 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCostal Cartilage Segmentation with Topology Guided Deformable Mamba: Method and Benchmark
Aug 14, 2024



Costal cartilage segmentation is crucial to various medical applications, necessitating precise and reliable techniques due to its complex anatomy and the importance of accurate diagnosis and surgical planning. We propose a novel deep learning-based approach called topology-guided deformable Mamba (TGDM) for costal cartilage segmentation. The TGDM is tailored to capture the intricate long-range costal cartilage relationships. Our method leverages a deformable model that integrates topological priors to enhance the adaptability and accuracy of the segmentation process. Furthermore, we developed a comprehensive benchmark that contains 165 cases for costal cartilage segmentation. This benchmark sets a new standard for evaluating costal cartilage segmentation techniques and provides a valuable resource for future research. Extensive experiments conducted on both in-domain benchmarks and out-of domain test sets demonstrate the superiority of our approach over existing methods, showing significant improvements in segmentation precision and robustness.
Do Not Train It: A Linear Neural Architecture Search of Graph Neural Networks
May 23, 2023



Neural architecture search (NAS) for Graph neural networks (GNNs), called NAS-GNNs, has achieved significant performance over manually designed GNN architectures. However, these methods inherit issues from the conventional NAS methods, such as high computational cost and optimization difficulty. More importantly, previous NAS methods have ignored the uniqueness of GNNs, where GNNs possess expressive power without training. With the randomly-initialized weights, we can then seek the optimal architecture parameters via the sparse coding objective and derive a novel NAS-GNNs method, namely neural architecture coding (NAC). Consequently, our NAC holds a no-update scheme on GNNs and can efficiently compute in linear time. Empirical evaluations on multiple GNN benchmark datasets demonstrate that our approach leads to state-of-the-art performance, which is up to $200\times$ faster and $18.8\%$ more accurate than the strong baselines.
EmotionX-DLC: Self-Attentive BiLSTM for Detecting Sequential Emotions in Dialogue
Jun 20, 2018

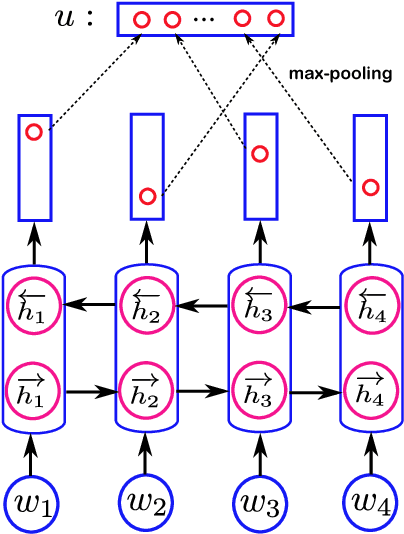
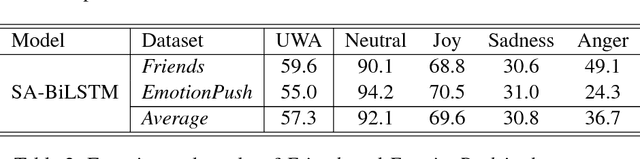
In this paper, we propose a self-attentive bidirectional long short-term memory (SA-BiLSTM) network to predict multiple emotions for the EmotionX challenge. The BiLSTM exhibits the power of modeling the word dependencies, and extracting the most relevant features for emotion classification. Building on top of BiLSTM, the self-attentive network can model the contextual dependencies between utterances which are helpful for classifying the ambiguous emotions. We achieve 59.6 and 55.0 unweighted accuracy scores in the \textit{Friends} and the \textit{EmotionPush} test sets, respectively.