 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperclass-Guided Representation Disentanglement for Spurious Correlation Mitigation
Aug 12, 2025



To enhance group robustness to spurious correlations, prior work often relies on auxiliary annotations for groups or spurious features and assumes identical sets of groups across source and target domains. These two requirements are both unnatural and impractical in real-world settings. To overcome these limitations, we propose a method that leverages the semantic structure inherent in class labels--specifically, superclass information--to naturally reduce reliance on spurious features. Our model employs gradient-based attention guided by a pre-trained vision-language model to disentangle superclass-relevant and irrelevant features. Then, by promoting the use of all superclass-relevant features for prediction, our approach achieves robustness to more complex spurious correlations without the need to annotate any source samples. Experiments across diverse datasets demonstrate that our method significantly outperforms baselines in domain generalization tasks, with clear improvements in both quantitative metrics and qualitative visualizations.
Performative Risk Control: Calibrating Models for Reliable Deployment under Performativity
May 30, 2025Calibrating blackbox machine learning models to achieve risk control is crucial to ensure reliable decision-making. A rich line of literature has been studying how to calibrate a model so that its predictions satisfy explicit finite-sample statistical guarantees under a fixed, static, and unknown data-generating distribution. However, prediction-supported decisions may influence the outcome they aim to predict, a phenomenon named performativity of predictions, which is commonly seen in social science and economics. In this paper, we introduce Performative Risk Control, a framework to calibrate models to achieve risk control under performativity with provable theoretical guarantees. Specifically, we provide an iteratively refined calibration process, where we ensure the predictions are improved and risk-controlled throughout the process. We also study different types of risk measures and choices of tail bounds. Lastly, we demonstrate the effectiveness of our framework by numerical experiments on the task of predicting credit default risk. To the best of our knowledge, this work is the first one to study statistically rigorous risk control under performativity, which will serve as an important safeguard against a wide range of strategic manipulation in decision-making processes.
Bridging Distribution Shift and AI Safety: Conceptual and Methodological Synergies
May 28, 2025This paper bridges distribution shift and AI safety through a comprehensive analysis of their conceptual and methodological synergies. While prior discussions often focus on narrow cases or informal analogies, we establish two types connections between specific causes of distribution shift and fine-grained AI safety issues: (1) methods addressing a specific shift type can help achieve corresponding safety goals, or (2) certain shifts and safety issues can be formally reduced to each other, enabling mutual adaptation of their methods. Our findings provide a unified perspective that encourages fundamental integration between distribution shift and AI safety research.
Bridging Domain Adaptation and Graph Neural Networks: A Tensor-Based Framework for Effective Label Propagation
Feb 12, 2025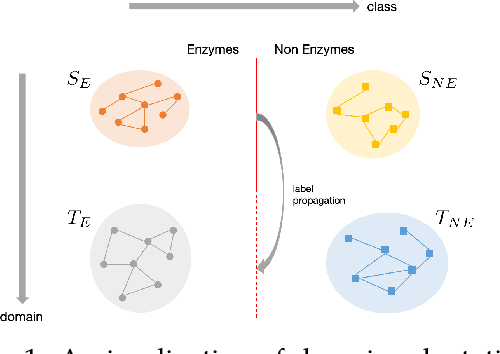
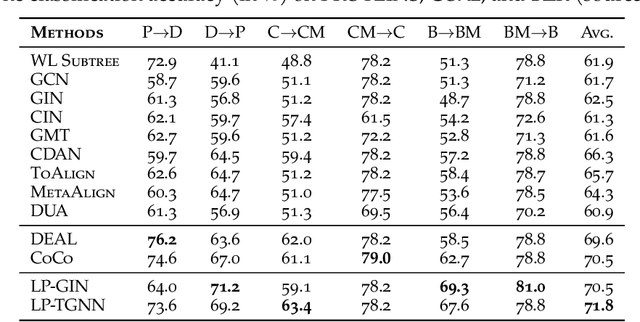
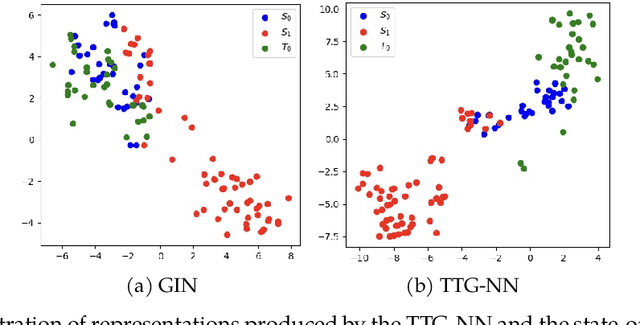
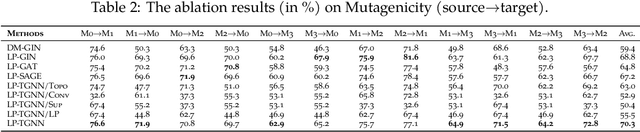
Graph Neural Networks (GNNs) have recently become the predominant tools for studying graph data. Despite state-of-the-art performance on graph classification tasks, GNNs are overwhelmingly trained in a single domain under supervision, thus necessitating a prohibitively high demand for labels and resulting in poorly transferable representations. To address this challenge, we propose the Label-Propagation Tensor Graph Neural Network (LP-TGNN) framework to bridge the gap between graph data and traditional domain adaptation methods. It extracts graph topological information holistically with a tensor architecture and then reduces domain discrepancy through label propagation. It is readily compatible with general GNNs and domain adaptation techniques with minimal adjustment through pseudo-labeling. Experiments on various real-world benchmarks show that our LP-TGNN outperforms baselines by a notable margin. We also validate and analyze each component of the proposed framework in the ablation study.
Discrepancies are Virtue: Weak-to-Strong Generalization through Lens of Intrinsic Dimension
Feb 07, 2025



Weak-to-strong (W2S) generalization is a type of finetuning (FT) where a strong (large) student model is trained on pseudo-labels generated by a weak teacher. Surprisingly, W2S FT often outperforms the weak teacher. We seek to understand this phenomenon through the observation that FT often occurs in intrinsically low-dimensional spaces. Leveraging the low intrinsic dimensionality of FT, we analyze W2S in the ridgeless regression setting from a variance reduction perspective. For a strong student - weak teacher pair with sufficiently expressive low-dimensional feature subspaces $\mathcal{V}_s, \mathcal{V}_w$, we provide an exact characterization of the variance that dominates the generalization error of W2S. This unveils a virtue of discrepancy between the strong and weak models in W2S: the variance of the weak teacher is inherited by the strong student in $\mathcal{V}_s \cap \mathcal{V}_w$, while reduced by a factor of $\dim(\mathcal{V}_s)/N$ in the subspace of discrepancy $\mathcal{V}_w \setminus \mathcal{V}_s$ with $N$ pseudo-labels for W2S. Further, our analysis casts light on the sample complexities and the scaling of performance gap recovery in W2S. The analysis is supported with experiments on both synthetic regression problems and real vision tasks.
Optimal Defenses Against Gradient Reconstruction Attacks
Nov 06, 2024



Federated Learning (FL) is designed to prevent data leakage through collaborative model training without centralized data storage. However, it remains vulnerable to gradient reconstruction attacks that recover original training data from shared gradients. To optimize the trade-off between data leakage and utility loss, we first derive a theoretical lower bound of reconstruction error (among all attackers) for the two standard methods: adding noise, and gradient pruning. We then customize these two defenses to be parameter- and model-specific and achieve the optimal trade-off between our obtained reconstruction lower bound and model utility. Experimental results validate that our methods outperform Gradient Noise and Gradient Pruning by protecting the training data better while also achieving better utility.
Beyond Interpretability: The Gains of Feature Monosemanticity on Model Robustness
Oct 27, 2024Deep learning models often suffer from a lack of interpretability due to polysemanticity, where individual neurons are activated by multiple unrelated semantics, resulting in unclear attributions of model behavior. Recent advances in monosemanticity, where neurons correspond to consistent and distinct semantics, have significantly improved interpretability but are commonly believed to compromise accuracy. In this work, we challenge the prevailing belief of the accuracy-interpretability tradeoff, showing that monosemantic features not only enhance interpretability but also bring concrete gains in model performance. Across multiple robust learning scenarios-including input and label noise, few-shot learning, and out-of-domain generalization-our results show that models leveraging monosemantic features significantly outperform those relying on polysemantic features. Furthermore, we provide empirical and theoretical understandings on the robustness gains of feature monosemanticity. Our preliminary analysis suggests that monosemanticity, by promoting better separation of feature representations, leads to more robust decision boundaries. This diverse evidence highlights the generality of monosemanticity in improving model robustness. As a first step in this new direction, we embark on exploring the learning benefits of monosemanticity beyond interpretability, supporting the long-standing hypothesis of linking interpretability and robustness. Code is available at \url{https://github.com/PKU-ML/Beyond_Interpretability}.
Greedy Output Approximation: Towards Efficient Structured Pruning for LLMs Without Retraining
Jul 26, 2024To remove redundant components of large language models (LLMs) without incurring significant computational costs, this work focuses on single-shot pruning without a retraining phase. We simplify the pruning process for Transformer-based LLMs by identifying a depth-2 pruning structure that functions independently. Additionally, we propose two inference-aware pruning criteria derived from the optimization perspective of output approximation, which outperforms traditional training-aware metrics such as gradient and Hessian. We also introduce a two-step reconstruction technique to mitigate pruning errors without model retraining. Experimental results demonstrate that our approach significantly reduces computational costs and hardware requirements while maintaining superior performance across various datasets and models.
Sketchy Moment Matching: Toward Fast and Provable Data Selection for Finetuning
Jul 08, 2024We revisit data selection in a modern context of finetuning from a fundamental perspective. Extending the classical wisdom of variance minimization in low dimensions to high-dimensional finetuning, our generalization analysis unveils the importance of additionally reducing bias induced by low-rank approximation. Inspired by the variance-bias tradeoff in high dimensions from the theory, we introduce Sketchy Moment Matching (SkMM), a scalable data selection scheme with two stages. (i) First, the bias is controlled using gradient sketching that explores the finetuning parameter space for an informative low-dimensional subspace $\mathcal{S}$; (ii) then the variance is reduced over $\mathcal{S}$ via moment matching between the original and selected datasets. Theoretically, we show that gradient sketching is fast and provably accurate: selecting $n$ samples by reducing variance over $\mathcal{S}$ preserves the fast-rate generalization $O(\dim(\mathcal{S})/n)$, independent of the parameter dimension. Empirically, we concretize the variance-bias balance via synthetic experiments and demonstrate the effectiveness of SkMM for finetuning in real vision tasks.
Stochastic Zeroth-Order Optimization under Strongly Convexity and Lipschitz Hessian: Minimax Sample Complexity
Jun 28, 2024Optimization of convex functions under stochastic zeroth-order feedback has been a major and challenging question in online learning. In this work, we consider the problem of optimizing second-order smooth and strongly convex functions where the algorithm is only accessible to noisy evaluations of the objective function it queries. We provide the first tight characterization for the rate of the minimax simple regret by developing matching upper and lower bounds. We propose an algorithm that features a combination of a bootstrapping stage and a mirror-descent stage. Our main technical innovation consists of a sharp characterization for the spherical-sampling gradient estimator under higher-order smoothness conditions, which allows the algorithm to optimally balance the bias-variance tradeoff, and a new iterative method for the bootstrapping stage, which maintains the performance for unbounded Hessian.