 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRUCTUREDAGENT: Planning with AND/OR Trees for Long-Horizon Web Tasks
Mar 05, 2026Recent advances in large language models (LLMs) have enabled agentic systems for sequential decision-making. Such agents must perceive their environment, reason across multiple time steps, and take actions that optimize long-term objectives. However, existing web agents struggle on complex, long-horizon tasks due to limited in-context memory for tracking history, weak planning abilities, and greedy behaviors that lead to premature termination. To address these challenges, we propose STRUCTUREDAGENT, a hierarchical planning framework with two core components: (1) an online hierarchical planner that uses dynamic AND/OR trees for efficient search and (2) a structured memory module that tracks and maintains candidate solutions to improve constraint satisfaction in information-seeking tasks. The framework also produces interpretable hierarchical plans, enabling easier debugging and facilitating human intervention when needed. Our results on WebVoyager, WebArena, and custom shopping benchmarks show that STRUCTUREDAGENT improves performance on long-horizon web-browsing tasks compared to standard LLM-based agents.
Pix2Key: Controllable Open-Vocabulary Retrieval with Semantic Decomposition and Self-Supervised Visual Dictionary Learning
Feb 26, 2026Composed Image Retrieval (CIR) uses a reference image plus a natural-language edit to retrieve images that apply the requested change while preserving other relevant visual content. Classic fusion pipelines typically rely on supervised triplets and can lose fine-grained cues, while recent zero-shot approaches often caption the reference image and merge the caption with the edit, which may miss implicit user intent and return repetitive results. We present Pix2Key, which represents both queries and candidates as open-vocabulary visual dictionaries, enabling intent-aware constraint matching and diversity-aware reranking in a unified embedding space. A self-supervised pretraining component, V-Dict-AE, further improves the dictionary representation using only images, strengthening fine-grained attribute understanding without CIR-specific supervision. On the DFMM-Compose benchmark, Pix2Key improves Recall@10 up to 3.2 points, and adding V-Dict-AE yields an additional 2.3-point gain while improving intent consistency and maintaining high list diversity.
Chain-of-Look Spatial Reasoning for Dense Surgical Instrument Counting
Feb 11, 2026Accurate counting of surgical instruments in Operating Rooms (OR) is a critical prerequisite for ensuring patient safety during surgery. Despite recent progress of large visual-language models and agentic AI, accurately counting such instruments remains highly challenging, particularly in dense scenarios where instruments are tightly clustered. To address this problem, we introduce Chain-of-Look, a novel visual reasoning framework that mimics the sequential human counting process by enforcing a structured visual chain, rather than relying on classic object detection which is unordered. This visual chain guides the model to count along a coherent spatial trajectory, improving accuracy in complex scenes. To further enforce the physical plausibility of the visual chain, we introduce the neighboring loss function, which explicitly models the spatial constraints inherent to densely packed surgical instruments. We also present SurgCount-HD, a new dataset comprising 1,464 high-density surgical instrument images. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches for counting (e.g., CountGD, REC) as well as Multimodality Large Language Models (e.g., Qwen, ChatGPT) in the challenging task of dense surgical instrument counting.
VLM-Guided Iterative Refinement for Surgical Image Segmentation with Foundation Models
Feb 09, 2026Surgical image segmentation is essential for robot-assisted surgery and intraoperative guidance. However, existing methods are constrained to predefined categories, produce one-shot predictions without adaptive refinement, and lack mechanisms for clinician interaction. We propose IR-SIS, an iterative refinement system for surgical image segmentation that accepts natural language descriptions. IR-SIS leverages a fine-tuned SAM3 for initial segmentation, employs a Vision-Language Model to detect instruments and assess segmentation quality, and applies an agentic workflow that adaptively selects refinement strategies. The system supports clinician-in-the-loop interaction through natural language feedback. We also construct a multi-granularity language-annotated dataset from EndoVis2017 and EndoVis2018 benchmarks. Experiments demonstrate state-of-the-art performance on both in-domain and out-of-distribution data, with clinician interaction providing additional improvements. Our work establishes the first language-based surgical segmentation framework with adaptive self-refinement capabilities.
PP-Motion: Physical-Perceptual Fidelity Evaluation for Human Motion Generation
Aug 11, 2025Human motion generation has found widespread applications in AR/VR, film, sports, and medical rehabilitation, offering a cost-effective alternative to traditional motion capture systems. However, evaluating the fidelity of such generated motions is a crucial, multifaceted task. Although previous approaches have attempted at motion fidelity evaluation using human perception or physical constraints, there remains an inherent gap between human-perceived fidelity and physical feasibility. Moreover, the subjective and coarse binary labeling of human perception further undermines the development of a robust data-driven metric. We address these issues by introducing a physical labeling method. This method evaluates motion fidelity by calculating the minimum modifications needed for a motion to align with physical laws. With this approach, we are able to produce fine-grained, continuous physical alignment annotations that serve as objective ground truth. With these annotations, we propose PP-Motion, a novel data-driven metric to evaluate both physical and perceptual fidelity of human motion. To effectively capture underlying physical priors, we employ Pearson's correlation loss for the training of our metric. Additionally, by incorporating a human-based perceptual fidelity loss, our metric can capture fidelity that simultaneously considers both human perception and physical alignment. Experimental results demonstrate that our metric, PP-Motion, not only aligns with physical laws but also aligns better with human perception of motion fidelity than previous work.
dFLMoE: Decentralized Federated Learning via Mixture of Experts for Medical Data Analysis
Mar 13, 2025Federated learning has wide applications in the medical field. It enables knowledge sharing among different healthcare institutes while protecting patients' privacy. However, existing federated learning systems are typically centralized, requiring clients to upload client-specific knowledge to a central server for aggregation. This centralized approach would integrate the knowledge from each client into a centralized server, and the knowledge would be already undermined during the centralized integration before it reaches back to each client. Besides, the centralized approach also creates a dependency on the central server, which may affect training stability if the server malfunctions or connections are unstable. To address these issues, we propose a decentralized federated learning framework named dFLMoE. In our framework, clients directly exchange lightweight head models with each other. After exchanging, each client treats both local and received head models as individual experts, and utilizes a client-specific Mixture of Experts (MoE) approach to make collective decisions. This design not only reduces the knowledge damage with client-specific aggregations but also removes the dependency on the central server to enhance the robustness of the framework. We validate our framework on multiple medical tasks, demonstrating that our method evidently outperforms state-of-the-art approaches under both model homogeneity and heterogeneity settings.
Source-Free Domain Adaptation for Medical Image Segmentation via Prototype-Anchored Feature Alignment and Contrastive Learning
Jul 19, 2023Unsupervised domain adaptation (UDA) has increasingly gained interests for its capacity to transfer the knowledge learned from a labeled source domain to an unlabeled target domain. However, typical UDA methods require concurrent access to both the source and target domain data, which largely limits its application in medical scenarios where source data is often unavailable due to privacy concern. To tackle the source data-absent problem, we present a novel two-stage source-free domain adaptation (SFDA) framework for medical image segmentation, where only a well-trained source segmentation model and unlabeled target data are available during domain adaptation. Specifically, in the prototype-anchored feature alignment stage, we first utilize the weights of the pre-trained pixel-wise classifier as source prototypes, which preserve the information of source features. Then, we introduce the bi-directional transport to align the target features with class prototypes by minimizing its expected cost. On top of that, a contrastive learning stage is further devised to utilize those pixels with unreliable predictions for a more compact target feature distribution. Extensive experiments on a cross-modality medical segmentation task demonstrate the superiority of our method in large domain discrepancy settings compared with the state-of-the-art SFDA approaches and even some UDA methods. Code is available at https://github.com/CSCYQJ/MICCAI23-ProtoContra-SFDA.
Understanding the Political Ideology of Legislators from Social Media Images
Jul 22, 2019
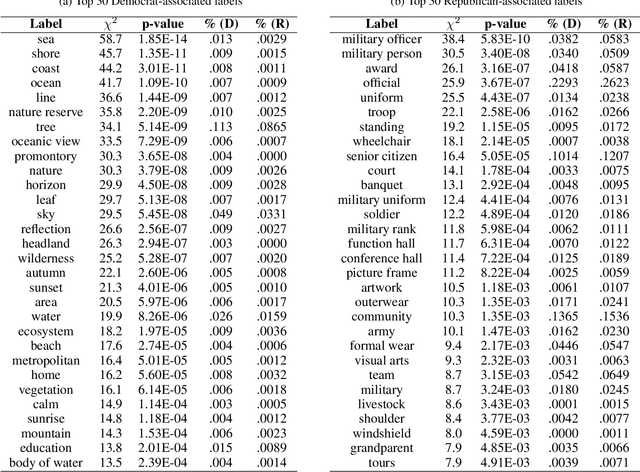

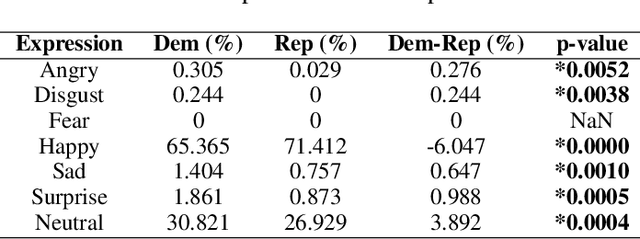
In this paper, we seek to understand how politicians use images to express ideological rhetoric through Facebook images posted by members of the U.S. House and Senate. In the era of social media, politics has become saturated with imagery, a potent and emotionally salient form of political rhetoric which has been used by politicians and political organizations to influence public sentiment and voting behavior for well over a century. To date, however, little is known about how images are used as political rhetoric. Using deep learning techniques to automatically predict Republican or Democratic party affiliation solely from the Facebook photographs of the members of the 114th U.S. Congress, we demonstrate that predicted class probabilities from our model function as an accurate proxy of the political ideology of images along a left-right (liberal-conservative) dimension. After controlling for the gender and race of politicians, our method achieves an accuracy of 59.28% from single photographs and 82.35% when aggregating scores from multiple photographs (up to 150) of the same person. To better understand image content distinguishing liberal from conservative images, we also perform in-depth content analyses of the photographs. Our findings suggest that conservatives tend to use more images supporting status quo political institutions and hierarchy maintenance, featuring individuals from dominant social groups, and displaying greater happiness than liberals.