 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAR RL Done Right: Tackling Asynchronous Policy Conflicts in Visual Autoregressive Generation
Jan 05, 2026Visual generation is dominated by three paradigms: AutoRegressive (AR), diffusion, and Visual AutoRegressive (VAR) models. Unlike AR and diffusion, VARs operate on heterogeneous input structures across their generation steps, which creates severe asynchronous policy conflicts. This issue becomes particularly acute in reinforcement learning (RL) scenarios, leading to unstable training and suboptimal alignment. To resolve this, we propose a novel framework to enhance Group Relative Policy Optimization (GRPO) by explicitly managing these conflicts. Our method integrates three synergistic components: 1) a stabilizing intermediate reward to guide early-stage generation; 2) a dynamic time-step reweighting scheme for precise credit assignment; and 3) a novel mask propagation algorithm, derived from principles of Reward Feedback Learning (ReFL), designed to isolate optimization effects both spatially and temporally. Our approach demonstrates significant improvements in sample quality and objective alignment over the vanilla GRPO baseline, enabling robust and effective optimization for VAR models.
PP-Motion: Physical-Perceptual Fidelity Evaluation for Human Motion Generation
Aug 11, 2025Human motion generation has found widespread applications in AR/VR, film, sports, and medical rehabilitation, offering a cost-effective alternative to traditional motion capture systems. However, evaluating the fidelity of such generated motions is a crucial, multifaceted task. Although previous approaches have attempted at motion fidelity evaluation using human perception or physical constraints, there remains an inherent gap between human-perceived fidelity and physical feasibility. Moreover, the subjective and coarse binary labeling of human perception further undermines the development of a robust data-driven metric. We address these issues by introducing a physical labeling method. This method evaluates motion fidelity by calculating the minimum modifications needed for a motion to align with physical laws. With this approach, we are able to produce fine-grained, continuous physical alignment annotations that serve as objective ground truth. With these annotations, we propose PP-Motion, a novel data-driven metric to evaluate both physical and perceptual fidelity of human motion. To effectively capture underlying physical priors, we employ Pearson's correlation loss for the training of our metric. Additionally, by incorporating a human-based perceptual fidelity loss, our metric can capture fidelity that simultaneously considers both human perception and physical alignment. Experimental results demonstrate that our metric, PP-Motion, not only aligns with physical laws but also aligns better with human perception of motion fidelity than previous work.
UDuo: Universal Dual Optimization Framework for Online Matching
May 28, 2025Online resource allocation under budget constraints critically depends on proper modeling of user arrival dynamics. Classical approaches employ stochastic user arrival models to derive near-optimal solutions through fractional matching formulations of exposed users for downstream allocation tasks. However, this is no longer a reasonable assumption when the environment changes dynamically. In this work, We propose the Universal Dual optimization framework UDuo, a novel paradigm that fundamentally rethinks online allocation through three key innovations: (i) a temporal user arrival representation vector that explicitly captures distribution shifts in user arrival patterns and resource consumption dynamics, (ii) a resource pacing learner with adaptive allocation policies that generalize to heterogeneous constraint scenarios, and (iii) an online time-series forecasting approach for future user arrival distributions that achieves asymptotically optimal solutions with constraint feasibility guarantees in dynamic environments. Experimental results show that UDuo achieves higher efficiency and faster convergence than the traditional stochastic arrival model in real-world pricing while maintaining rigorous theoretical validity for general online allocation problems.
Pre-train and Fine-tune: Recommenders as Large Models
Jan 24, 2025



In reality, users have different interests in different periods, regions, scenes, etc. Such changes in interest are so drastic that they are difficult to be captured by recommenders. Existing multi-domain learning can alleviate this problem. However, the structure of the industrial recommendation system is complex, the amount of data is huge, and the training cost is extremely high, so it is difficult to modify the structure of the industrial recommender and re-train it. To fill this gap, we consider recommenders as large pre-trained models and fine-tune them. We first propose the theory of the information bottleneck for fine-tuning and present an explanation for the fine-tuning technique in recommenders. To tailor for recommendation, we design an information-aware adaptive kernel (IAK) technique to fine-tune the pre-trained recommender. Specifically, we define fine-tuning as two phases: knowledge compression and knowledge matching and let the training stage of IAK explicitly approximate these two phases. Our proposed approach designed from the essence of fine-tuning is well interpretable. Extensive online and offline experiments show the superiority of our proposed method. Besides, we also share unique and important lessons we learned when deploying the method in a large-scale online platform. We also present the potential issues of fine-tuning techniques in recommendation systems and the corresponding solutions. The recommender with IAK technique has been deployed on the homepage of a billion-scale online food platform for several months and has yielded considerable profits in our business.
Disambiguation of Chinese Polyphones in an End-to-End Framework with Semantic Features Extracted by Pre-trained BERT
Jan 02, 2025



Grapheme-to-phoneme (G2P) conversion serves as an essential component in Chinese Mandarin text-to-speech (TTS) system, where polyphone disambiguation is the core issue. In this paper, we propose an end-to-end framework to predict the pronunciation of a polyphonic character, which accepts sentence containing polyphonic character as input in the form of Chinese character sequence without the necessity of any preprocessing. The proposed method consists of a pre-trained bidirectional encoder representations from Transformers (BERT) model and a neural network (NN) based classifier. The pre-trained BERT model extracts semantic features from a raw Chinese character sequence and the NN based classifier predicts the polyphonic character's pronunciation according to BERT output. In out experiments, we implemented three classifiers, a fully-connected network based classifier, a long short-term memory (LSTM) network based classifier and a Transformer block based classifier. The experimental results compared with the baseline approach based on LSTM demonstrate that, the pre-trained model extracts effective semantic features, which greatly enhances the performance of polyphone disambiguation. In addition, we also explored the impact of contextual information on polyphone disambiguation.
* Accepted at INTERSPEECH 2019
learning discriminative features from spectrograms using center loss for speech emotion recognition
Jan 02, 2025Identifying the emotional state from speech is essential for the natural interaction of the machine with the speaker. However, extracting effective features for emotion recognition is difficult, as emotions are ambiguous. We propose a novel approach to learn discriminative features from variable length spectrograms for emotion recognition by cooperating softmax cross-entropy loss and center loss together. The softmax cross-entropy loss enables features from different emotion categories separable, and center loss efficiently pulls the features belonging to the same emotion category to their center. By combining the two losses together, the discriminative power will be highly enhanced, which leads to network learning more effective features for emotion recognition. As demonstrated by the experimental results, after introducing center loss, both the unweighted accuracy and weighted accuracy are improved by over 3\% on Mel-spectrogram input, and more than 4\% on Short Time Fourier Transform spectrogram input.
* Accepted at ICASSP 2019
Skinned Motion Retargeting with Dense Geometric Interaction Perception
Oct 28, 2024Capturing and maintaining geometric interactions among different body parts is crucial for successful motion retargeting in skinned characters. Existing approaches often overlook body geometries or add a geometry correction stage after skeletal motion retargeting. This results in conflicts between skeleton interaction and geometry correction, leading to issues such as jittery, interpenetration, and contact mismatches. To address these challenges, we introduce a new retargeting framework, MeshRet, which directly models the dense geometric interactions in motion retargeting. Initially, we establish dense mesh correspondences between characters using semantically consistent sensors (SCS), effective across diverse mesh topologies. Subsequently, we develop a novel spatio-temporal representation called the dense mesh interaction (DMI) field. This field, a collection of interacting SCS feature vectors, skillfully captures both contact and non-contact interactions between body geometries. By aligning the DMI field during retargeting, MeshRet not only preserves motion semantics but also prevents self-interpenetration and ensures contact preservation. Extensive experiments on the public Mixamo dataset and our newly-collected ScanRet dataset demonstrate that MeshRet achieves state-of-the-art performance. Code available at https://github.com/abcyzj/MeshRet.
Embedding an Ethical Mind: Aligning Text-to-Image Synthesis via Lightweight Value Optimization
Oct 16, 2024



Recent advancements in diffusion models trained on large-scale data have enabled the generation of indistinguishable human-level images, yet they often produce harmful content misaligned with human values, e.g., social bias, and offensive content. Despite extensive research on Large Language Models (LLMs), the challenge of Text-to-Image (T2I) model alignment remains largely unexplored. Addressing this problem, we propose LiVO (Lightweight Value Optimization), a novel lightweight method for aligning T2I models with human values. LiVO only optimizes a plug-and-play value encoder to integrate a specified value principle with the input prompt, allowing the control of generated images over both semantics and values. Specifically, we design a diffusion model-tailored preference optimization loss, which theoretically approximates the Bradley-Terry model used in LLM alignment but provides a more flexible trade-off between image quality and value conformity. To optimize the value encoder, we also develop a framework to automatically construct a text-image preference dataset of 86k (prompt, aligned image, violating image, value principle) samples. Without updating most model parameters and through adaptive value selection from the input prompt, LiVO significantly reduces harmful outputs and achieves faster convergence, surpassing several strong baselines and taking an initial step towards ethically aligned T2I models.
VERIFIED: A Video Corpus Moment Retrieval Benchmark for Fine-Grained Video Understanding
Oct 11, 2024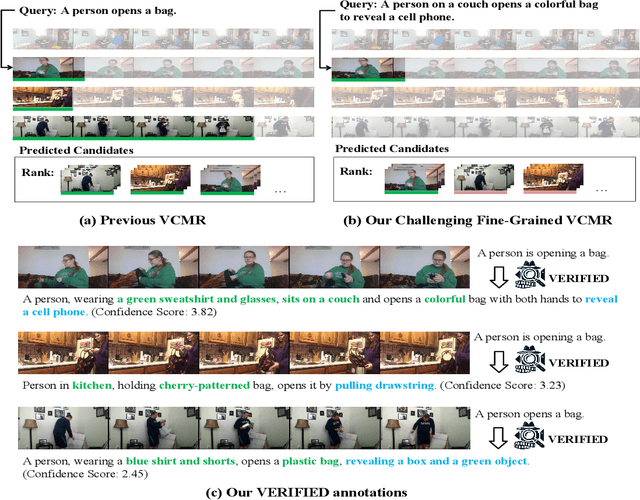



Existing Video Corpus Moment Retrieval (VCMR) is limited to coarse-grained understanding, which hinders precise video moment localization when given fine-grained queries. In this paper, we propose a more challenging fine-grained VCMR benchmark requiring methods to localize the best-matched moment from the corpus with other partially matched candidates. To improve the dataset construction efficiency and guarantee high-quality data annotations, we propose VERIFIED, an automatic \underline{V}id\underline{E}o-text annotation pipeline to generate captions with \underline{R}el\underline{I}able \underline{FI}n\underline{E}-grained statics and \underline{D}ynamics. Specifically, we resort to large language models (LLM) and large multimodal models (LMM) with our proposed Statics and Dynamics Enhanced Captioning modules to generate diverse fine-grained captions for each video. To filter out the inaccurate annotations caused by the LLM hallucination, we propose a Fine-Granularity Aware Noise Evaluator where we fine-tune a video foundation model with disturbed hard-negatives augmented contrastive and matching losses. With VERIFIED, we construct a more challenging fine-grained VCMR benchmark containing Charades-FIG, DiDeMo-FIG, and ActivityNet-FIG which demonstrate a high level of annotation quality. We evaluate several state-of-the-art VCMR models on the proposed dataset, revealing that there is still significant scope for fine-grained video understanding in VCMR. Code and Datasets are in \href{https://github.com/hlchen23/VERIFIED}{https://github.com/hlchen23/VERIFIED}.
VoxInstruct: Expressive Human Instruction-to-Speech Generation with Unified Multilingual Codec Language Modelling
Aug 28, 2024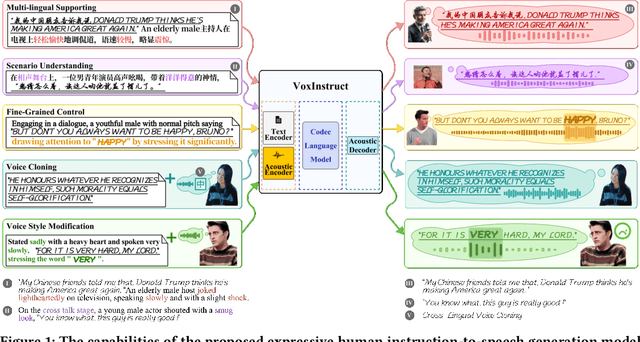

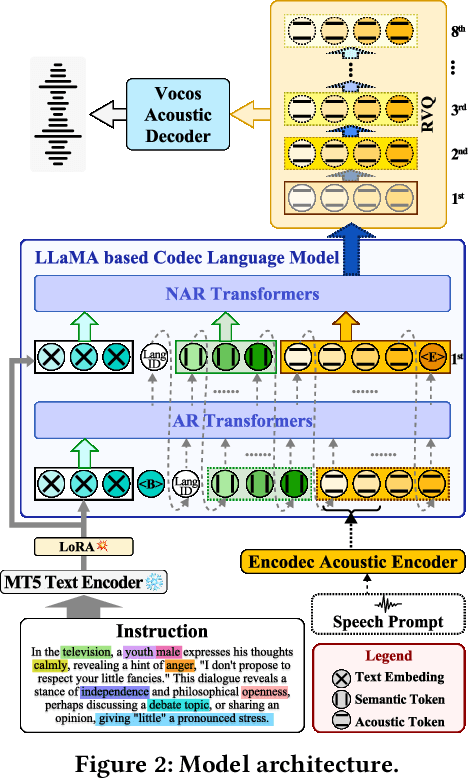

Recent AIGC systems possess the capability to generate digital multimedia content based on human language instructions, such as text, image and video. However, when it comes to speech, existing methods related to human instruction-to-speech generation exhibit two limitations. Firstly, they require the division of inputs into content prompt (transcript) and description prompt (style and speaker), instead of directly supporting human instruction. This division is less natural in form and does not align with other AIGC models. Secondly, the practice of utilizing an independent description prompt to model speech style, without considering the transcript content, restricts the ability to control speech at a fine-grained level. To address these limitations, we propose VoxInstruct, a novel unified multilingual codec language modeling framework that extends traditional text-to-speech tasks into a general human instruction-to-speech task. Our approach enhances the expressiveness of human instruction-guided speech generation and aligns the speech generation paradigm with other modalities. To enable the model to automatically extract the content of synthesized speech from raw text instructions, we introduce speech semantic tokens as an intermediate representation for instruction-to-content guidance. We also incorporate multiple Classifier-Free Guidance (CFG) strategies into our codec language model, which strengthens the generated speech following human instructions. Furthermore, our model architecture and training strategies allow for the simultaneous support of combining speech prompt and descriptive human instruction for expressive speech synthesis, which is a first-of-its-kind attempt. Codes, models and demos are at: https://github.com/thuhcsi/VoxInstruct.