 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning of Dynamic Planar Manipulation of Free-End Cables
May 15, 2024



Dynamic manipulation of free-end cables has applications for cable management in homes, warehouses and manufacturing plants. We present a supervised learning approach for dynamic manipulation of free-end cables, focusing on the problem of getting the cable endpoint to a designated target position, which may lie outside the reachable workspace of the robot end effector. We present a simulator, tune it to closely match experiments with physical cables, and then collect training data for learning dynamic cable manipulation. We evaluate with 3 cables and a physical UR5 robot. Results over 32x5 trials on 3 cables suggest that a physical UR5 robot can attain a median error distance ranging from 22% to 35% of the cable length among cables, outperforming an analytic baseline by 21% and a Gaussian Process baseline by 7% with lower interquartile range (IQR).
Bi-CLKT: Bi-Graph Contrastive Learning based Knowledge Tracing
Jan 22, 2022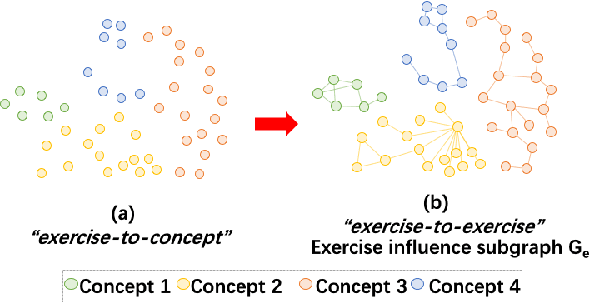
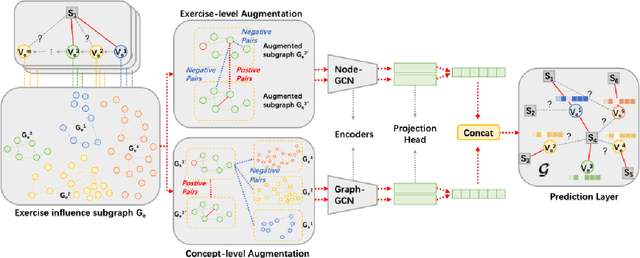
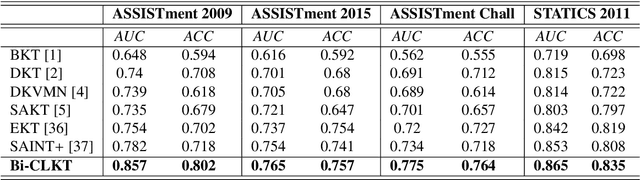
The goal of Knowledge Tracing (KT) is to estimate how well students have mastered a concept based on their historical learning of related exercises. The benefit of knowledge tracing is that students' learning plans can be better organised and adjusted, and interventions can be made when necessary. With the recent rise of deep learning, Deep Knowledge Tracing (DKT) has utilised Recurrent Neural Networks (RNNs) to accomplish this task with some success. Other works have attempted to introduce Graph Neural Networks (GNNs) and redefine the task accordingly to achieve significant improvements. However, these efforts suffer from at least one of the following drawbacks: 1) they pay too much attention to details of the nodes rather than to high-level semantic information; 2) they struggle to effectively establish spatial associations and complex structures of the nodes; and 3) they represent either concepts or exercises only, without integrating them. Inspired by recent advances in self-supervised learning, we propose a Bi-Graph Contrastive Learning based Knowledge Tracing (Bi-CLKT) to address these limitations. Specifically, we design a two-layer contrastive learning scheme based on an "exercise-to-exercise" (E2E) relational subgraph. It involves node-level contrastive learning of subgraphs to obtain discriminative representations of exercises, and graph-level contrastive learning to obtain discriminative representations of concepts. Moreover, we designed a joint contrastive loss to obtain better representations and hence better prediction performance. Also, we explored two different variants, using RNN and memory-augmented neural networks as the prediction layer for comparison to obtain better representations of exercises and concepts respectively. Extensive experiments on four real-world datasets show that the proposed Bi-CLKT and its variants outperform other baseline models.
Understanding and Mitigating Annotation Bias in Facial Expression Recognition
Aug 19, 2021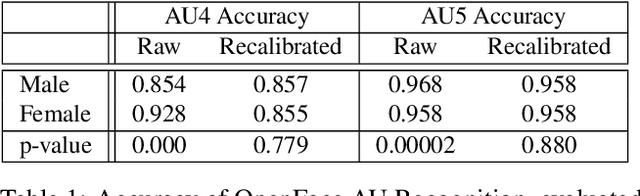
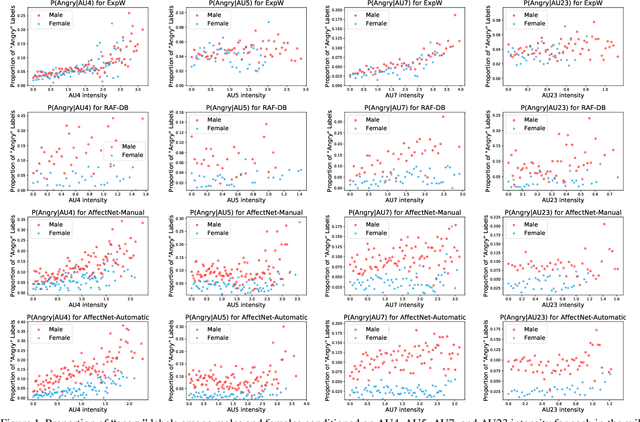
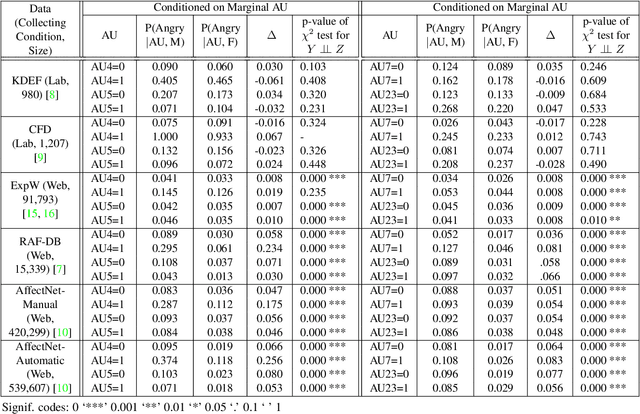
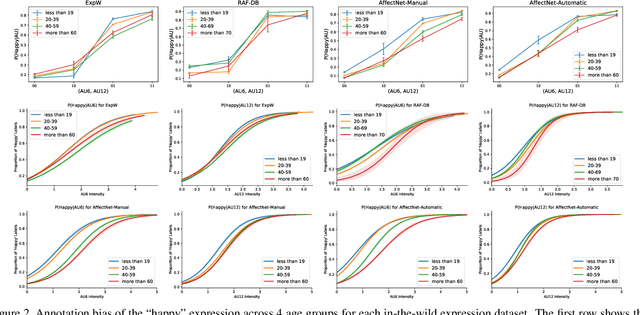
The performance of a computer vision model depends on the size and quality of its training data. Recent studies have unveiled previously-unknown composition biases in common image datasets which then lead to skewed model outputs, and have proposed methods to mitigate these biases. However, most existing works assume that human-generated annotations can be considered gold-standard and unbiased. In this paper, we reveal that this assumption can be problematic, and that special care should be taken to prevent models from learning such annotation biases. We focus on facial expression recognition and compare the label biases between lab-controlled and in-the-wild datasets. We demonstrate that many expression datasets contain significant annotation biases between genders, especially when it comes to the happy and angry expressions, and that traditional methods cannot fully mitigate such biases in trained models. To remove expression annotation bias, we propose an AU-Calibrated Facial Expression Recognition (AUC-FER) framework that utilizes facial action units (AUs) and incorporates the triplet loss into the objective function. Experimental results suggest that the proposed method is more effective in removing expression annotation bias than existing techniques.