 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLC$^2$-SLAM: Semantic-guided Loop Closure with Shared Latent Code for NeRF SLAM
Jan 15, 2025



Targeting the notorious cumulative drift errors in NeRF SLAM, we propose a Semantic-guided Loop Closure with Shared Latent Code, dubbed SLC$^2$-SLAM. Especially, we argue that latent codes stored in many NeRF SLAM systems are not fully exploited, as they are only used for better reconstruction. In this paper, we propose a simple yet effective way to detect potential loops using the same latent codes as local features. To further improve the loop detection performance, we use the semantic information, which are also decoded from the same latent codes to guide the aggregation of local features. Finally, with the potential loops detected, we close them with a graph optimization followed by bundle adjustment to refine both the estimated poses and the reconstructed scene. To evaluate the performance of our SLC$^2$-SLAM, we conduct extensive experiments on Replica and ScanNet datasets. Our proposed semantic-guided loop closure significantly outperforms the pre-trained NetVLAD and ORB combined with Bag-of-Words, which are used in all the other NeRF SLAM with loop closure. As a result, our SLC$^2$-SLAM also demonstrated better tracking and reconstruction performance, especially in larger scenes with more loops, like ScanNet.
Perceptually-inspired super-resolution of compressed videos
Jun 15, 2021Spatial resolution adaptation is a technique which has often been employed in video compression to enhance coding efficiency. This approach encodes a lower resolution version of the input video and reconstructs the original resolution during decoding. Instead of using conventional up-sampling filters, recent work has employed advanced super-resolution methods based on convolutional neural networks (CNNs) to further improve reconstruction quality. These approaches are usually trained to minimise pixel-based losses such as Mean-Squared Error (MSE), despite the fact that this type of loss metric does not correlate well with subjective opinions. In this paper, a perceptually-inspired super-resolution approach (M-SRGAN) is proposed for spatial up-sampling of compressed video using a modified CNN model, which has been trained using a generative adversarial network (GAN) on compressed content with perceptual loss functions. The proposed method was integrated with HEVC HM 16.20, and has been evaluated on the JVET Common Test Conditions (UHD test sequences) using the Random Access configuration. The results show evident perceptual quality improvement over the original HM 16.20, with an average bitrate saving of 35.6% (Bj{\o}ntegaard Delta measurement) based on a perceptual quality metric, VMAF.
A Subjective Study on Videos at Various Bit Depths
Mar 18, 2021


Bit depth adaptation, where the bit depth of a video sequence is reduced before transmission and up-sampled during display, can potentially reduce data rates with limited impact on perceptual quality. In this context, we conducted a subjective study on a UHD video database, BVI-BD, to explore the relationship between bit depth and visual quality. In this work, three bit depth adaptation methods are investigated, including linear scaling, error diffusion, and a novel adaptive Gaussian filtering approach. The results from a subjective experiment indicate that above a critical bit depth, bit depth adaptation has no significant impact on perceptual quality, while reducing the amount information that is required to be transmitted. Below the critical bit depth, advanced adaptation methods can be used to retain `good' visual quality (on average) down to around 2 bits per color channel for the outlined experimental setup - a large reduction compared to the typically used 8 bits per color channel. A selection of image quality metrics were subsequently bench-marked on the subjective data, and analysis indicates that a bespoke quality metric is required for bit depth adaptation.
CVEGAN: A Perceptually-inspired GAN for Compressed Video Enhancement
Nov 26, 2020
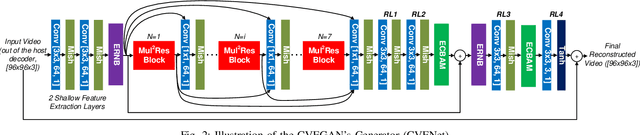
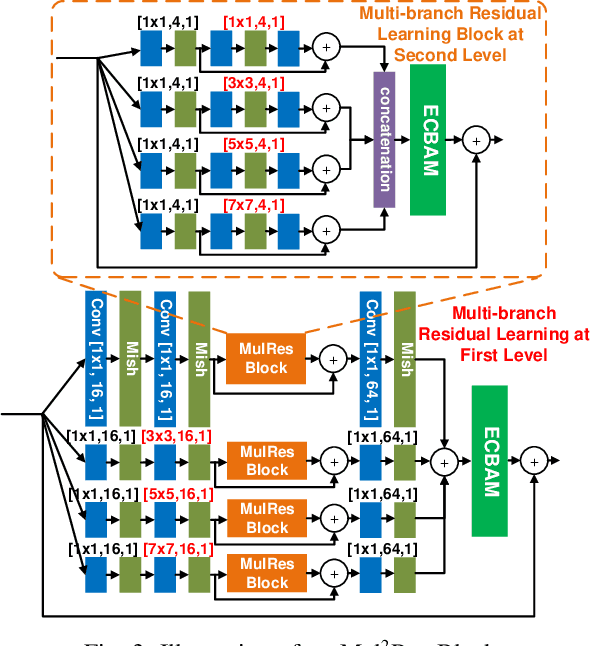
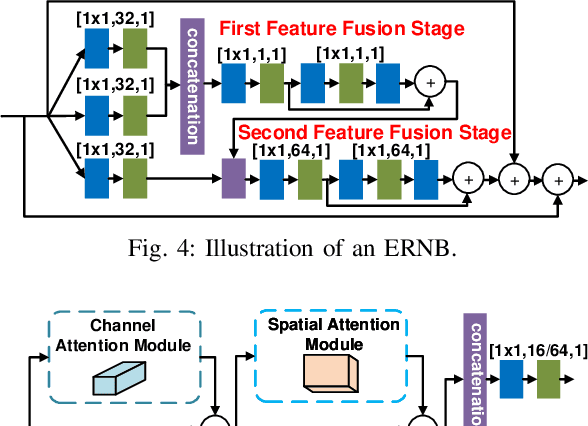
We propose a new Generative Adversarial Network for Compressed Video quality Enhancement (CVEGAN). The CVEGAN generator benefits from the use of a novel Mul2Res block (with multiple levels of residual learning branches), an enhanced residual non-local block (ERNB) and an enhanced convolutional block attention module (ECBAM). The ERNB has also been employed in the discriminator to improve the representational capability. The training strategy has also been re-designed specifically for video compression applications, to employ a relativistic sphere GAN (ReSphereGAN) training methodology together with new perceptual loss functions. The proposed network has been fully evaluated in the context of two typical video compression enhancement tools: post-processing (PP) and spatial resolution adaptation (SRA). CVEGAN has been fully integrated into the MPEG HEVC video coding test model (HM16.20) and experimental results demonstrate significant coding gains (up to 28% for PP and 38% for SRA compared to the anchor) over existing state-of-the-art architectures for both coding tools across multiple datasets.
Video Compression with CNN-based Post Processing
Sep 16, 2020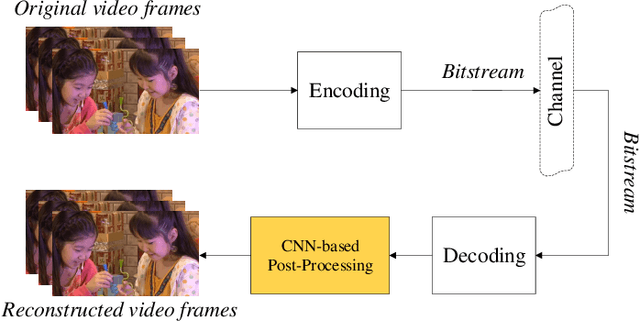
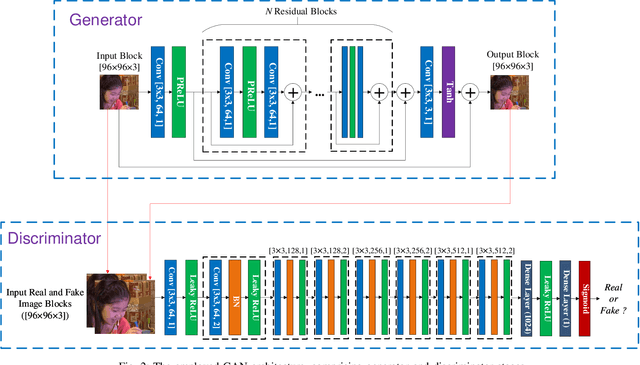
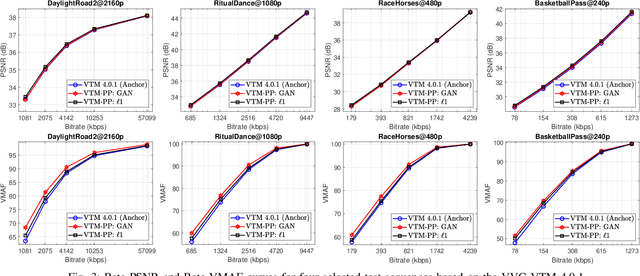
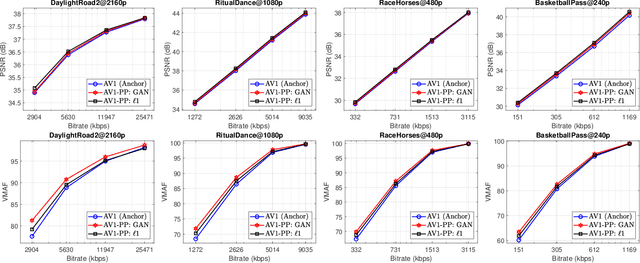
In recent years, video compression techniques have been significantly challenged by the rapidly increased demands associated with high quality and immersive video content. Among various compression tools, post-processing can be applied on reconstructed video content to mitigate visible compression artefacts and to enhance overall perceptual quality. Inspired by advances in deep learning, we propose a new CNN-based post-processing approach, which has been integrated with two state-of-the-art coding standards, VVC and AV1. The results show consistent coding gains on all tested sequences at various spatial resolutions, with average bit rate savings of 4.0% and 5.8% against original VVC and AV1 respectively (based on the assessment of PSNR). This network has also been trained with perceptually inspired loss functions, which have further improved reconstruction quality based on perceptual quality assessment (VMAF), with average coding gains of 13.9% over VVC and 10.5% against AV1.
Video compression with low complexity CNN-based spatial resolution adaptation
Jul 29, 2020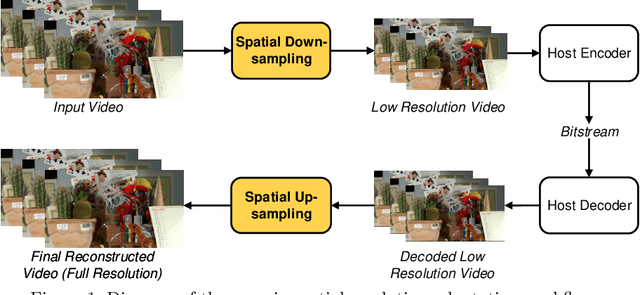
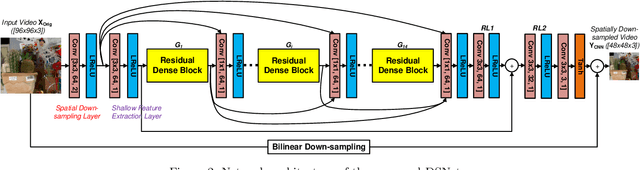
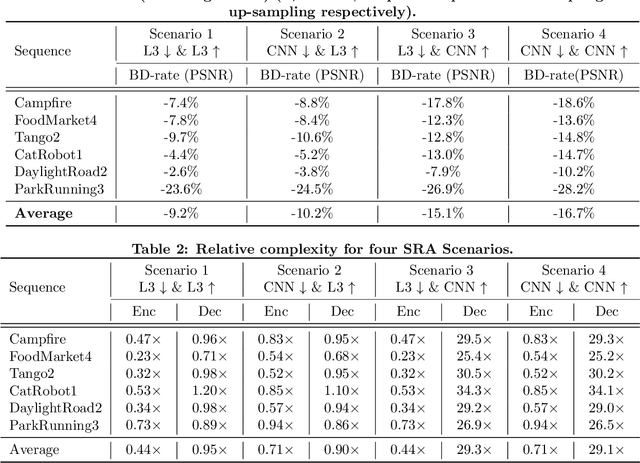
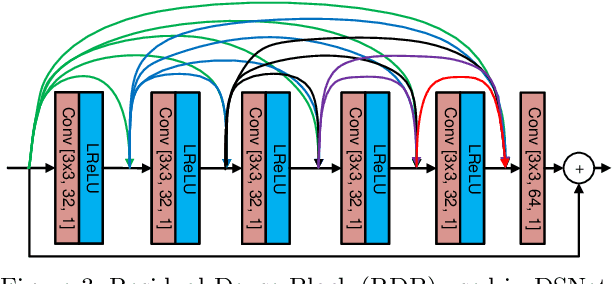
It has recently been demonstrated that spatial resolution adaptation can be integrated within video compression to improve overall coding performance by spatially down-sampling before encoding and super-resolving at the decoder. Significant improvements have been reported when convolutional neural networks (CNNs) were used to perform the resolution up-sampling. However, this approach suffers from high complexity at the decoder due to the employment of CNN-based super-resolution. In this paper, a novel framework is proposed which supports the flexible allocation of complexity between the encoder and decoder. This approach employs a CNN model for video down-sampling at the encoder and uses a Lanczos3 filter to reconstruct full resolution at the decoder. The proposed method was integrated into the HEVC HM 16.20 software and evaluated on JVET UHD test sequences using the All Intra configuration. The experimental results demonstrate the potential of the proposed approach, with significant bitrate savings (more than 10%) over the original HEVC HM, coupled with reduced computational complexity at both encoder (29%) and decoder (10%).
MFRNet: A New CNN Architecture for Post-Processing and In-loop Filtering
Jul 14, 2020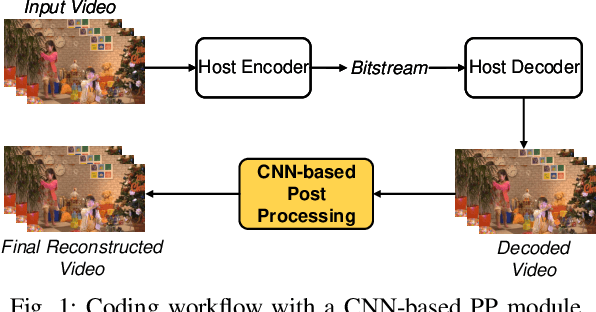
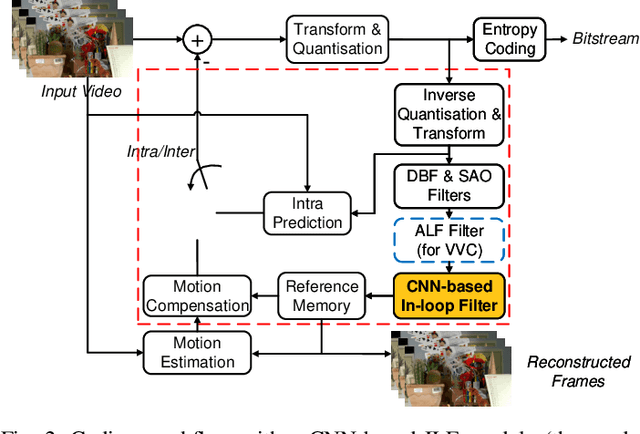
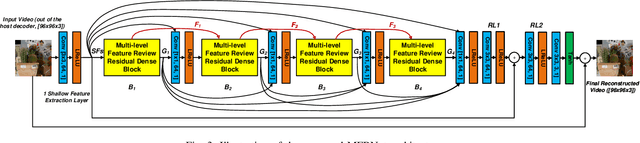
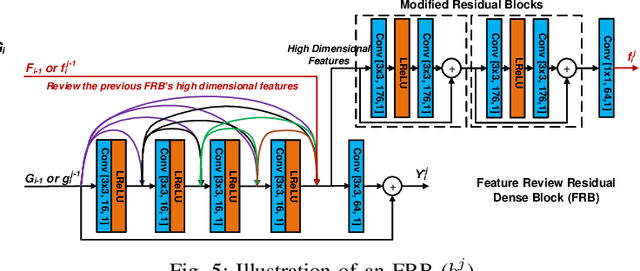
In this paper, we propose a novel convolutional neural network (CNN) architecture, MFRNet, for post-processing (PP) and in-loop filtering (ILF) in the context of video compression. This network consists of four Multi-level Feature review Residual dense Blocks (MFRBs), which are connected using a cascading structure. Each MFRB extracts features from multiple convolutional layers using dense connections and a multi-level residual learning structure. In order to further improve information flow between these blocks, each of them also reuses high dimensional features from the previous MFRB. This network has been integrated into PP and ILF coding modules for both HEVC (HM 16.20) and VVC (VTM 7.0), and fully evaluated under the JVET Common Test Conditions using the Random Access configuration. The experimental results show significant and consistent coding gains over both anchor codecs (HEVC HM and VVC VTM) and also over other existing CNN-based PP/ILF approaches based on Bjontegaard Delta measurements using both PSNR and VMAF for quality assessment. When MFRNet is integrated into HM 16.20, gains up to 16.0% (BD-rate VMAF) are demonstrated for ILF, and up to 21.0% (BD-rate VMAF) for PP. The respective gains for VTM 7.0 are up to 5.1% for ILF and up to 7.1% for PP.
BVI-DVC: A Training Database for Deep Video Compression
Mar 30, 2020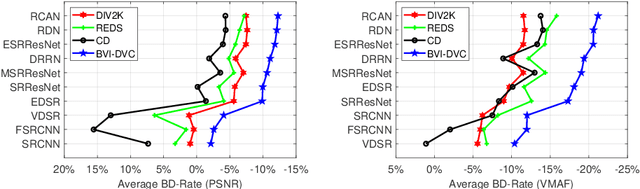


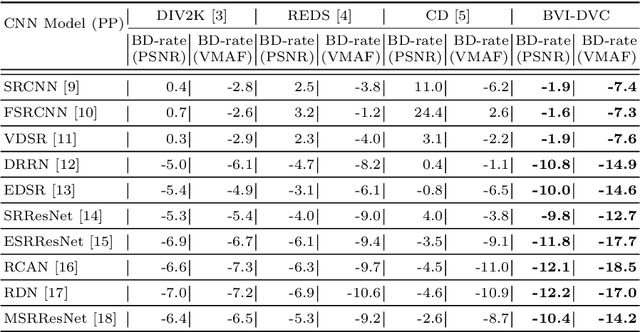
Deep learning methods are increasingly being applied in the optimisation of video compression algorithms and can achieve significantly enhanced coding gains, compared to conventional approaches. Such approaches often employ Convolutional Neural Networks (CNNs) which are trained on databases with relatively limited content coverage. In this paper, a new extensive and representative video database, BVI-DVC, is presented for training CNN-based coding tools. BVI-DVC contains 800 sequences at various spatial resolutions from 270p to 2160p and has been evaluated on ten existing network architectures for four different coding tools. Experimental results show that the database produces significant improvements in terms of coding gains over three existing (commonly used) image/video training databases, for all tested CNN architectures under the same training and evaluation configurations.
Understanding the Political Ideology of Legislators from Social Media Images
Jul 22, 2019
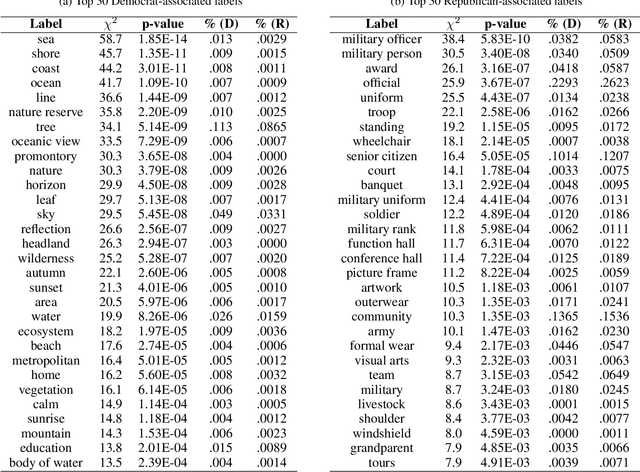

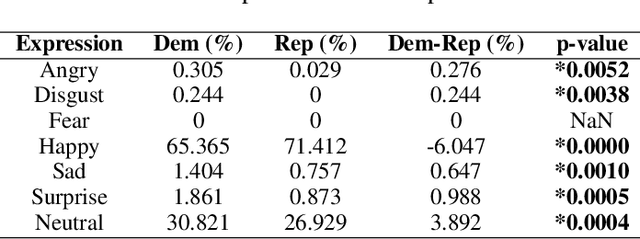
In this paper, we seek to understand how politicians use images to express ideological rhetoric through Facebook images posted by members of the U.S. House and Senate. In the era of social media, politics has become saturated with imagery, a potent and emotionally salient form of political rhetoric which has been used by politicians and political organizations to influence public sentiment and voting behavior for well over a century. To date, however, little is known about how images are used as political rhetoric. Using deep learning techniques to automatically predict Republican or Democratic party affiliation solely from the Facebook photographs of the members of the 114th U.S. Congress, we demonstrate that predicted class probabilities from our model function as an accurate proxy of the political ideology of images along a left-right (liberal-conservative) dimension. After controlling for the gender and race of politicians, our method achieves an accuracy of 59.28% from single photographs and 82.35% when aggregating scores from multiple photographs (up to 150) of the same person. To better understand image content distinguishing liberal from conservative images, we also perform in-depth content analyses of the photographs. Our findings suggest that conservatives tend to use more images supporting status quo political institutions and hierarchy maintenance, featuring individuals from dominant social groups, and displaying greater happiness than liberals.
Generating Image Sequence from Description with LSTM Conditional GAN
Jun 08, 2018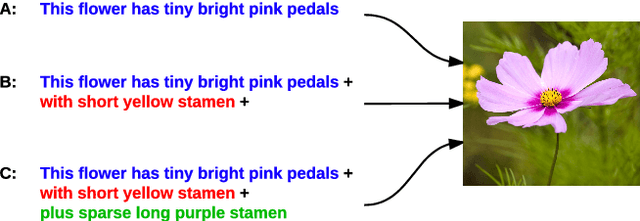
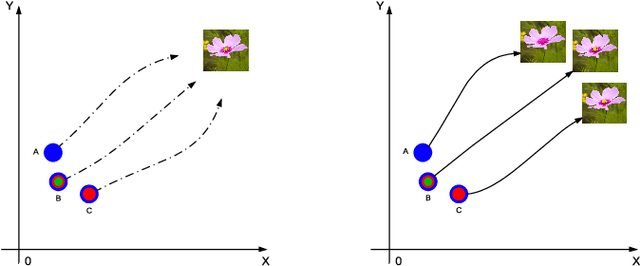
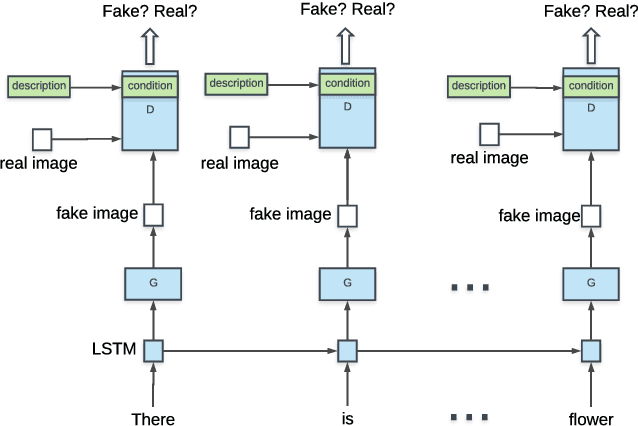

Generating images from word descriptions is a challenging task. Generative adversarial networks(GANs) are shown to be able to generate realistic images of real-life objects. In this paper, we propose a new neural network architecture of LSTM Conditional Generative Adversarial Networks to generate images of real-life objects. Our proposed model is trained on the Oxford-102 Flowers and Caltech-UCSD Birds-200-2011 datasets. We demonstrate that our proposed model produces the better results surpassing other state-of-art approaches.