 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
Jun 11, 2026We present MaxProof, a population-level test-time scaling framework for competition-level mathematical proof in the MiniMax-M3 series. M3 first trains three proof-oriented capabilities -- proof generation, proof verification, and critique-conditioned proof repair -- using a defense-in-depth generative verifier engineered for low false-positive rate. These capabilities are merged into a single released M3 model. At test time, MaxProof treats the model as a generator, verifier, refiner, and ranker, searches over a population of candidate proofs, and returns one final proof through tournament selection. With MaxProof test-time scaling, the M3 model reaches 35/42 on IMO 2025 and 36/42 on USAMO 2026, exceeding the human gold-medal threshold on both.
ABot-Earth 0.5: Generative 3D Earth Model
Jun 08, 2026We present ABot-Earth 0.5, a generative 3D framework designed to synthesize vast, seamless 3D environments from ubiquitous, geospatially referenced satellite imagery. To achieve this, we propose a novel generative model formulated directly with the 3D Gaussian Splatting (3DGS) representation. The model is trained on a diverse corpus of existing real-world urban reconstructions, learning to generate realistic geometry and textures. At inference, it synthesizes novel 3D scenes conditioned solely on satellite imagery at a scalable rate of under 10 minutes per square kilometer, while demonstrating exceptional realism. The framework is designed for accessibility, with integrated hierarchical level-of-detail (LOD) structures that permit real-time, interactive visualization on web-based map engines. This high-fidelity simulation sandbox effectively mitigates the sim-to-real domain gap, enabling critical downstream Embodied AI applications like closed-loop UAV navigation. By providing an ultra-low-cost and high-efficiency solution, ABot-Earth 0.5 significantly lowers the technical and financial barriers to large-scale 3D reconstruction and empowers the future of global digital earth visualization.
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
TextSculptor: Training and Benchmarking Scene Text Editing
May 20, 2026Recent advances in Multimodal Large Language Models (MLLMs) and diffusion-based generative models have substantially improved prompt-driven image editing. However, scene text editing remains challenging, as it requires models to precisely modify textual content while preserving visual realism and non-target regions. Current open-source models still lag behind proprietary systems, largely due to the scarcity of high-quality training data and the lack of standardized benchmarks tailored to text editing. To address these challenges, we present TextSculptor, a comprehensive framework for data construction and evaluation of scene text editing. We first develop an automated data construction pipeline that combines text-aware image synthesis with programmatic text rendering and compositing. Based on this pipeline, we build TextSculpt-Data, a large-scale dataset containing 3.2M training samples, including 1.2M OCR-verified text-to-image samples and 2M paired text editing samples with naturally aligned source-target images and strong background consistency. We further introduce TextSculpt-Bench, a benchmark covering four fundamental text editing tasks: text addition, text replacement, text removal, and hybrid editing. To support reliable evaluation, we design a tailored protocol that measures text accuracy, visual quality, and background preservation through OCR-based text alignment, multimodal judgment, and background-region similarity. Extensive experiments show that TextSculptor improves open-source text editing performance and narrows the gap to proprietary models. The data and benchmark are available at https://github.com/linyiheng123/TextSculptor.
Recovering 3D Shapes from Ultra-Fast Motion-Blurred Images
Feb 08, 2026We consider the problem of 3D shape recovery from ultra-fast motion-blurred images. While 3D reconstruction from static images has been extensively studied, recovering geometry from extreme motion-blurred images remains challenging. Such scenarios frequently occur in both natural and industrial settings, such as fast-moving objects in sports (e.g., balls) or rotating machinery, where rapid motion distorts object appearance and makes traditional 3D reconstruction techniques like Multi-View Stereo (MVS) ineffective. In this paper, we propose a novel inverse rendering approach for shape recovery from ultra-fast motion-blurred images. While conventional rendering techniques typically synthesize blur by averaging across multiple frames, we identify a major computational bottleneck in the repeated computation of barycentric weights. To address this, we propose a fast barycentric coordinate solver, which significantly reduces computational overhead and achieves a speedup of up to 4.57x, enabling efficient and photorealistic simulation of high-speed motion. Crucially, our method is fully differentiable, allowing gradients to propagate from rendered images to the underlying 3D shape, thereby facilitating shape recovery through inverse rendering. We validate our approach on two representative motion types: rapid translation and rotation. Experimental results demonstrate that our method enables efficient and realistic modeling of ultra-fast moving objects in the forward simulation. Moreover, it successfully recovers 3D shapes from 2D imagery of objects undergoing extreme translational and rotational motion, advancing the boundaries of vision-based 3D reconstruction. Project page: https://maxmilite.github.io/rec-from-ultrafast-blur/
M3SR: Multi-Scale Multi-Perceptual Mamba for Efficient Spectral Reconstruction
Jan 13, 2026The Mamba architecture has been widely applied to various low-level vision tasks due to its exceptional adaptability and strong performance. Although the Mamba architecture has been adopted for spectral reconstruction, it still faces the following two challenges: (1) Single spatial perception limits the ability to fully understand and analyze hyperspectral images; (2) Single-scale feature extraction struggles to capture the complex structures and fine details present in hyperspectral images. To address these issues, we propose a multi-scale, multi-perceptual Mamba architecture for the spectral reconstruction task, called M3SR. Specifically, we design a multi-perceptual fusion block to enhance the ability of the model to comprehensively understand and analyze the input features. By integrating the multi-perceptual fusion block into a U-Net structure, M3SR can effectively extract and fuse global, intermediate, and local features, thereby enabling accurate reconstruction of hyperspectral images at multiple scales. Extensive quantitative and qualitative experiments demonstrate that the proposed M3SR outperforms existing state-of-the-art methods while incurring a lower computational cost.
LSRIF: Logic-Structured Reinforcement Learning for Instruction Following
Jan 10, 2026Instruction-following is critical for large language models, but real-world instructions often contain logical structures such as sequential dependencies and conditional branching. Existing methods typically construct datasets with parallel constraints and optimize average rewards, ignoring logical dependencies and yielding noisy signals. We propose a logic-structured training framework LSRIF that explicitly models instruction logic. We first construct a dataset LSRInstruct with constraint structures such as parallel, sequential, and conditional types, and then design structure-aware rewarding method LSRIF including average aggregation for parallel structures, failure-penalty propagation for sequential structures, and selective rewards for conditional branches. Experiments show LSRIF brings significant improvements in instruction-following (in-domain and out-of-domain) and general reasoning. Analysis reveals that learning with explicit logic structures brings parameter updates in attention layers and sharpens token-level attention to constraints and logical operators.
ThinkGen: Generalized Thinking for Visual Generation
Dec 29, 2025Recent progress in Multimodal Large Language Models (MLLMs) demonstrates that Chain-of-Thought (CoT) reasoning enables systematic solutions to complex understanding tasks. However, its extension to generation tasks remains nascent and limited by scenario-specific mechanisms that hinder generalization and adaptation. In this work, we present ThinkGen, the first think-driven visual generation framework that explicitly leverages MLLM's CoT reasoning in various generation scenarios. ThinkGen employs a decoupled architecture comprising a pretrained MLLM and a Diffusion Transformer (DiT), wherein the MLLM generates tailored instructions based on user intent, and DiT produces high-quality images guided by these instructions. We further propose a separable GRPO-based training paradigm (SepGRPO), alternating reinforcement learning between the MLLM and DiT modules. This flexible design enables joint training across diverse datasets, facilitating effective CoT reasoning for a wide range of generative scenarios. Extensive experiments demonstrate that ThinkGen achieves robust, state-of-the-art performance across multiple generation benchmarks. Code is available: https://github.com/jiaosiyuu/ThinkGen
From Orbit to Ground: Generative City Photogrammetry from Extreme Off-Nadir Satellite Images
Dec 09, 2025City-scale 3D reconstruction from satellite imagery presents the challenge of extreme viewpoint extrapolation, where our goal is to synthesize ground-level novel views from sparse orbital images with minimal parallax. This requires inferring nearly $90^\circ$ viewpoint gaps from image sources with severely foreshortened facades and flawed textures, causing state-of-the-art reconstruction engines such as NeRF and 3DGS to fail. To address this problem, we propose two design choices tailored for city structures and satellite inputs. First, we model city geometry as a 2.5D height map, implemented as a Z-monotonic signed distance field (SDF) that matches urban building layouts from top-down viewpoints. This stabilizes geometry optimization under sparse, off-nadir satellite views and yields a watertight mesh with crisp roofs and clean, vertically extruded facades. Second, we paint the mesh appearance from satellite images via differentiable rendering techniques. While the satellite inputs may contain long-range, blurry captures, we further train a generative texture restoration network to enhance the appearance, recovering high-frequency, plausible texture details from degraded inputs. Our method's scalability and robustness are demonstrated through extensive experiments on large-scale urban reconstruction. For example, in our teaser figure, we reconstruct a $4\,\mathrm{km}^2$ real-world region from only a few satellite images, achieving state-of-the-art performance in synthesizing photorealistic ground views. The resulting models are not only visually compelling but also serve as high-fidelity, application-ready assets for downstream tasks like urban planning and simulation. Project page can be found at https://pku-vcl-geometry.github.io/Orbit2Ground/.
Open-World 3D Scene Graph Generation for Retrieval-Augmented Reasoning
Nov 08, 2025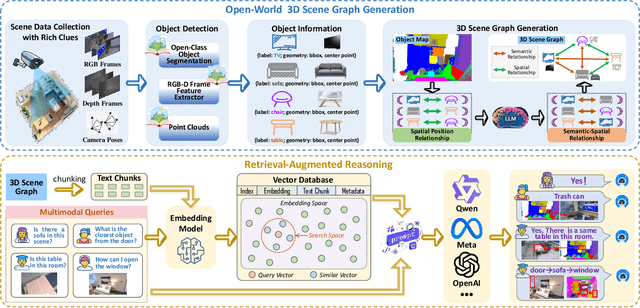

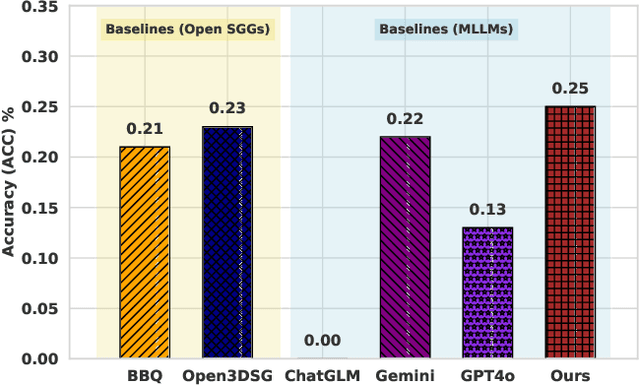
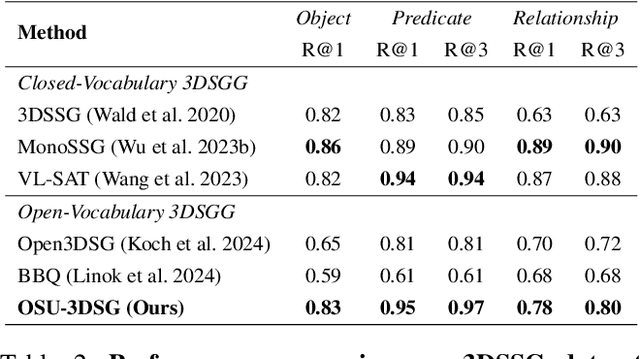
Understanding 3D scenes in open-world settings poses fundamental challenges for vision and robotics, particularly due to the limitations of closed-vocabulary supervision and static annotations. To address this, we propose a unified framework for Open-World 3D Scene Graph Generation with Retrieval-Augmented Reasoning, which enables generalizable and interactive 3D scene understanding. Our method integrates Vision-Language Models (VLMs) with retrieval-based reasoning to support multimodal exploration and language-guided interaction. The framework comprises two key components: (1) a dynamic scene graph generation module that detects objects and infers semantic relationships without fixed label sets, and (2) a retrieval-augmented reasoning pipeline that encodes scene graphs into a vector database to support text/image-conditioned queries. We evaluate our method on 3DSSG and Replica benchmarks across four tasks-scene question answering, visual grounding, instance retrieval, and task planning-demonstrating robust generalization and superior performance in diverse environments. Our results highlight the effectiveness of combining open-vocabulary perception with retrieval-based reasoning for scalable 3D scene understanding.