 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Tangent Kernel of Neural Networks with Loss Informed by Differential Operators
Mar 14, 2025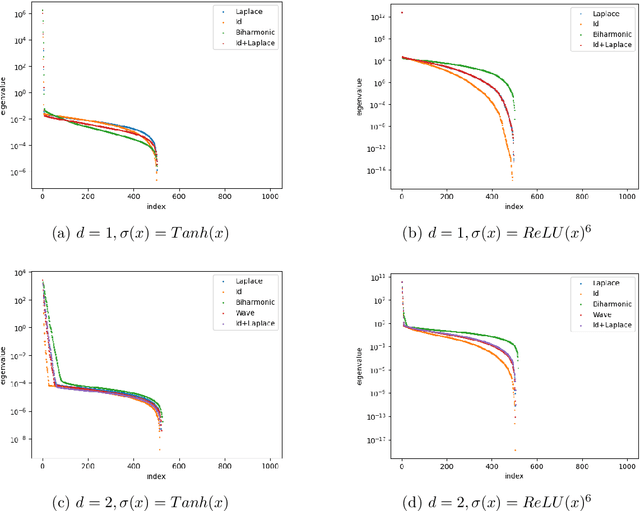

Spectral bias is a significant phenomenon in neural network training and can be explained by neural tangent kernel (NTK) theory. In this work, we develop the NTK theory for deep neural networks with physics-informed loss, providing insights into the convergence of NTK during initialization and training, and revealing its explicit structure. We find that, in most cases, the differential operators in the loss function do not induce a faster eigenvalue decay rate and stronger spectral bias. Some experimental results are also presented to verify the theory.
Generalization Error Curves for Analytic Spectral Algorithms under Power-law Decay
Jan 03, 2024The generalization error curve of certain kernel regression method aims at determining the exact order of generalization error with various source condition, noise level and choice of the regularization parameter rather than the minimax rate. In this work, under mild assumptions, we rigorously provide a full characterization of the generalization error curves of the kernel gradient descent method (and a large class of analytic spectral algorithms) in kernel regression. Consequently, we could sharpen the near inconsistency of kernel interpolation and clarify the saturation effects of kernel regression algorithms with higher qualification, etc. Thanks to the neural tangent kernel theory, these results greatly improve our understanding of the generalization behavior of training the wide neural networks. A novel technical contribution, the analytic functional argument, might be of independent interest.