 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextWeaver: Selective and Dependency-Structured Memory Construction for LLM Agents
Apr 24, 2026Large language model (LLM) agents often struggle in long-context interactions. As the agent accumulates more interaction history, context management approaches such as sliding window and prompt compression may omit earlier structured information that later steps rely on. Recent retrieval-based memory systems surface relevant content but still overlook the causal and logical structure needed for multi-step reasoning. We introduce ContextWeaver, a selective and dependency-structured memory framework that organizes an agent's interaction trace into a graph of reasoning steps and selects the relevant context for future actions. Unlike prior context management approaches, ContextWeaver supports: (1) dependency-based construction and traversal that link each step to the earlier steps it relies on; (2) compact dependency summarization that condenses root-to-step reasoning paths into reusable units; and (3) a lightweight validation layer that incorporates execution feedback. On the SWE-Bench Verified and Lite benchmarks, ContextWeaver improves performance over a sliding-window baseline in pass@1, while reducing reasoning steps and token usage. Our observations suggest that modeling logical dependencies provides a stable and scalable memory mechanism for LLM agents that use tools.
Base and Exponent Prediction in Mathematical Expressions using Multi-Output CNN
Jul 20, 2024The use of neural networks and deep learning techniques in image processing has significantly advanced the field, enabling highly accurate recognition results. However, achieving high recognition rates often necessitates complex network models, which can be challenging to train and require substantial computational resources. This research presents a simplified yet effective approach to predicting both the base and exponent from images of mathematical expressions using a multi-output Convolutional Neural Network (CNN). The model is trained on 10,900 synthetically generated images containing exponent expressions, incorporating random noise, font size variations, and blur intensity to simulate real-world conditions. The proposed CNN model demonstrates robust performance with efficient training time. The experimental results indicate that the model achieves high accuracy in predicting the base and exponent values, proving the efficacy of this approach in handling noisy and varied input images.
Comparing and Contrasting Deep Learning Weather Prediction Backbones on Navier-Stokes and Atmospheric Dynamics
Jul 19, 2024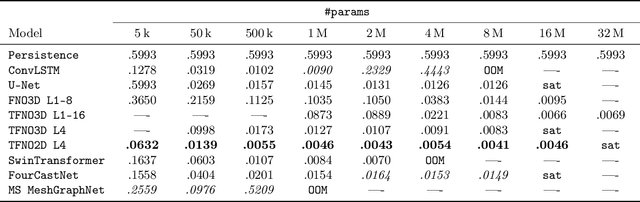
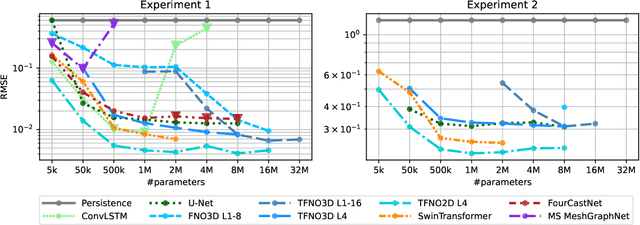
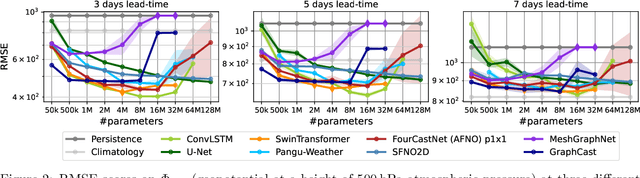
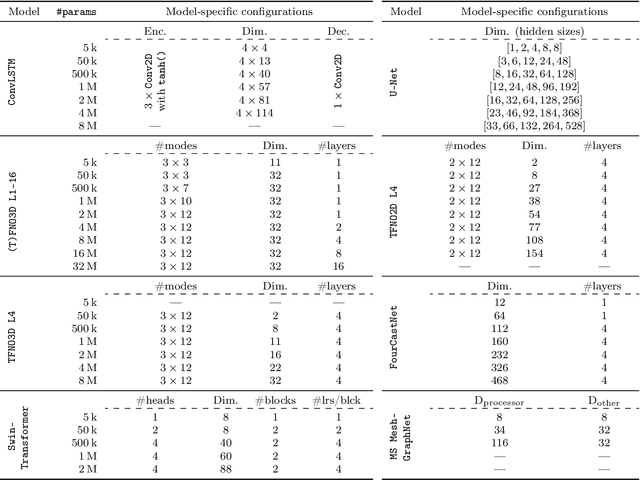
Remarkable progress in the development of Deep Learning Weather Prediction (DLWP) models positions them to become competitive with traditional numerical weather prediction (NWP) models. Indeed, a wide number of DLWP architectures -- based on various backbones, including U-Net, Transformer, Graph Neural Network (GNN), and Fourier Neural Operator (FNO) -- have demonstrated their potential at forecasting atmospheric states. However, due to differences in training protocols, forecast horizons, and data choices, it remains unclear which (if any) of these methods and architectures are most suitable for weather forecasting and for future model development. Here, we step back and provide a detailed empirical analysis, under controlled conditions, comparing and contrasting the most prominent DLWP models, along with their backbones. We accomplish this by predicting synthetic two-dimensional incompressible Navier-Stokes and real-world global weather dynamics. In terms of accuracy, memory consumption, and runtime, our results illustrate various tradeoffs. For example, on synthetic data, we observe favorable performance of FNO; and on the real-world WeatherBench dataset, our results demonstrate the suitability of ConvLSTM and SwinTransformer for short-to-mid-ranged forecasts. For long-ranged weather rollouts of up to 365 days, we observe superior stability and physical soundness in architectures that formulate a spherical data representation, i.e., GraphCast and Spherical FNO. In addition, we observe that all of these model backbones ``saturate,'' i.e., none of them exhibit so-called neural scaling, which highlights an important direction for future work on these and related models.
IDentity with Locality: An ideal hash for gene sequence search
Jun 21, 2024



Gene sequence search is a fundamental operation in computational genomics. Due to the petabyte scale of genome archives, most gene search systems now use hashing-based data structures such as Bloom Filters (BF). The state-of-the-art systems such as Compact bit-slicing signature index (COBS) and Repeated And Merged Bloom filters (RAMBO) use BF with Random Hash (RH) functions for gene representation and identification. The standard recipe is to cast the gene search problem as a sequence of membership problems testing if each subsequent gene substring (called kmer) of Q is present in the set of kmers of the entire gene database D. We observe that RH functions, which are crucial to the memory and the computational advantage of BF, are also detrimental to the system performance of gene-search systems. While subsequent kmers being queried are likely very similar, RH, oblivious to any similarity, uniformly distributes the kmers to different parts of potentially large BF, thus triggering excessive cache misses and causing system slowdown. We propose a novel hash function called the Identity with Locality (IDL) hash family, which co-locates the keys close in input space without causing collisions. This approach ensures both cache locality and key preservation. IDL functions can be a drop-in replacement for RH functions and help improve the performance of information retrieval systems. We give a simple but practical construction of IDL function families and show that replacing the RH with IDL functions reduces cache misses by a factor of 5x, thus improving query and indexing times of SOTA methods such as COBS and RAMBO by factors up to 2x without compromising their quality. We also provide a theoretical analysis of the false positive rate of BF with IDL functions. Our hash function is the first study that bridges Locality Sensitive Hash (LSH) and RH to obtain cache efficiency.
Collage: Light-Weight Low-Precision Strategy for LLM Training
May 06, 2024



Large models training is plagued by the intense compute cost and limited hardware memory. A practical solution is low-precision representation but is troubled by loss in numerical accuracy and unstable training rendering the model less useful. We argue that low-precision floating points can perform well provided the error is properly compensated at the critical locations in the training process. We propose Collage which utilizes multi-component float representation in low-precision to accurately perform operations with numerical errors accounted. To understand the impact of imprecision to training, we propose a simple and novel metric which tracks the lost information during training as well as differentiates various precision strategies. Our method works with commonly used low-precision such as half-precision ($16$-bit floating points) and can be naturally extended to work with even lower precision such as $8$-bit. Experimental results show that pre-training using Collage removes the requirement of using $32$-bit floating-point copies of the model and attains similar/better training performance compared to $(16, 32)$-bit mixed-precision strategy, with up to $3.7\times$ speedup and $\sim 15\%$ to $23\%$ less memory usage in practice.
HLAT: High-quality Large Language Model Pre-trained on AWS Trainium
Apr 16, 2024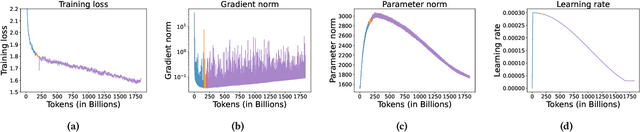
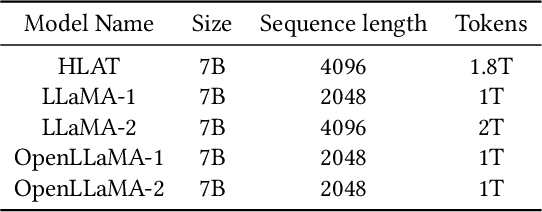
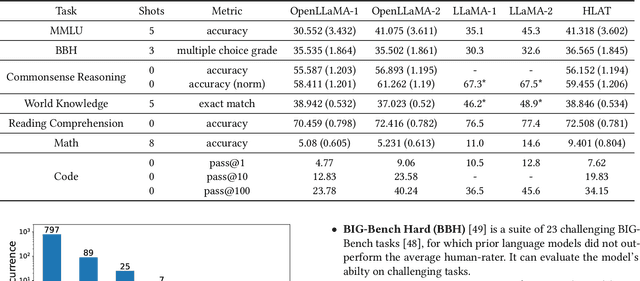
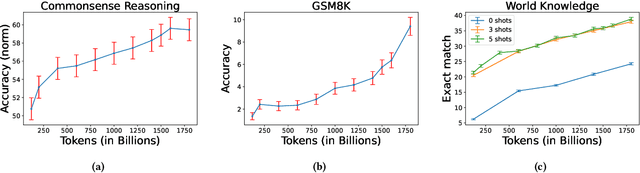
Getting large language models (LLMs) to perform well on the downstream tasks requires pre-training over trillions of tokens. This typically demands a large number of powerful computational devices in addition to a stable distributed training framework to accelerate the training. The growing number of applications leveraging AI/ML had led to a scarcity of the expensive conventional accelerators (such as GPUs), which begs the need for the alternative specialized-accelerators that are scalable and cost-efficient. AWS Trainium is the second-generation machine learning accelerator that has been purposely built for training large deep learning models. Its corresponding instance, Amazon EC2 trn1, is an alternative to GPU instances for LLM training. However, training LLMs with billions of parameters on trn1 is challenging due to its relatively nascent software ecosystem. In this paper, we showcase HLAT: a 7 billion parameter decoder-only LLM pre-trained using trn1 instances over 1.8 trillion tokens. The performance of HLAT is benchmarked against popular open source baseline models including LLaMA and OpenLLaMA, which have been trained on NVIDIA GPUs and Google TPUs, respectively. On various evaluation tasks, we show that HLAT achieves model quality on par with the baselines. We also share the best practice of using the Neuron Distributed Training Library (NDTL), a customized distributed training library for AWS Trainium to achieve efficient training. Our work demonstrates that AWS Trainium powered by the NDTL is able to successfully pre-train state-of-the-art LLM models with high performance and cost-effectiveness.
Neuro-Inspired Information-Theoretic Hierarchical Perception for Multimodal Learning
Apr 15, 2024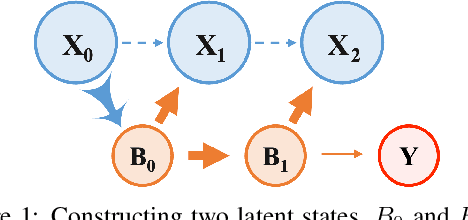
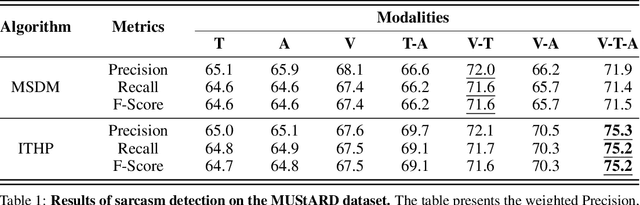
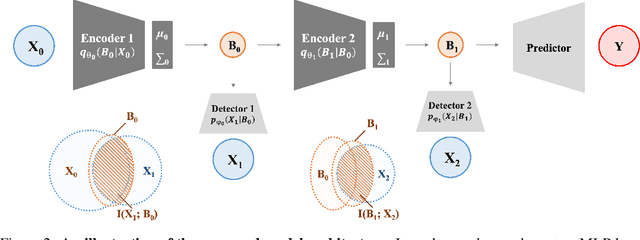

Integrating and processing information from various sources or modalities are critical for obtaining a comprehensive and accurate perception of the real world in autonomous systems and cyber-physical systems. Drawing inspiration from neuroscience, we develop the Information-Theoretic Hierarchical Perception (ITHP) model, which utilizes the concept of information bottleneck. Different from most traditional fusion models that incorporate all modalities identically in neural networks, our model designates a prime modality and regards the remaining modalities as detectors in the information pathway, serving to distill the flow of information. Our proposed perception model focuses on constructing an effective and compact information flow by achieving a balance between the minimization of mutual information between the latent state and the input modal state, and the maximization of mutual information between the latent states and the remaining modal states. This approach leads to compact latent state representations that retain relevant information while minimizing redundancy, thereby substantially enhancing the performance of multimodal representation learning. Experimental evaluations on the MUStARD, CMU-MOSI, and CMU-MOSEI datasets demonstrate that our model consistently distills crucial information in multimodal learning scenarios, outperforming state-of-the-art benchmarks. Remarkably, on the CMU-MOSI dataset, ITHP surpasses human-level performance in the multimodal sentiment binary classification task across all evaluation metrics (i.e., Binary Accuracy, F1 Score, Mean Absolute Error, and Pearson Correlation).
Using Uncertainty Quantification to Characterize and Improve Out-of-Domain Learning for PDEs
Mar 15, 2024



Existing work in scientific machine learning (SciML) has shown that data-driven learning of solution operators can provide a fast approximate alternative to classical numerical partial differential equation (PDE) solvers. Of these, Neural Operators (NOs) have emerged as particularly promising. We observe that several uncertainty quantification (UQ) methods for NOs fail for test inputs that are even moderately out-of-domain (OOD), even when the model approximates the solution well for in-domain tasks. To address this limitation, we show that ensembling several NOs can identify high-error regions and provide good uncertainty estimates that are well-correlated with prediction errors. Based on this, we propose a cost-effective alternative, DiverseNO, that mimics the properties of the ensemble by encouraging diverse predictions from its multiple heads in the last feed-forward layer. We then introduce Operator-ProbConserv, a method that uses these well-calibrated UQ estimates within the ProbConserv framework to update the model. Our empirical results show that Operator-ProbConserv enhances OOD model performance for a variety of challenging PDE problems and satisfies physical constraints such as conservation laws.
Neuro-Inspired Hierarchical Multimodal Learning
Sep 27, 2023



Integrating and processing information from various sources or modalities are critical for obtaining a comprehensive and accurate perception of the real world. Drawing inspiration from neuroscience, we develop the Information-Theoretic Hierarchical Perception (ITHP) model, which utilizes the concept of information bottleneck. Distinct from most traditional fusion models that aim to incorporate all modalities as input, our model designates the prime modality as input, while the remaining modalities act as detectors in the information pathway. Our proposed perception model focuses on constructing an effective and compact information flow by achieving a balance between the minimization of mutual information between the latent state and the input modal state, and the maximization of mutual information between the latent states and the remaining modal states. This approach leads to compact latent state representations that retain relevant information while minimizing redundancy, thereby substantially enhancing the performance of downstream tasks. Experimental evaluations on both the MUStARD and CMU-MOSI datasets demonstrate that our model consistently distills crucial information in multimodal learning scenarios, outperforming state-of-the-art benchmarks.
CAPS: A Practical Partition Index for Filtered Similarity Search
Aug 29, 2023



With the surging popularity of approximate near-neighbor search (ANNS), driven by advances in neural representation learning, the ability to serve queries accompanied by a set of constraints has become an area of intense interest. While the community has recently proposed several algorithms for constrained ANNS, almost all of these methods focus on integration with graph-based indexes, the predominant class of algorithms achieving state-of-the-art performance in latency-recall tradeoffs. In this work, we take a different approach and focus on developing a constrained ANNS algorithm via space partitioning as opposed to graphs. To that end, we introduce Constrained Approximate Partitioned Search (CAPS), an index for ANNS with filters via space partitions that not only retains the benefits of a partition-based algorithm but also outperforms state-of-the-art graph-based constrained search techniques in recall-latency tradeoffs, with only 10% of the index size.