 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Embeddings Outperforms Scaling Experts in Language Models
Jan 29, 2026While Mixture-of-Experts (MoE) architectures have become the standard for sparsity scaling in large language models, they increasingly face diminishing returns and system-level bottlenecks. In this work, we explore embedding scaling as a potent, orthogonal dimension for scaling sparsity. Through a comprehensive analysis and experiments, we identify specific regimes where embedding scaling achieves a superior Pareto frontier compared to expert scaling. We systematically characterize the critical architectural factors governing this efficacy -- ranging from parameter budgeting to the interplay with model width and depth. Moreover, by integrating tailored system optimizations and speculative decoding, we effectively convert this sparsity into tangible inference speedups. Guided by these insights, we introduce LongCat-Flash-Lite, a 68.5B parameter model with ~3B activated trained from scratch. Despite allocating over 30B parameters to embeddings, LongCat-Flash-Lite not only surpasses parameter-equivalent MoE baselines but also exhibits exceptional competitiveness against existing models of comparable scale, particularly in agentic and coding domains.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Score-based Greedy Search for Structure Identification of Partially Observed Linear Causal Models
Oct 05, 2025Identifying the structure of a partially observed causal system is essential to various scientific fields. Recent advances have focused on constraint-based causal discovery to solve this problem, and yet in practice these methods often face challenges related to multiple testing and error propagation. These issues could be mitigated by a score-based method and thus it has raised great attention whether there exists a score-based greedy search method that can handle the partially observed scenario. In this work, we propose the first score-based greedy search method for the identification of structure involving latent variables with identifiability guarantees. Specifically, we propose Generalized N Factor Model and establish the global consistency: the true structure including latent variables can be identified up to the Markov equivalence class by using score. We then design Latent variable Greedy Equivalence Search (LGES), a greedy search algorithm for this class of model with well-defined operators, which search very efficiently over the graph space to find the optimal structure. Our experiments on both synthetic and real-life data validate the effectiveness of our method (code will be publicly available).
LKD-KGC: Domain-Specific KG Construction via LLM-driven Knowledge Dependency Parsing
May 30, 2025Knowledge Graphs (KGs) structure real-world entities and their relationships into triples, enhancing machine reasoning for various tasks. While domain-specific KGs offer substantial benefits, their manual construction is often inefficient and requires specialized knowledge. Recent approaches for knowledge graph construction (KGC) based on large language models (LLMs), such as schema-guided KGC and reference knowledge integration, have proven efficient. However, these methods are constrained by their reliance on manually defined schema, single-document processing, and public-domain references, making them less effective for domain-specific corpora that exhibit complex knowledge dependencies and specificity, as well as limited reference knowledge. To address these challenges, we propose LKD-KGC, a novel framework for unsupervised domain-specific KG construction. LKD-KGC autonomously analyzes document repositories to infer knowledge dependencies, determines optimal processing sequences via LLM driven prioritization, and autoregressively generates entity schema by integrating hierarchical inter-document contexts. This schema guides the unsupervised extraction of entities and relationships, eliminating reliance on predefined structures or external knowledge. Extensive experiments show that compared with state-of-the-art baselines, LKD-KGC generally achieves improvements of 10% to 20% in both precision and recall rate, demonstrating its potential in constructing high-quality domain-specific KGs.
Type Information-Assisted Self-Supervised Knowledge Graph Denoising
Mar 13, 2025Knowledge graphs serve as critical resources supporting intelligent systems, but they can be noisy due to imperfect automatic generation processes. Existing approaches to noise detection often rely on external facts, logical rule constraints, or structural embeddings. These methods are often challenged by imperfect entity alignment, flexible knowledge graph construction, and overfitting on structures. In this paper, we propose to exploit the consistency between entity and relation type information for noise detection, resulting a novel self-supervised knowledge graph denoising method that avoids those problems. We formalize type inconsistency noise as triples that deviate from the majority with respect to type-dependent reasoning along the topological structure. Specifically, we first extract a compact representation of a given knowledge graph via an encoder that models the type dependencies of triples. Then, the decoder reconstructs the original input knowledge graph based on the compact representation. It is worth noting that, our proposal has the potential to address the problems of knowledge graph compression and completion, although this is not our focus. For the specific task of noise detection, the discrepancy between the reconstruction results and the input knowledge graph provides an opportunity for denoising, which is facilitated by the type consistency embedded in our method. Experimental validation demonstrates the effectiveness of our approach in detecting potential noise in real-world data.
Practical Marketplace Optimization at Uber Using Causally-Informed Machine Learning
Jul 26, 2024



Budget allocation of marketplace levers, such as incentives for drivers and promotions for riders, has long been a technical and business challenge at Uber; understanding lever budget changes' impact and estimating cost efficiency to achieve predefined budgets is crucial, with the goal of optimal allocations that maximize business value; we introduce an end-to-end machine learning and optimization procedure to automate budget decision-making for cities, relying on feature store, model training and serving, optimizers, and backtesting; proposing state-of-the-art deep learning (DL) estimator based on S-Learner and a novel tensor B-Spline regression model, we solve high-dimensional optimization with ADMM and primal-dual interior point convex optimization, substantially improving Uber's resource allocation efficiency.
MuGSI: Distilling GNNs with Multi-Granularity Structural Information for Graph Classification
Jun 28, 2024



Recent works have introduced GNN-to-MLP knowledge distillation (KD) frameworks to combine both GNN's superior performance and MLP's fast inference speed. However, existing KD frameworks are primarily designed for node classification within single graphs, leaving their applicability to graph classification largely unexplored. Two main challenges arise when extending KD for node classification to graph classification: (1) The inherent sparsity of learning signals due to soft labels being generated at the graph level; (2) The limited expressiveness of student MLPs, especially in datasets with limited input feature spaces. To overcome these challenges, we introduce MuGSI, a novel KD framework that employs Multi-granularity Structural Information for graph classification. Specifically, we propose multi-granularity distillation loss in MuGSI to tackle the first challenge. This loss function is composed of three distinct components: graph-level distillation, subgraph-level distillation, and node-level distillation. Each component targets a specific granularity of the graph structure, ensuring a comprehensive transfer of structural knowledge from the teacher model to the student model. To tackle the second challenge, MuGSI proposes to incorporate a node feature augmentation component, thereby enhancing the expressiveness of the student MLPs and making them more capable learners. We perform extensive experiments across a variety of datasets and different teacher/student model architectures. The experiment results demonstrate the effectiveness, efficiency, and robustness of MuGSI. Codes are publicly available at: \textbf{\url{https://github.com/tianyao-aka/MuGSI}.}
Progressive Knowledge Graph Completion
Apr 15, 2024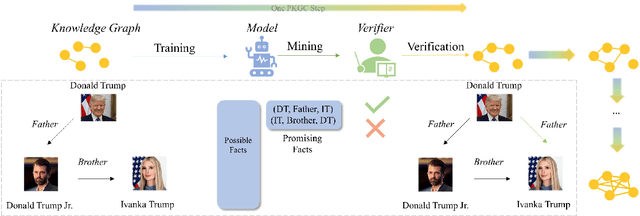

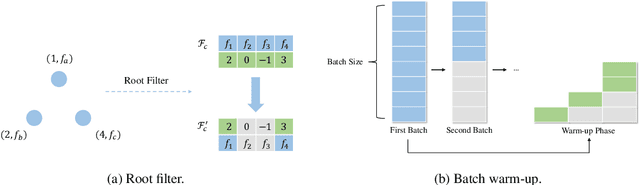

Knowledge Graph Completion (KGC) has emerged as a promising solution to address the issue of incompleteness within Knowledge Graphs (KGs). Traditional KGC research primarily centers on triple classification and link prediction. Nevertheless, we contend that these tasks do not align well with real-world scenarios and merely serve as surrogate benchmarks. In this paper, we investigate three crucial processes relevant to real-world construction scenarios: (a) the verification process, which arises from the necessity and limitations of human verifiers; (b) the mining process, which identifies the most promising candidates for verification; and (c) the training process, which harnesses verified data for subsequent utilization; in order to achieve a transition toward more realistic challenges. By integrating these three processes, we introduce the Progressive Knowledge Graph Completion (PKGC) task, which simulates the gradual completion of KGs in real-world scenarios. Furthermore, to expedite PKGC processing, we propose two acceleration modules: Optimized Top-$k$ algorithm and Semantic Validity Filter. These modules significantly enhance the efficiency of the mining procedure. Our experiments demonstrate that performance in link prediction does not accurately reflect performance in PKGC. A more in-depth analysis reveals the key factors influencing the results and provides potential directions for future research.
Prior Bilinear Based Models for Knowledge Graph Completion
Sep 25, 2023Bilinear based models are powerful and widely used approaches for Knowledge Graphs Completion (KGC). Although bilinear based models have achieved significant advances, these studies mainly concentrate on posterior properties (based on evidence, e.g. symmetry pattern) while neglecting the prior properties. In this paper, we find a prior property named "the law of identity" that cannot be captured by bilinear based models, which hinders them from comprehensively modeling the characteristics of KGs. To address this issue, we introduce a solution called Unit Ball Bilinear Model (UniBi). This model not only achieves theoretical superiority but also offers enhanced interpretability and performance by minimizing ineffective learning through minimal constraints. Experiments demonstrate that UniBi models the prior property and verify its interpretability and performance.
D2Match: Leveraging Deep Learning and Degeneracy for Subgraph Matching
Jun 10, 2023



Subgraph matching is a fundamental building block for graph-based applications and is challenging due to its high-order combinatorial nature. Existing studies usually tackle it by combinatorial optimization or learning-based methods. However, they suffer from exponential computational costs or searching the matching without theoretical guarantees. In this paper, we develop D2Match by leveraging the efficiency of Deep learning and Degeneracy for subgraph matching. More specifically, we first prove that subgraph matching can degenerate to subtree matching, and subsequently is equivalent to finding a perfect matching on a bipartite graph. We can then yield an implementation of linear time complexity by the built-in tree-structured aggregation mechanism on graph neural networks. Moreover, circle structures and node attributes can be easily incorporated in D2Match to boost the matching performance. Finally, we conduct extensive experiments to show the superior performance of our D2Match and confirm that our D2Match indeed exploits the subtrees and differs from existing GNNs-based subgraph matching methods that depend on memorizing the data distribution divergence