 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Vision-Language-Action Model Already Has Attention Heads For Path Deviation Detection
Mar 14, 2026Vision-Language-Action (VLA) models have demonstrated strong potential for predicting semantic actions in navigation tasks, demonstrating the ability to reason over complex linguistic instructions and visual contexts. However, they are fundamentally hindered by visual-reasoning hallucinations that lead to trajectory deviations. Addressing this issue has conventionally required training external critic modules or relying on complex uncertainty heuristics. In this work, we discover that monitoring a few attention heads within a frozen VLA model can accurately detect path deviations without incurring additional computational overhead. We refer to these heads, which inherently capture the spatiotemporal causality between historical visual sequences and linguistic instructions, as Navigation Heads. Using these heads, we propose an intuitive, training-free anomaly-detection framework that monitors their signals to detect hallucinations in real time. Surprisingly, among over a thousand attention heads, a combination of just three is sufficient to achieve a 44.6 % deviation detection rate with a low false-positive rate of 11.7 %. Furthermore, upon detecting a deviation, we bypass the heavy VLA model and trigger a lightweight Reinforcement Learning (RL) policy to safely execute a shortest-path rollback. By integrating this entire detection-to-recovery pipeline onto a physical robot, we demonstrate its practical robustness. All source code will be publicly available.
Integrating Deep Metric Learning with Coreset for Active Learning in 3D Segmentation
Nov 24, 2024



Deep learning has seen remarkable advancements in machine learning, yet it often demands extensive annotated data. Tasks like 3D semantic segmentation impose a substantial annotation burden, especially in domains like medicine, where expert annotations drive up the cost. Active learning (AL) holds great potential to alleviate this annotation burden in 3D medical segmentation. The majority of existing AL methods, however, are not tailored to the medical domain. While weakly-supervised methods have been explored to reduce annotation burden, the fusion of AL with weak supervision remains unexplored, despite its potential to significantly reduce annotation costs. Additionally, there is little focus on slice-based AL for 3D segmentation, which can also significantly reduce costs in comparison to conventional volume-based AL. This paper introduces a novel metric learning method for Coreset to perform slice-based active learning in 3D medical segmentation. By merging contrastive learning with inherent data groupings in medical imaging, we learn a metric that emphasizes the relevant differences in samples for training 3D medical segmentation models. We perform comprehensive evaluations using both weak and full annotations across four datasets (medical and non-medical). Our findings demonstrate that our approach surpasses existing active learning techniques on both weak and full annotations and obtains superior performance with low-annotation budgets which is crucial in medical imaging. Source code for this project is available in the supplementary materials and on GitHub: https://github.com/arvindmvepa/al-seg.
Towards Viewpoint Robustness in Bird's Eye View Segmentation
Sep 11, 2023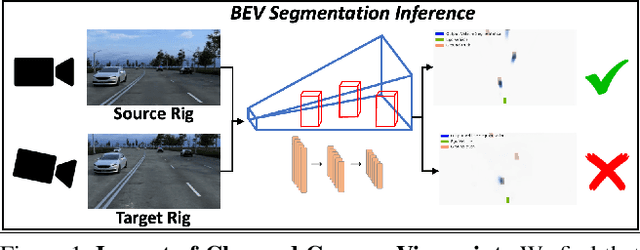


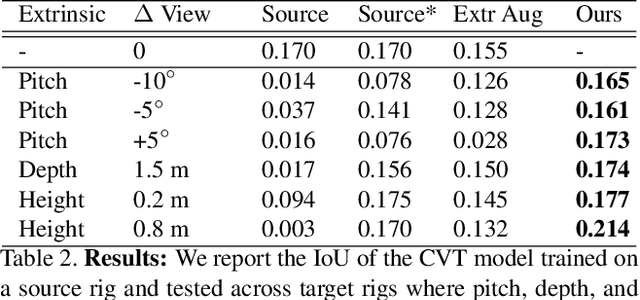
Autonomous vehicles (AV) require that neural networks used for perception be robust to different viewpoints if they are to be deployed across many types of vehicles without the repeated cost of data collection and labeling for each. AV companies typically focus on collecting data from diverse scenarios and locations, but not camera rig configurations, due to cost. As a result, only a small number of rig variations exist across most fleets. In this paper, we study how AV perception models are affected by changes in camera viewpoint and propose a way to scale them across vehicle types without repeated data collection and labeling. Using bird's eye view (BEV) segmentation as a motivating task, we find through extensive experiments that existing perception models are surprisingly sensitive to changes in camera viewpoint. When trained with data from one camera rig, small changes to pitch, yaw, depth, or height of the camera at inference time lead to large drops in performance. We introduce a technique for novel view synthesis and use it to transform collected data to the viewpoint of target rigs, allowing us to train BEV segmentation models for diverse target rigs without any additional data collection or labeling cost. To analyze the impact of viewpoint changes, we leverage synthetic data to mitigate other gaps (content, ISP, etc). Our approach is then trained on real data and evaluated on synthetic data, enabling evaluation on diverse target rigs. We release all data for use in future work. Our method is able to recover an average of 14.7% of the IoU that is otherwise lost when deploying to new rigs.
Sim2Real Physically Informed Neural Controllers for Robotic Deployment of Deformable Linear Objects
Mar 05, 2023Deformable linear objects, such as rods, cables, and ropes, play important roles in daily life. However, manipulation of DLOs is challenging as large geometrically nonlinear deformations may occur during the manipulation process. This problem is made even more difficult as the different deformation modes (e.g., stretching, bending, and twisting) may result in elastic instabilities during manipulation. In this paper, we formulate a physics-guided data-driven method to solve a challenging manipulation task -- accurately deploying a DLO (an elastic rod) onto a rigid substrate along various prescribed patterns. Our framework combines machine learning, scaling analysis, and physics-based simulations to develop a physically informed neural controller for deployment. We explore the complex interplay between the gravitational and elastic energies of the manipulated DLO and obtain a control method for DLO deployment that is robust against friction and material properties. Out of the numerous geometrical and material properties of the rod and substrate, we show that only three non-dimensional parameters are needed to describe the deployment process with physical analysis. Therefore, the essence of the controlling law for the manipulation task can be constructed with a low-dimensional model, drastically increasing the computation speed. The effectiveness of our optimal control scheme is shown through a comprehensive robotic case study comparing against a heuristic control method for deploying rods for a wide variety of patterns. In addition to this, we also showcase the practicality of our control scheme by having a robot accomplish challenging high-level tasks such as mimicking human handwriting and tying knots.
mBEST: Realtime Deformable Linear Object Detection Through Minimal Bending Energy Skeleton Pixel Traversals
Feb 18, 2023Robotic manipulation of deformable materials is a challenging task that often requires realtime visual feedback. This is especially true for deformable linear objects (DLOs) or "rods", whose slender and flexible structures make proper tracking and detection nontrivial. To address this challenge, we present mBEST, a robust algorithm for the realtime detection of DLOs that is capable of producing an ordered pixel sequence of each DLO's centerline along with segmentation masks. Our algorithm obtains a binary mask of the DLOs and then thins it to produce a skeleton pixel representation. After refining the skeleton to ensure topological correctness, the pixels are traversed to generate paths along each unique DLO. At the core of our algorithm, we postulate that intersections can be robustly handled by choosing the combination of paths that minimizes the cumulative bending energy of the DLO(s). We show that this simple and intuitive formulation outperforms the state-of-the-art methods for detecting DLOs with large numbers of sporadic crossings and curvatures with high variance. Furthermore, our method achieves a significant performance improvement of approximately 40 FPS compared to the 15 FPS of prior algorithms, which enables realtime applications.
Deep Learning of Force Manifolds from the Simulated Physics of Robotic Paper Folding
Jan 05, 2023



Robotic manipulation of slender objects is challenging, especially when the induced deformations are large and nonlinear. Traditionally, learning-based control approaches, e.g., imitation learning, have been used to tackle deformable material manipulation. Such approaches lack generality and often suffer critical failure from a simple switch of material, geometric, and/or environmental (e.g., friction) properties. In this article, we address a fundamental but difficult step of robotic origami: forming a predefined fold in paper with only a single manipulator. A data-driven framework combining physically-accurate simulation and machine learning is used to train deep neural network models capable of predicting the external forces induced on the paper given a grasp position. We frame the problem using scaling analysis, resulting in a control framework robust against material and geometric changes. Path planning is carried out over the generated manifold to produce robot manipulation trajectories optimized to prevent sliding. Furthermore, the inference speed of the trained model enables the incorporation of real-time visual feedback to achieve closed-loop sensorimotor control. Real-world experiments demonstrate that our framework can greatly improve robotic manipulation performance compared against natural paper folding strategies, even when manipulating paper objects of various materials and shapes.
FairGRAPE: Fairness-aware GRAdient Pruning mEthod for Face Attribute Classification
Jul 22, 2022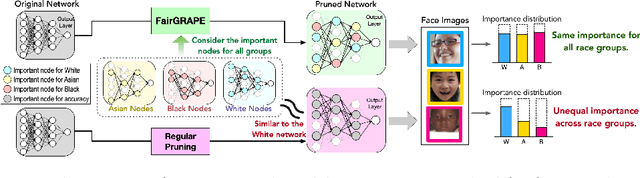

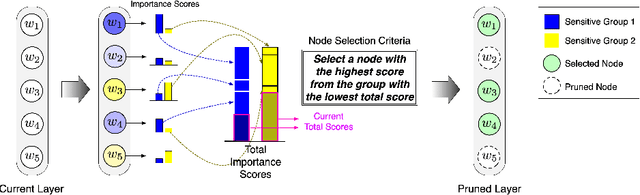
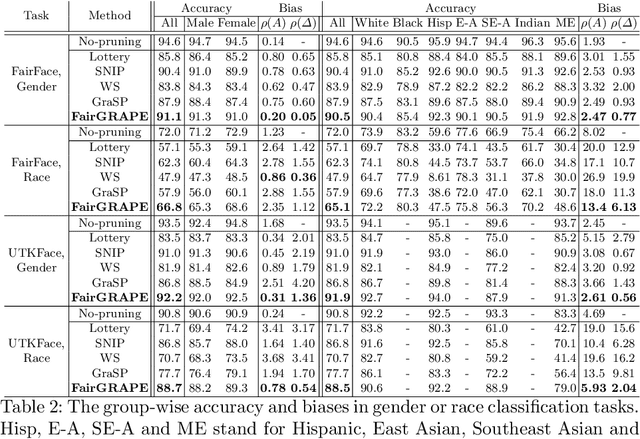
Existing pruning techniques preserve deep neural networks' overall ability to make correct predictions but may also amplify hidden biases during the compression process. We propose a novel pruning method, Fairness-aware GRAdient Pruning mEthod (FairGRAPE), that minimizes the disproportionate impacts of pruning on different sub-groups. Our method calculates the per-group importance of each model weight and selects a subset of weights that maintain the relative between-group total importance in pruning. The proposed method then prunes network edges with small importance values and repeats the procedure by updating importance values. We demonstrate the effectiveness of our method on four different datasets, FairFace, UTKFace, CelebA, and ImageNet, for the tasks of face attribute classification where our method reduces the disparity in performance degradation by up to 90% compared to the state-of-the-art pruning algorithms. Our method is substantially more effective in a setting with a high pruning rate (99%). The code and dataset used in the experiments are available at https://github.com/Bernardo1998/FairGRAPE
Explaining Deep Convolutional Neural Networks via Latent Visual-Semantic Filter Attention
Apr 10, 2022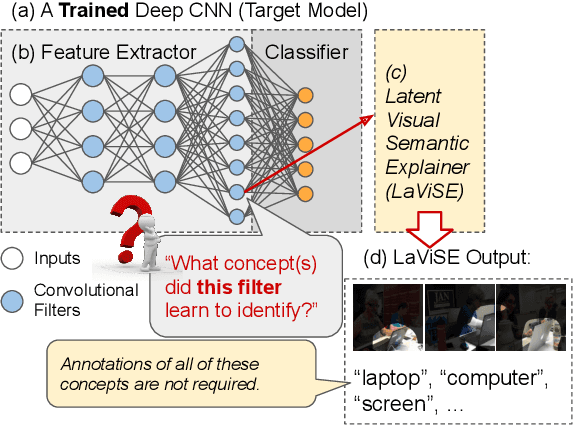
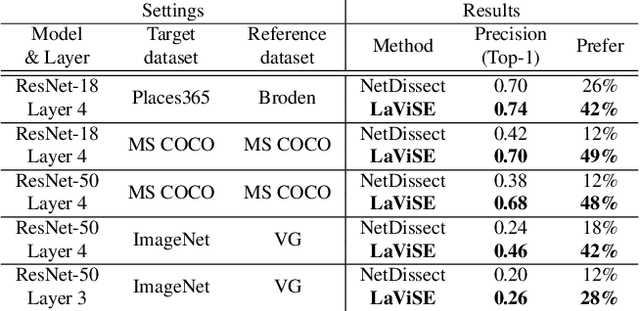
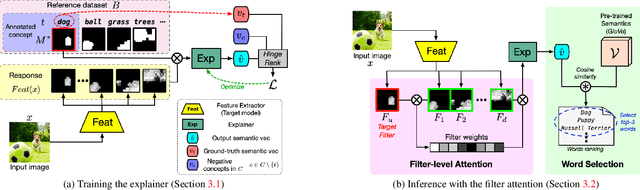
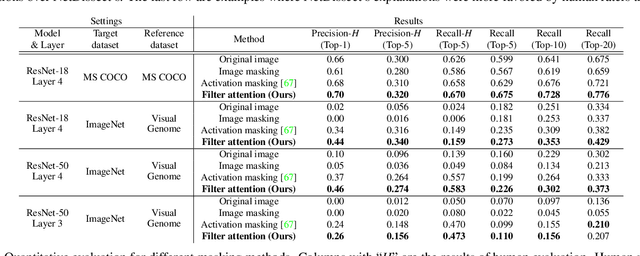
Interpretability is an important property for visual models as it helps researchers and users understand the internal mechanism of a complex model. However, generating semantic explanations about the learned representation is challenging without direct supervision to produce such explanations. We propose a general framework, Latent Visual Semantic Explainer (LaViSE), to teach any existing convolutional neural network to generate text descriptions about its own latent representations at the filter level. Our method constructs a mapping between the visual and semantic spaces using generic image datasets, using images and category names. It then transfers the mapping to the target domain which does not have semantic labels. The proposed framework employs a modular structure and enables to analyze any trained network whether or not its original training data is available. We show that our method can generate novel descriptions for learned filters beyond the set of categories defined in the training dataset and perform an extensive evaluation on multiple datasets. We also demonstrate a novel application of our method for unsupervised dataset bias analysis which allows us to automatically discover hidden biases in datasets or compare different subsets without using additional labels. The dataset and code are made public to facilitate further research.
Preemptive Motion Planning for Human-to-Robot Indirect Placement Handovers
Mar 01, 2022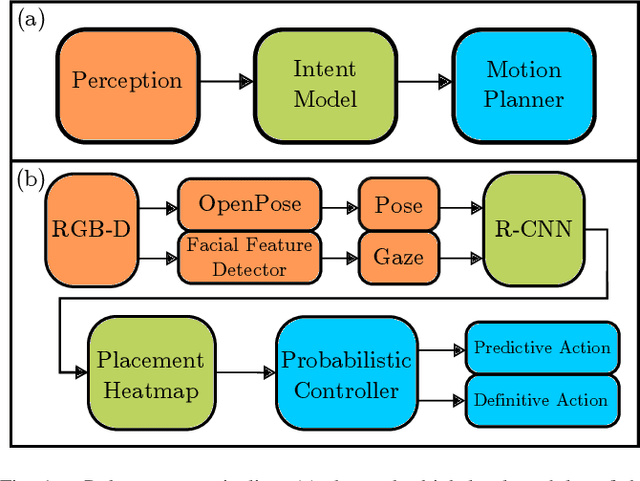
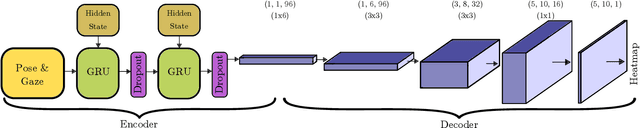
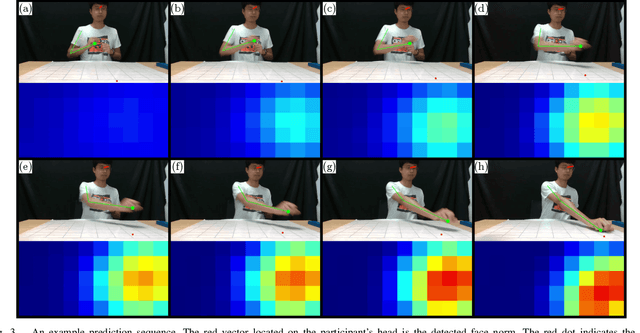

As technology advances, the need for safe, efficient, and collaborative human-robot-teams has become increasingly important. One of the most fundamental collaborative tasks in any setting is the object handover. Human-to-robot handovers can take either of two approaches: (1) direct hand-to-hand or (2) indirect hand-to-placement-to-pick-up. The latter approach ensures minimal contact between the human and robot but can also result in increased idle time due to having to wait for the object to first be placed down on a surface. To minimize such idle time, the robot must preemptively predict the human intent of where the object will be placed. Furthermore, for the robot to preemptively act in any sort of productive manner, predictions and motion planning must occur in real-time. We introduce a novel prediction-planning pipeline that allows the robot to preemptively move towards the human agent's intended placement location using gaze and gestures as model inputs. In this paper, we investigate the performance and drawbacks of our early intent predictor-planner as well as the practical benefits of using such a pipeline through a human-robot case study.
Understanding and Mitigating Annotation Bias in Facial Expression Recognition
Aug 19, 2021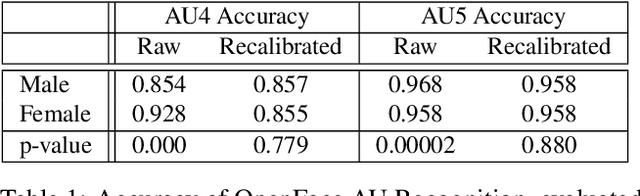
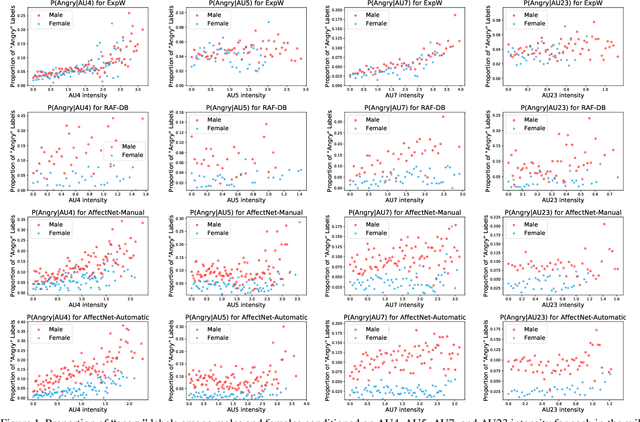
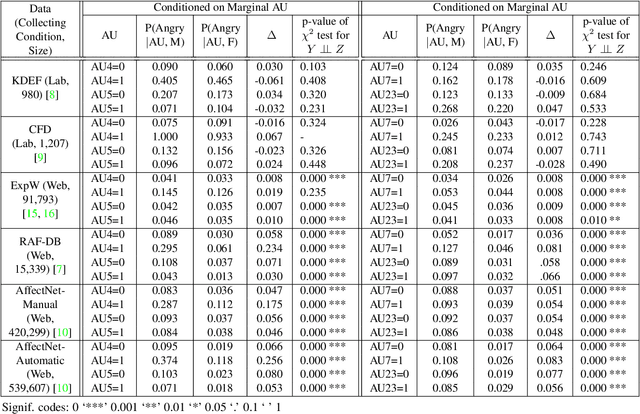
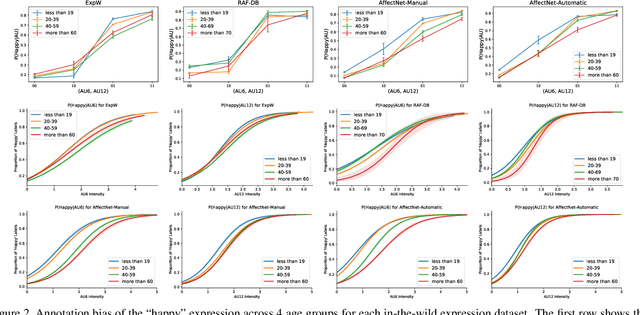
The performance of a computer vision model depends on the size and quality of its training data. Recent studies have unveiled previously-unknown composition biases in common image datasets which then lead to skewed model outputs, and have proposed methods to mitigate these biases. However, most existing works assume that human-generated annotations can be considered gold-standard and unbiased. In this paper, we reveal that this assumption can be problematic, and that special care should be taken to prevent models from learning such annotation biases. We focus on facial expression recognition and compare the label biases between lab-controlled and in-the-wild datasets. We demonstrate that many expression datasets contain significant annotation biases between genders, especially when it comes to the happy and angry expressions, and that traditional methods cannot fully mitigate such biases in trained models. To remove expression annotation bias, we propose an AU-Calibrated Facial Expression Recognition (AUC-FER) framework that utilizes facial action units (AUs) and incorporates the triplet loss into the objective function. Experimental results suggest that the proposed method is more effective in removing expression annotation bias than existing techniques.