Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Tangent Kernel of Neural Networks with Loss Informed by Differential Operators
Paper and Code
Mar 14, 2025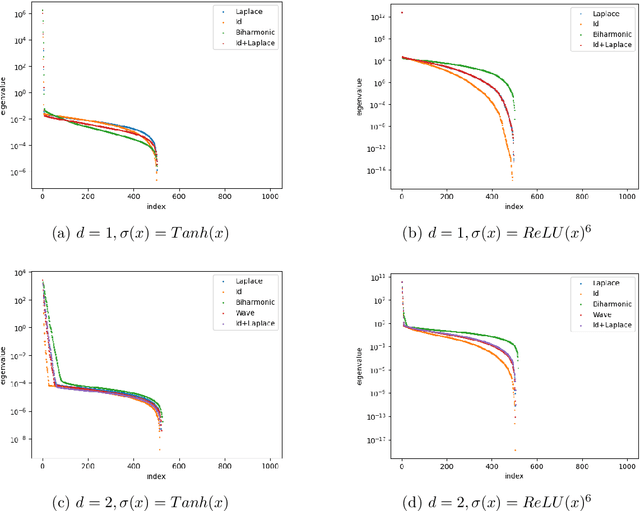

Spectral bias is a significant phenomenon in neural network training and can be explained by neural tangent kernel (NTK) theory. In this work, we develop the NTK theory for deep neural networks with physics-informed loss, providing insights into the convergence of NTK during initialization and training, and revealing its explicit structure. We find that, in most cases, the differential operators in the loss function do not induce a faster eigenvalue decay rate and stronger spectral bias. Some experimental results are also presented to verify the theory.
View paper on