 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCostal Cartilage Segmentation with Topology Guided Deformable Mamba: Method and Benchmark
Aug 14, 2024



Costal cartilage segmentation is crucial to various medical applications, necessitating precise and reliable techniques due to its complex anatomy and the importance of accurate diagnosis and surgical planning. We propose a novel deep learning-based approach called topology-guided deformable Mamba (TGDM) for costal cartilage segmentation. The TGDM is tailored to capture the intricate long-range costal cartilage relationships. Our method leverages a deformable model that integrates topological priors to enhance the adaptability and accuracy of the segmentation process. Furthermore, we developed a comprehensive benchmark that contains 165 cases for costal cartilage segmentation. This benchmark sets a new standard for evaluating costal cartilage segmentation techniques and provides a valuable resource for future research. Extensive experiments conducted on both in-domain benchmarks and out-of domain test sets demonstrate the superiority of our approach over existing methods, showing significant improvements in segmentation precision and robustness.
Exploring RNN-Transducer for Chinese Speech Recognition
Nov 13, 2018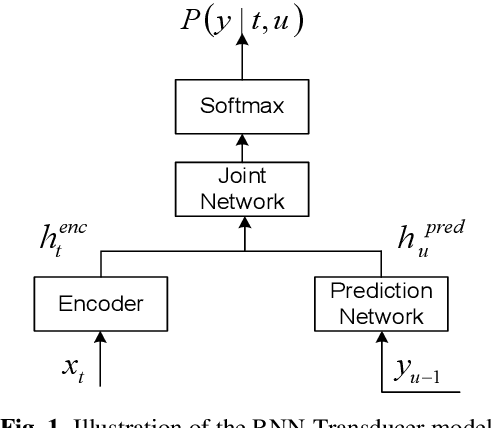
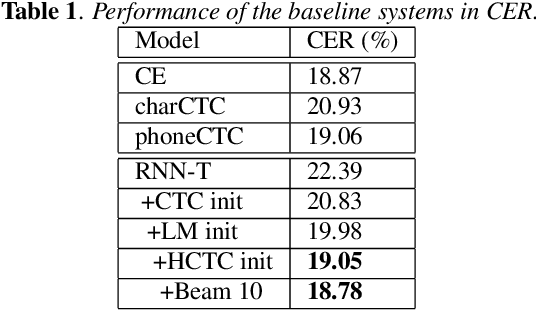
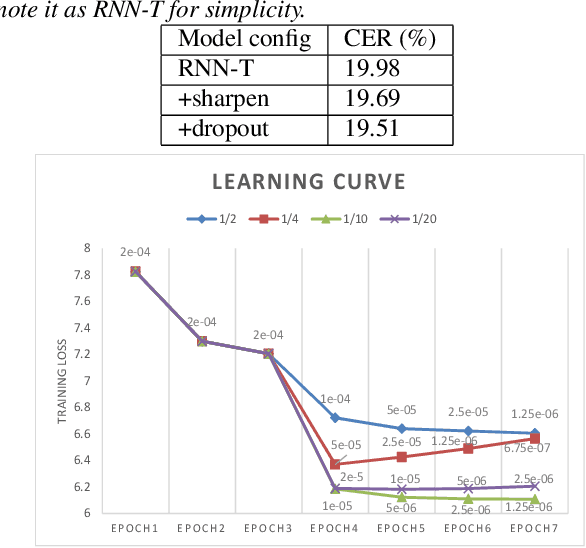
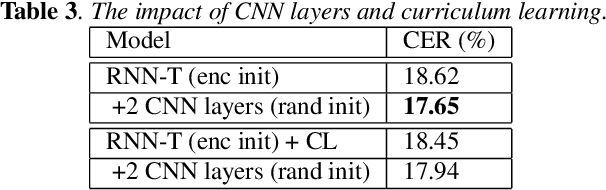
End-to-end approaches have drawn much attention recently for significantly simplifying the construction of an automatic speech recognition (ASR) system. RNN transducer (RNN-T) is one of the popular end-to-end methods. Previous studies have shown that RNN-T is difficult to train and a very complex training process is needed for a reasonable performance. In this paper, we explore RNN-T for a Chinese large vocabulary continuous speech recognition (LVCSR) task and aim to simplify the training process while maintaining performance. First, a new strategy of learning rate decay is proposed to accelerate the model convergence. Second, we find that adding convolutional layers at the beginning of the network and using ordered data can discard the pre-training process of the encoder without loss of performance. Besides, we design experiments to find a balance among the usage of GPU memory, training circle and model performance. Finally, we achieve 16.9% character error rate (CER) on our test set which is 2% absolute improvement from a strong BLSTM CE system with language model trained on the same text corpus.