 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Time Series Foundation Models: Towards Explainable and Effective Forecasting
Dec 17, 2025The proliferation of time series foundation models has created a landscape where no single method achieves consistent superiority, framing the central challenge not as finding the best model, but as orchestrating an optimal ensemble with interpretability. While Large Language Models (LLMs) offer powerful reasoning capabilities, their direct application to time series forecasting has proven ineffective. We address this gap by repositioning the LLM as an intelligent judge that evaluates, explains, and strategically coordinates an ensemble of foundation models. To overcome the LLM's inherent lack of domain-specific knowledge on time series, we introduce an R1-style finetuning process, guided by SHAP-based faithfulness scores, which teaches the model to interpret ensemble weights as meaningful causal statements about temporal dynamics. The trained agent then engages in iterative, multi-turn conversations to perform forward-looking assessments, provide causally-grounded explanations for its weighting decisions, and adaptively refine the optimization strategy. Validated on the GIFT-Eval benchmark on 23 datasets across 97 settings, our approach significantly outperforms leading time series foundation models on both CRPS and MASE metrics, establishing new state-of-the-art results.
Foundation Models for Demand Forecasting via Dual-Strategy Ensembling
Jul 29, 2025Accurate demand forecasting is critical for supply chain optimization, yet remains difficult in practice due to hierarchical complexity, domain shifts, and evolving external factors. While recent foundation models offer strong potential for time series forecasting, they often suffer from architectural rigidity and limited robustness under distributional change. In this paper, we propose a unified ensemble framework that enhances the performance of foundation models for sales forecasting in real-world supply chains. Our method combines two complementary strategies: (1) Hierarchical Ensemble (HE), which partitions training and inference by semantic levels (e.g., store, category, department) to capture localized patterns; and (2) Architectural Ensemble (AE), which integrates predictions from diverse model backbones to mitigate bias and improve stability. We conduct extensive experiments on the M5 benchmark and three external sales datasets, covering both in-domain and zero-shot forecasting. Results show that our approach consistently outperforms strong baselines, improves accuracy across hierarchical levels, and provides a simple yet effective mechanism for boosting generalization in complex forecasting environments.
Creating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
Active Sequential Posterior Estimation for Sample-Efficient Simulation-Based Inference
Dec 07, 2024



Computer simulations have long presented the exciting possibility of scientific insight into complex real-world processes. Despite the power of modern computing, however, it remains challenging to systematically perform inference under simulation models. This has led to the rise of simulation-based inference (SBI), a class of machine learning-enabled techniques for approaching inverse problems with stochastic simulators. Many such methods, however, require large numbers of simulation samples and face difficulty scaling to high-dimensional settings, often making inference prohibitive under resource-intensive simulators. To mitigate these drawbacks, we introduce active sequential neural posterior estimation (ASNPE). ASNPE brings an active learning scheme into the inference loop to estimate the utility of simulation parameter candidates to the underlying probabilistic model. The proposed acquisition scheme is easily integrated into existing posterior estimation pipelines, allowing for improved sample efficiency with low computational overhead. We further demonstrate the effectiveness of the proposed method in the travel demand calibration setting, a high-dimensional inverse problem commonly requiring computationally expensive traffic simulators. Our method outperforms well-tuned benchmarks and state-of-the-art posterior estimation methods on a large-scale real-world traffic network, as well as demonstrates a performance advantage over non-active counterparts on a suite of SBI benchmark environments.
Beyond Forecasting: Compositional Time Series Reasoning for End-to-End Task Execution
Oct 08, 2024



In recent decades, there has been substantial advances in time series models and benchmarks across various individual tasks, such as time series forecasting, classification, and anomaly detection. Meanwhile, compositional reasoning in time series is prevalent in real-world applications (e.g., decision-making and compositional question answering) and is in great demand. Unlike simple tasks that primarily focus on predictive accuracy, compositional reasoning emphasizes the synthesis of diverse information from both time series data and various domain knowledge, making it distinct and extremely more challenging. In this paper, we introduce Compositional Time Series Reasoning, a new task of handling intricate multistep reasoning tasks from time series data. Specifically, this new task focuses on various question instances requiring structural and compositional reasoning abilities on time series data, such as decision-making and compositional question answering. As an initial attempt to tackle this novel task, we developed TS-Reasoner, a program-aided approach that utilizes large language model (LLM) to decompose a complex task into steps of programs that leverage existing time series models and numerical subroutines. Unlike existing reasoning work which only calls off-the-shelf modules, TS-Reasoner allows for the creation of custom modules and provides greater flexibility to incorporate domain knowledge as well as user-specified constraints. We demonstrate the effectiveness of our method through a comprehensive set of experiments. These promising results indicate potential opportunities in the new task of time series reasoning and highlight the need for further research.
TimeDiT: General-purpose Diffusion Transformers for Time Series Foundation Model
Sep 03, 2024



With recent advances in building foundation models for texts and video data, there is a surge of interest in foundation models for time series. A family of models have been developed, utilizing a temporal auto-regressive generative Transformer architecture, whose effectiveness has been proven in Large Language Models. While the empirical results are promising, almost all existing time series foundation models have only been tested on well-curated ``benchmark'' datasets very similar to texts. However, real-world time series exhibit unique challenges, such as variable channel sizes across domains, missing values, and varying signal sampling intervals due to the multi-resolution nature of real-world data. Additionally, the uni-directional nature of temporally auto-regressive decoding limits the incorporation of domain knowledge, such as physical laws expressed as partial differential equations (PDEs). To address these challenges, we introduce the Time Diffusion Transformer (TimeDiT), a general foundation model for time series that employs a denoising diffusion paradigm instead of temporal auto-regressive generation. TimeDiT leverages the Transformer architecture to capture temporal dependencies and employs diffusion processes to generate high-quality candidate samples without imposing stringent assumptions on the target distribution via novel masking schemes and a channel alignment strategy. Furthermore, we propose a finetuning-free model editing strategy that allows the seamless integration of external knowledge during the sampling process without updating any model parameters. Extensive experiments conducted on a varity of tasks such as forecasting, imputation, and anomaly detection, demonstrate the effectiveness of TimeDiT.
An Empirical Examination of Balancing Strategy for Counterfactual Estimation on Time Series
Aug 16, 2024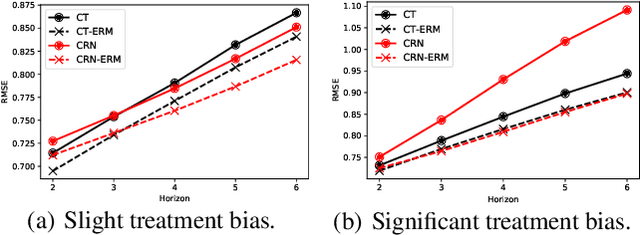
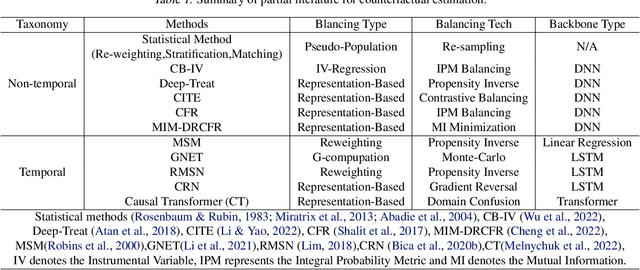
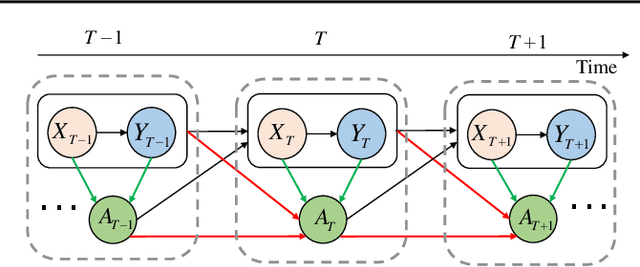
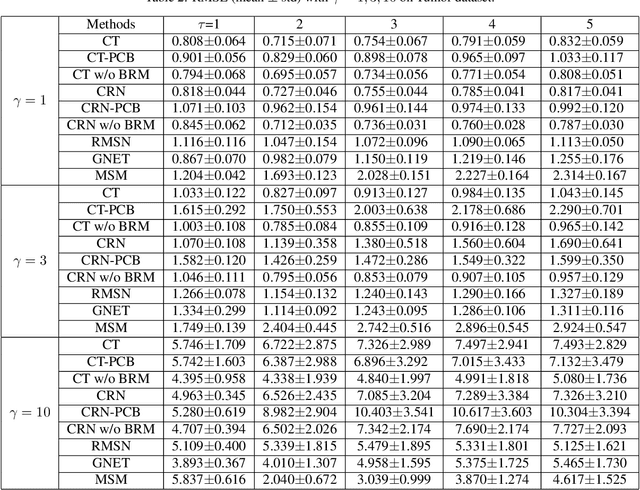
Counterfactual estimation from observations represents a critical endeavor in numerous application fields, such as healthcare and finance, with the primary challenge being the mitigation of treatment bias. The balancing strategy aimed at reducing covariate disparities between different treatment groups serves as a universal solution. However, when it comes to the time series data, the effectiveness of balancing strategies remains an open question, with a thorough analysis of the robustness and applicability of balancing strategies still lacking. This paper revisits counterfactual estimation in the temporal setting and provides a brief overview of recent advancements in balancing strategies. More importantly, we conduct a critical empirical examination for the effectiveness of the balancing strategies within the realm of temporal counterfactual estimation in various settings on multiple datasets. Our findings could be of significant interest to researchers and practitioners and call for a reexamination of the balancing strategy in time series settings.
MuGSI: Distilling GNNs with Multi-Granularity Structural Information for Graph Classification
Jun 28, 2024



Recent works have introduced GNN-to-MLP knowledge distillation (KD) frameworks to combine both GNN's superior performance and MLP's fast inference speed. However, existing KD frameworks are primarily designed for node classification within single graphs, leaving their applicability to graph classification largely unexplored. Two main challenges arise when extending KD for node classification to graph classification: (1) The inherent sparsity of learning signals due to soft labels being generated at the graph level; (2) The limited expressiveness of student MLPs, especially in datasets with limited input feature spaces. To overcome these challenges, we introduce MuGSI, a novel KD framework that employs Multi-granularity Structural Information for graph classification. Specifically, we propose multi-granularity distillation loss in MuGSI to tackle the first challenge. This loss function is composed of three distinct components: graph-level distillation, subgraph-level distillation, and node-level distillation. Each component targets a specific granularity of the graph structure, ensuring a comprehensive transfer of structural knowledge from the teacher model to the student model. To tackle the second challenge, MuGSI proposes to incorporate a node feature augmentation component, thereby enhancing the expressiveness of the student MLPs and making them more capable learners. We perform extensive experiments across a variety of datasets and different teacher/student model architectures. The experiment results demonstrate the effectiveness, efficiency, and robustness of MuGSI. Codes are publicly available at: \textbf{\url{https://github.com/tianyao-aka/MuGSI}.}
Neuro-Inspired Information-Theoretic Hierarchical Perception for Multimodal Learning
Apr 15, 2024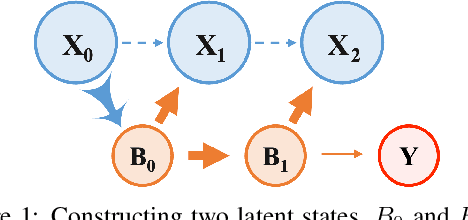
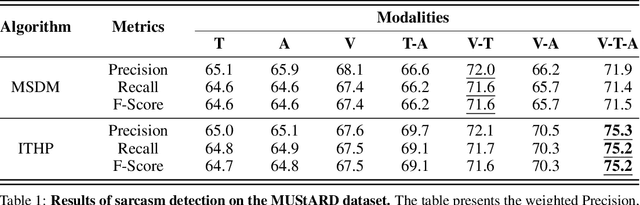
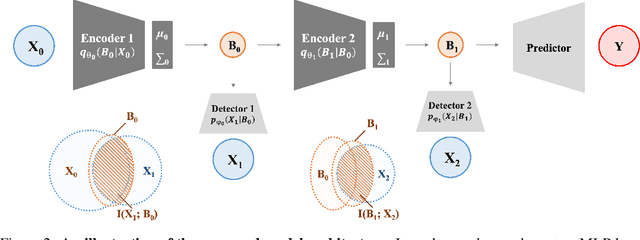

Integrating and processing information from various sources or modalities are critical for obtaining a comprehensive and accurate perception of the real world in autonomous systems and cyber-physical systems. Drawing inspiration from neuroscience, we develop the Information-Theoretic Hierarchical Perception (ITHP) model, which utilizes the concept of information bottleneck. Different from most traditional fusion models that incorporate all modalities identically in neural networks, our model designates a prime modality and regards the remaining modalities as detectors in the information pathway, serving to distill the flow of information. Our proposed perception model focuses on constructing an effective and compact information flow by achieving a balance between the minimization of mutual information between the latent state and the input modal state, and the maximization of mutual information between the latent states and the remaining modal states. This approach leads to compact latent state representations that retain relevant information while minimizing redundancy, thereby substantially enhancing the performance of multimodal representation learning. Experimental evaluations on the MUStARD, CMU-MOSI, and CMU-MOSEI datasets demonstrate that our model consistently distills crucial information in multimodal learning scenarios, outperforming state-of-the-art benchmarks. Remarkably, on the CMU-MOSI dataset, ITHP surpasses human-level performance in the multimodal sentiment binary classification task across all evaluation metrics (i.e., Binary Accuracy, F1 Score, Mean Absolute Error, and Pearson Correlation).
Exploring Neuron Interactions and Emergence in LLMs: From the Multifractal Analysis Perspective
Feb 14, 2024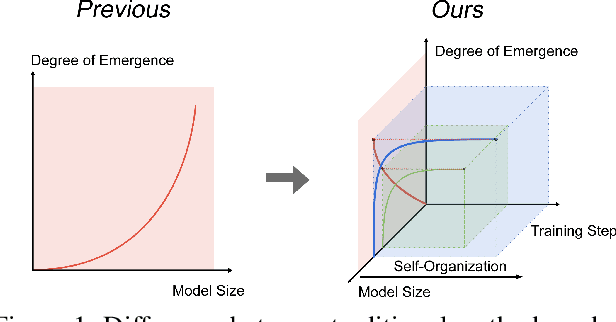
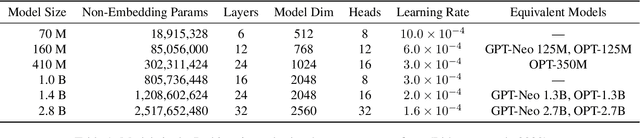

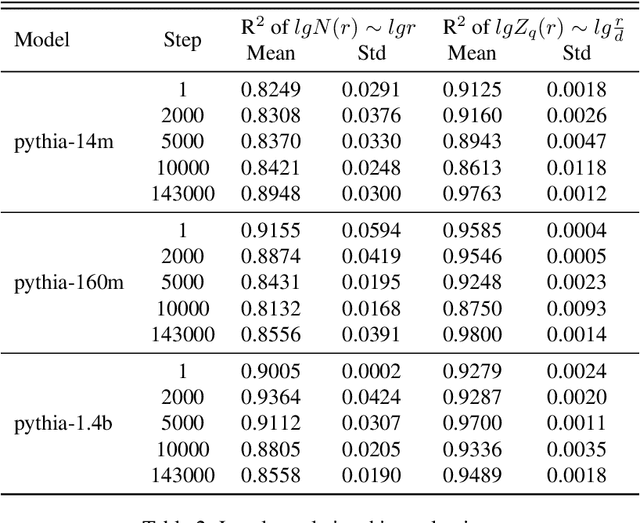
Prior studies on the emergence in large models have primarily focused on how the functional capabilities of large language models (LLMs) scale with model size. Our research, however, transcends this traditional paradigm, aiming to deepen our understanding of the emergence within LLMs by placing a special emphasis not just on the model size but more significantly on the complex behavior of neuron interactions during the training process. By introducing the concepts of "self-organization" and "multifractal analysis," we explore how neuron interactions dynamically evolve during training, leading to "emergence," mirroring the phenomenon in natural systems where simple micro-level interactions give rise to complex macro-level behaviors. To quantitatively analyze the continuously evolving interactions among neurons in large models during training, we propose the Neuron-based Multifractal Analysis (NeuroMFA). Utilizing NeuroMFA, we conduct a comprehensive examination of the emergent behavior in LLMs through the lens of both model size and training process, paving new avenues for research into the emergence in large models.