prior distribution in the latent space. Compared with the per-image approach, this strategy fosters more diverse distributions in the latent space, allowing our model to produce images of great diversity. Comprehensive experiments on benchmark datasets demonstrate the effectiveness of AS-IntroVAE on image generation and reconstruction tasks.
Unsupervised Domain Adaptation for Cardiac Segmentation: Towards Structure Mutual Information Maximization
Apr 20, 2022

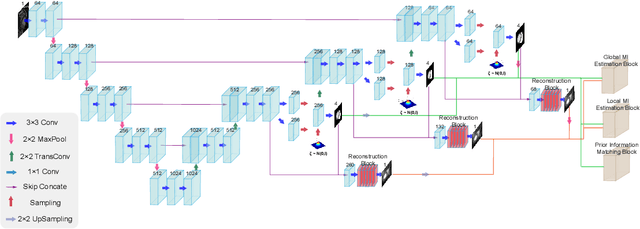
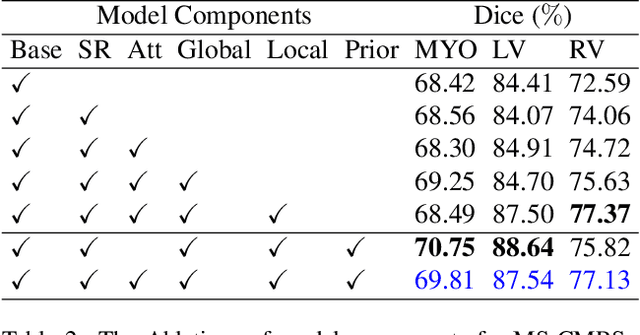
Unsupervised domain adaptation approaches have recently succeeded in various medical image segmentation tasks. The reported works often tackle the domain shift problem by aligning the domain-invariant features and minimizing the domain-specific discrepancies. That strategy works well when the difference between a specific domain and between different domains is slight. However, the generalization ability of these models on diverse imaging modalities remains a significant challenge. This paper introduces UDA-VAE++, an unsupervised domain adaptation framework for cardiac segmentation with a compact loss function lower bound. To estimate this new lower bound, we develop a novel Structure Mutual Information Estimation (SMIE) block with a global estimator, a local estimator, and a prior information matching estimator to maximize the mutual information between the reconstruction and segmentation tasks. Specifically, we design a novel sequential reparameterization scheme that enables information flow and variance correction from the low-resolution latent space to the high-resolution latent space. Comprehensive experiments on benchmark cardiac segmentation datasets demonstrate that our model outperforms previous state-of-the-art qualitatively and quantitatively. The code is available at https://github.com/LOUEY233/Toward-Mutual-Information}{https://github.com/LOUEY233/Toward-Mutual-Information
SAPNet: Segmentation-Aware Progressive Network for Perceptual Contrastive Deraining
Nov 26, 2021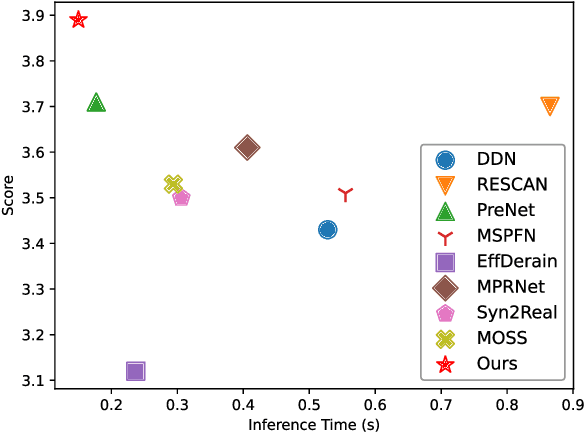
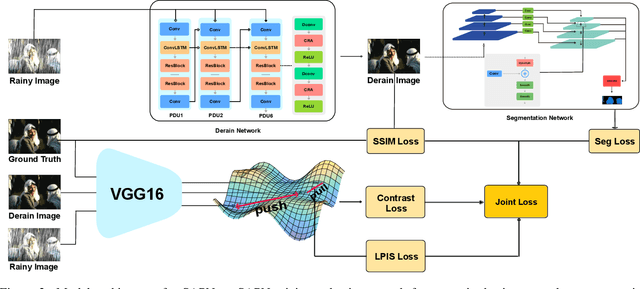
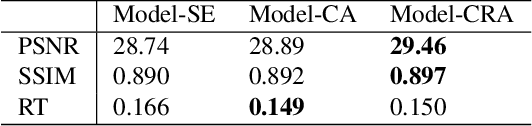
Deep learning algorithms have recently achieved promising deraining performances on both the natural and synthetic rainy datasets. As an essential low-level pre-processing stage, a deraining network should clear the rain streaks and preserve the fine semantic details. However, most existing methods only consider low-level image restoration. That limits their performances at high-level tasks requiring precise semantic information. To address this issue, in this paper, we present a segmentation-aware progressive network (SAPNet) based upon contrastive learning for single image deraining. We start our method with a lightweight derain network formed with progressive dilated units (PDU). The PDU can significantly expand the receptive field and characterize multi-scale rain streaks without the heavy computation on multi-scale images. A fundamental aspect of this work is an unsupervised background segmentation (UBS) network initialized with ImageNet and Gaussian weights. The UBS can faithfully preserve an image's semantic information and improve the generalization ability to unseen photos. Furthermore, we introduce a perceptual contrastive loss (PCL) and a learned perceptual image similarity loss (LPISL) to regulate model learning. By exploiting the rainy image and groundtruth as the negative and the positive sample in the VGG-16 latent space, we bridge the fine semantic details between the derained image and the groundtruth in a fully constrained manner. Comprehensive experiments on synthetic and real-world rainy images show our model surpasses top-performing methods and aids object detection and semantic segmentation with considerable efficacy. A Pytorch Implementation is available at https://github.com/ShenZheng2000/SAPNet-for-image-deraining.
Asian Giant Hornet Control based on Image Processing and Biological Dispersal
Nov 26, 2021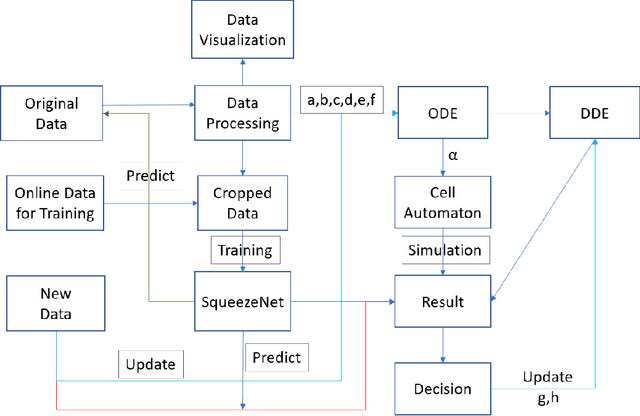



The Asian giant hornet (AGH) appeared in Washington State appears to have a potential danger of bioinvasion. Washington State has collected public photos and videos of detected insects for verification and further investigation. In this paper, we analyze AGH using data analysis,statistics, discrete mathematics, and deep learning techniques to process the data to controlAGH spreading.First, we visualize the geographical distribution of insects in Washington State. Then we investigate insect populations to varying months of the year and different days of a month.Third, we employ wavelet analysis to examine the periodic spread of AGH. Fourth, we apply ordinary differential equations to examine AGH numbers at the different natural growthrate and reaction speed and output the potential propagation coefficient. Next, we leverage cellular automaton combined with the potential propagation coefficient to simulate the geographical spread under changing potential propagation. To update the model, we use delayed differential equations to simulate human intervention. We use the time difference between detection time and submission time to determine the unit of time to delay time. After that, we construct a lightweight CNN called SqueezeNet and assess its classification performance. We then relate several non-reference image quality metrics, including NIQE, image gradient, entropy, contrast, and TOPSIS to judge the cause of misclassification. Furthermore, we build a Random Forest classifier to identify positive and negative samples based on image qualities only. We also display the feature importance and conduct an error analysis. Besides, we present sensitivity analysis to verify the robustness of our models. Finally, we show the strengths and weaknesses of our model and derives the conclusions.