 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax and Adaptive Covariance Matrix Estimation under Differential Privacy
Mar 20, 2026The covariance matrix plays a fundamental role in the analysis of high-dimensional data. This paper studies minimax and adaptive estimation of high-dimensional bandable covariance matrices under differential privacy constraints. We propose a novel differentially private blockwise tridiagonal estimator that achieves minimax-optimal convergence rates under both the operator norm and the Frobenius norm. In contrast to the non-private setting, the privacy-induced error exhibits a polynomial dependence on the ambient dimension, revealing a substantial additional cost of privacy. To establish optimality, we develop a new differentially private van Trees inequality and construct carefully designed prior distributions to obtain matching minimax lower bounds. The proposed private van Trees inequality applies more broadly to general private estimation problems and is of independent interest. We further introduce an adaptive estimator that attains the optimal rate up to a logarithmic factor without prior knowledge of the decay parameter, based on a novel hierarchical tridiagonal approach. Numerical experiments corroborate the theoretical results and illustrate the fundamental privacy-accuracy trade-off.
PanguMotion: Continuous Driving Motion Forecasting with Pangu Transformers
Mar 17, 2026Motion forecasting is a core task in autonomous driving systems, aiming to accurately predict the future trajectories of surrounding agents to ensure driving safety. Existing methods typically process discrete driving scenes independently, neglecting the temporal continuity and historical context correlations inherent in real-world driving environments. This paper proposes PanguMotion, a motion forecasting framework for continuous driving scenarios that integrates Transformer blocks from the Pangu-1B large language model as feature enhancement modules into autonomous driving motion prediction architectures. We conduct experiments on the Argoverse 2 datasets processed by the RealMotion data reorganization strategy, transforming each independent scene into a continuous sequence to mimic real-world driving scenarios.
Several Supporting Evidences for the Adaptive Feature Program
Nov 12, 2025
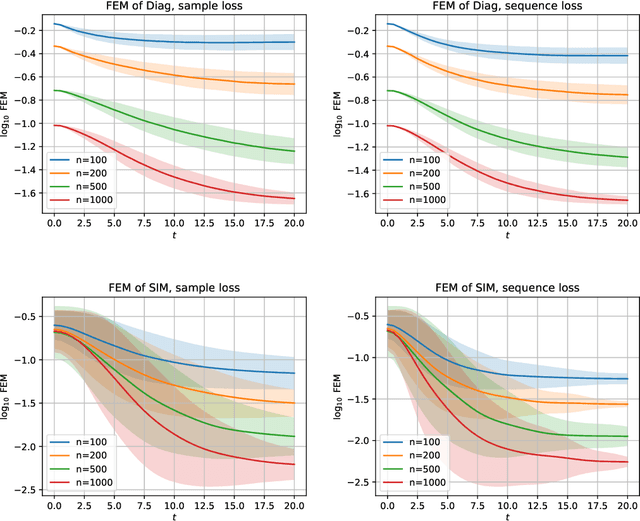
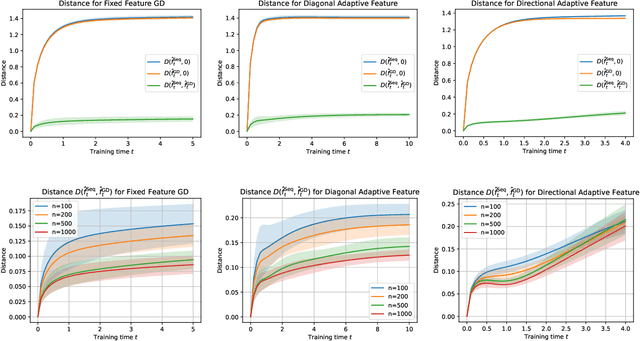
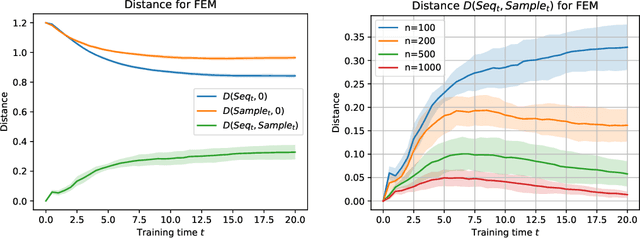
Theoretically exploring the advantages of neural networks might be one of the most challenging problems in the AI era. An adaptive feature program has recently been proposed to analyze the feature learning characteristic property of neural networks in a more abstract way. Motivated by the celebrated Le Cam equivalence, we advocate the over-parametrized sequence models to further simplify the analysis of the training dynamics of adaptive feature program and present several supporting evidences for the adaptive feature program. More precisely, after having introduced the feature error measure (FEM) to characterize the quality of the learned feature, we show that the FEM is decreasing during the training process of several concrete adaptive feature models including linear regression, single/multiple index models, etc. We believe that this hints at the potential successes of the adaptive feature program.
InstructAttribute: Fine-grained Object Attributes editing with Instruction
May 01, 2025Text-to-image (T2I) diffusion models, renowned for their advanced generative abilities, are extensively utilized in image editing applications, demonstrating remarkable effectiveness. However, achieving precise control over fine-grained attributes still presents considerable challenges. Existing image editing techniques either fail to modify the attributes of an object or struggle to preserve its structure and maintain consistency in other areas of the image. To address these challenges, we propose the Structure-Preserving and Attribute Amplification (SPAA), a training-free method which enables precise control over the color and material transformations of objects by editing the self-attention maps and cross-attention values. Furthermore, we constructed the Attribute Dataset, which encompasses nearly all colors and materials associated with various objects, by integrating multimodal large language models (MLLM) to develop an automated pipeline for data filtering and instruction labeling. Training on this dataset, we present our InstructAttribute, an instruction-based model designed to facilitate fine-grained editing of color and material attributes. Extensive experiments demonstrate that our method achieves superior performance in object-level color and material editing, outperforming existing instruction-based image editing approaches.
Euclidean Distance Matrix Completion via Asymmetric Projected Gradient Descent
Apr 28, 2025This paper proposes and analyzes a gradient-type algorithm based on Burer-Monteiro factorization, called the Asymmetric Projected Gradient Descent (APGD), for reconstructing the point set configuration from partial Euclidean distance measurements, known as the Euclidean Distance Matrix Completion (EDMC) problem. By paralleling the incoherence matrix completion framework, we show for the first time that global convergence guarantee with exact recovery of this routine can be established given $\mathcal{O}(\mu^2 r^3 \kappa^2 n \log n)$ Bernoulli random observations without any sample splitting. Unlike leveraging the tangent space Restricted Isometry Property (RIP) and local curvature of the low-rank embedding manifold in some very recent works, our proof provides new upper bounds to replace the random graph lemma under EDMC setting. The APGD works surprisingly well and numerical experiments demonstrate exact linear convergence behavior in rich-sample regions yet deteriorates fast when compared with the performance obtained by optimizing the s-stress function, i.e., the standard but unexplained non-convex approach for EDMC, if the sample size is limited. While virtually matching our theoretical prediction, this unusual phenomenon might indicate that: (i) the power of implicit regularization is weakened when specified in the APGD case; (ii) the stabilization of such new gradient direction requires substantially more samples than the information-theoretic limit would suggest.
TimeChat-Online: 80% Visual Tokens are Naturally Redundant in Streaming Videos
Apr 24, 2025The rapid growth of online video platforms, particularly live streaming services, has created an urgent need for real-time video understanding systems. These systems must process continuous video streams and respond to user queries instantaneously, presenting unique challenges for current Video Large Language Models (VideoLLMs). While existing VideoLLMs excel at processing complete videos, they face significant limitations in streaming scenarios due to their inability to handle dense, redundant frames efficiently. We introduce TimeChat-Online, a novel online VideoLLM that revolutionizes real-time video interaction. At its core lies our innovative Differential Token Drop (DTD) module, which addresses the fundamental challenge of visual redundancy in streaming videos. Drawing inspiration from human visual perception's Change Blindness phenomenon, DTD preserves meaningful temporal changes while filtering out static, redundant content between frames. Remarkably, our experiments demonstrate that DTD achieves an 82.8% reduction in video tokens while maintaining 98% performance on StreamingBench, revealing that over 80% of visual content in streaming videos is naturally redundant without requiring language guidance. To enable seamless real-time interaction, we present TimeChat-Online-139K, a comprehensive streaming video dataset featuring diverse interaction patterns including backward-tracing, current-perception, and future-responding scenarios. TimeChat-Online's unique Proactive Response capability, naturally achieved through continuous monitoring of video scene transitions via DTD, sets it apart from conventional approaches. Our extensive evaluation demonstrates TimeChat-Online's superior performance on streaming benchmarks (StreamingBench and OvOBench) and maintaining competitive results on long-form video tasks such as Video-MME and MLVU.
Neural Tangent Kernel of Neural Networks with Loss Informed by Differential Operators
Mar 14, 2025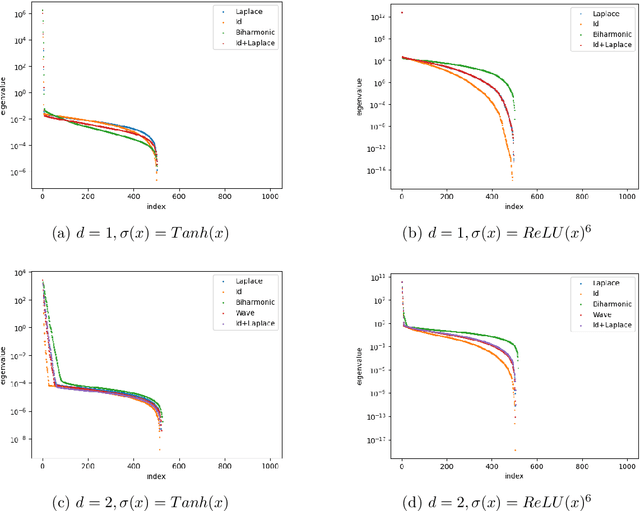

Spectral bias is a significant phenomenon in neural network training and can be explained by neural tangent kernel (NTK) theory. In this work, we develop the NTK theory for deep neural networks with physics-informed loss, providing insights into the convergence of NTK during initialization and training, and revealing its explicit structure. We find that, in most cases, the differential operators in the loss function do not induce a faster eigenvalue decay rate and stronger spectral bias. Some experimental results are also presented to verify the theory.
Discrepancies are Virtue: Weak-to-Strong Generalization through Lens of Intrinsic Dimension
Feb 07, 2025



Weak-to-strong (W2S) generalization is a type of finetuning (FT) where a strong (large) student model is trained on pseudo-labels generated by a weak teacher. Surprisingly, W2S FT often outperforms the weak teacher. We seek to understand this phenomenon through the observation that FT often occurs in intrinsically low-dimensional spaces. Leveraging the low intrinsic dimensionality of FT, we analyze W2S in the ridgeless regression setting from a variance reduction perspective. For a strong student - weak teacher pair with sufficiently expressive low-dimensional feature subspaces $\mathcal{V}_s, \mathcal{V}_w$, we provide an exact characterization of the variance that dominates the generalization error of W2S. This unveils a virtue of discrepancy between the strong and weak models in W2S: the variance of the weak teacher is inherited by the strong student in $\mathcal{V}_s \cap \mathcal{V}_w$, while reduced by a factor of $\dim(\mathcal{V}_s)/N$ in the subspace of discrepancy $\mathcal{V}_w \setminus \mathcal{V}_s$ with $N$ pseudo-labels for W2S. Further, our analysis casts light on the sample complexities and the scaling of performance gap recovery in W2S. The analysis is supported with experiments on both synthetic regression problems and real vision tasks.
Diagonal Over-parameterization in Reproducing Kernel Hilbert Spaces as an Adaptive Feature Model: Generalization and Adaptivity
Jan 15, 2025

This paper introduces a diagonal adaptive kernel model that dynamically learns kernel eigenvalues and output coefficients simultaneously during training. Unlike fixed-kernel methods tied to the neural tangent kernel theory, the diagonal adaptive kernel model adapts to the structure of the truth function, significantly improving generalization over fixed-kernel methods, especially when the initial kernel is misaligned with the target. Moreover, we show that the adaptivity comes from learning the right eigenvalues during training, showing a feature learning behavior. By extending to deeper parameterization, we further show how extra depth enhances adaptability and generalization. This study combines the insights from feature learning and implicit regularization and provides new perspective into the adaptivity and generalization potential of neural networks beyond the kernel regime.
Towards a Statistical Understanding of Neural Networks: Beyond the Neural Tangent Kernel Theories
Dec 25, 2024A primary advantage of neural networks lies in their feature learning characteristics, which is challenging to theoretically analyze due to the complexity of their training dynamics. We propose a new paradigm for studying feature learning and the resulting benefits in generalizability. After reviewing the neural tangent kernel (NTK) theory and recent results in kernel regression, which address the generalization issue of sufficiently wide neural networks, we examine limitations and implications of the fixed kernel theory (as the NTK theory) and review recent theoretical advancements in feature learning. Moving beyond the fixed kernel/feature theory, we consider neural networks as adaptive feature models. Finally, we propose an over-parameterized Gaussian sequence model as a prototype model to study the feature learning characteristics of neural networks.