 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINDGAMES: A Live Arena for Evaluating Social and Strategic Reasoning in Multi-Agent LLMs
May 28, 2026Large language models (LLMs) are increasingly deployed as interactive agents, yet their capacity for social and strategic reasoning over extended interaction remains poorly understood. Existing evaluations rely on static vignettes or single-game benchmarks that cannot capture the sustained, multi-faceted reasoning that real-world multi-agent settings demand. We introduce Mindgames, a multi-game arena and evaluation platform for LLM agents that operationalizes complementary reasoning demands relevant to ``theory of mind'': belief attribution under hidden information, opponent modeling through repeated strategic interaction, cooperative inference under knowledge asymmetries, and sustained deception in social deduction. Built on TextArena, Mindgames provides a unified interaction interface, TrueSkill-based rating, and full trajectory logging across four game environments. We instantiate Mindgames through a 2025 competition cycle hosted at a major AI conference, which assessed 944 submitted agents from 76 teams across four games: Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, and Secret Mafia. Our analysis surfaces both agent-level and evaluation-level limitations: brittle rule adherence remains a major bottleneck, top-performing systems repeatedly rely on explicit structural scaffolding, and leaderboard validity differs sharply across environments. In particular, failure-heavy environments can reward robustness to opponent errors as much as strategic ability, with Secret Mafia exhibiting a pronounced error-survival confound in this cycle. We release a dataset of 29,571 multi-agent games with turn-level observations, actions, and rewards, together with MG-Ref, a deterministic offline tournament protocol that scores new agents against a frozen reference pool of top-ranked, low-error Stage~II submissions under the same error-attribution lens used in this analysis.
AutoScout: Structured Optimization for Automating ML System Configuration
Mar 12, 2026Machine learning (ML) systems expose a rapidly expanding configuration space spanning model-parallelism strategies, communication optimizations, and low-level runtime parameters. End-to-end system efficiency is highly sensitive to these choices, yet identifying high-performance configurations is challenging due to heterogeneous feature types (e.g., sparse and dense parameters), conditional dependencies (e.g., valid execution parameters only under specific upstream decisions), and the high search (profiling) cost. Existing approaches either optimize a narrow subset of configuration dimensions or rely on ad-hoc heuristics that fail to generalize as configuration spaces continue to grow. We present AutoScout, a general-purpose systems configurator for ML training, fine-tuning, and inference. It formulates the system configuration as a mixed-discrete/continuous optimization problem with hierarchical dependencies and introduces a hybrid optimization framework that jointly refines sparse structural decisions and dense execution parameters. To reduce profiling cost, AutoScout adaptively prioritizes high-impact configuration features and ensembles simulators with varying fidelity. Across diverse models, hardware platforms, and deployment objectives, AutoScout consistently identifies high-performance configurations, achieving 2.7-3.0$\times$ training speedup over expert-tuned settings.
Automatic Robustness Stress Testing of LLMs as Mathematical Problem Solvers
Jun 05, 2025Large language models (LLMs) have achieved distinguished performance on various reasoning-intensive tasks. However, LLMs might still face the challenges of robustness issues and fail unexpectedly in some simple reasoning tasks. Previous works evaluate the LLM robustness with hand-crafted templates or a limited set of perturbation rules, indicating potential data contamination in pre-training or fine-tuning datasets. In this work, inspired by stress testing in software engineering, we propose a novel framework, Automatic Robustness Checker (AR-Checker), to generate mathematical problem variants that maintain the semantic meanings of the original one but might fail the LLMs. The AR-Checker framework generates mathematical problem variants through multi-round parallel streams of LLM-based rewriting and verification. Our framework can generate benchmark variants dynamically for each LLM, thus minimizing the risk of data contamination. Experiments on GSM8K and MATH-500 demonstrate the strong performance of AR-Checker on mathematical tasks. We also evaluate AR-Checker on benchmarks beyond mathematics, including MMLU, MMLU-Pro, and CommonsenseQA, where it also achieves strong performance, further proving the effectiveness of AR-Checker.
Circinus: Efficient Query Planner for Compound ML Serving
Apr 23, 2025



The rise of compound AI serving -- integrating multiple operators in a pipeline that may span edge and cloud tiers -- enables end-user applications such as autonomous driving, generative AI-powered meeting companions, and immersive gaming. Achieving high service goodput -- i.e., meeting service level objectives (SLOs) for pipeline latency, accuracy, and costs -- requires effective planning of operator placement, configuration, and resource allocation across infrastructure tiers. However, the diverse SLO requirements, varying edge capabilities, and high query volumes create an enormous planning search space, rendering current solutions fundamentally limited for real-time serving and cost-efficient deployments. This paper presents Circinus, an SLO-aware query planner for large-scale compound AI workloads. Circinus novelly decomposes multi-query planning and multi-dimensional SLO objectives while preserving global decision quality. By exploiting plan similarities within and across queries, it significantly reduces search steps. It further improves per-step efficiency with a precision-aware plan profiler that incrementally profiles and strategically applies early stopping based on imprecise estimates of plan performance. At scale, Circinus selects query-plan combinations to maximize global SLO goodput. Evaluations in real-world settings show that Circinus improves service goodput by 3.2-5.0$\times$, accelerates query planning by 4.2-5.8$\times$, achieving query response in seconds, while reducing deployment costs by 3.2-4.0$\times$ over state of the arts even in their intended single-tier deployments.
Open Deep Search: Democratizing Search with Open-source Reasoning Agents
Mar 26, 2025We introduce Open Deep Search (ODS) to close the increasing gap between the proprietary search AI solutions, such as Perplexity's Sonar Reasoning Pro and OpenAI's GPT-4o Search Preview, and their open-source counterparts. The main innovation introduced in ODS is to augment the reasoning capabilities of the latest open-source LLMs with reasoning agents that can judiciously use web search tools to answer queries. Concretely, ODS consists of two components that work with a base LLM chosen by the user: Open Search Tool and Open Reasoning Agent. Open Reasoning Agent interprets the given task and completes it by orchestrating a sequence of actions that includes calling tools, one of which is the Open Search Tool. Open Search Tool is a novel web search tool that outperforms proprietary counterparts. Together with powerful open-source reasoning LLMs, such as DeepSeek-R1, ODS nearly matches and sometimes surpasses the existing state-of-the-art baselines on two benchmarks: SimpleQA and FRAMES. For example, on the FRAMES evaluation benchmark, ODS improves the best existing baseline of the recently released GPT-4o Search Preview by 9.7% in accuracy. ODS is a general framework for seamlessly augmenting any LLMs -- for example, DeepSeek-R1 that achieves 82.4% on SimpleQA and 30.1% on FRAMES -- with search and reasoning capabilities to achieve state-of-the-art performance: 88.3% on SimpleQA and 75.3% on FRAMES.
Bottleneck Analysis of Dynamic Graph Neural Network Inference on CPU and GPU
Oct 08, 2022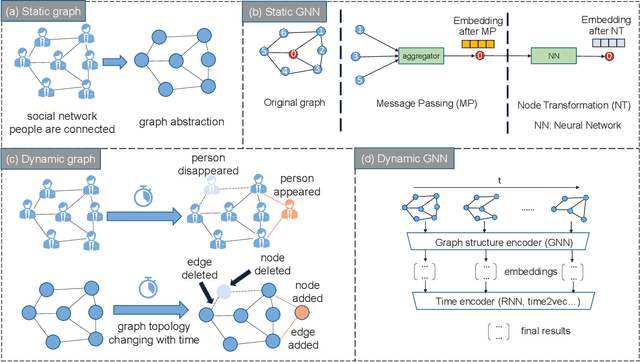
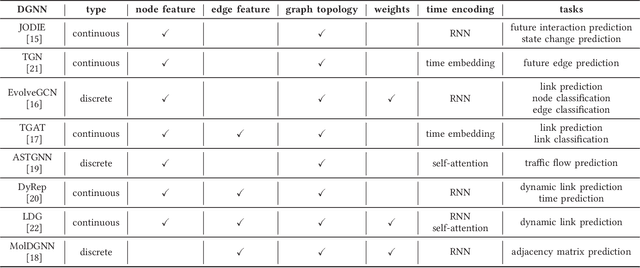
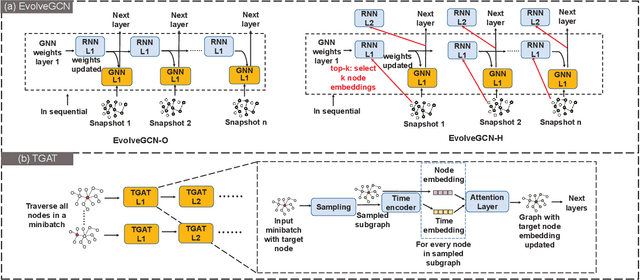
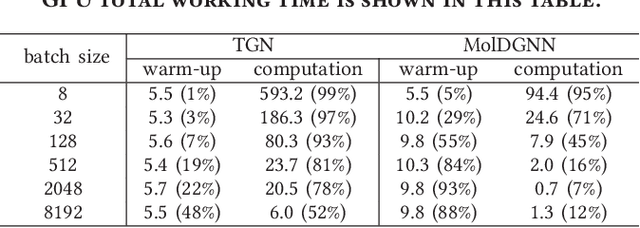
Dynamic graph neural network (DGNN) is becoming increasingly popular because of its widespread use in capturing dynamic features in the real world. A variety of dynamic graph neural networks designed from algorithmic perspectives have succeeded in incorporating temporal information into graph processing. Despite the promising algorithmic performance, deploying DGNNs on hardware presents additional challenges due to the model complexity, diversity, and the nature of the time dependency. Meanwhile, the differences between DGNNs and static graph neural networks make hardware-related optimizations for static graph neural networks unsuitable for DGNNs. In this paper, we select eight prevailing DGNNs with different characteristics and profile them on both CPU and GPU. The profiling results are summarized and analyzed, providing in-depth insights into the bottlenecks of DGNNs on hardware and identifying potential optimization opportunities for future DGNN acceleration. Followed by a comprehensive survey, we provide a detailed analysis of DGNN performance bottlenecks on hardware, including temporal data dependency, workload imbalance, data movement, and GPU warm-up. We suggest several optimizations from both software and hardware perspectives. This paper is the first to provide an in-depth analysis of the hardware performance of DGNN Code is available at https://github.com/sharc-lab/DGNN_analysis.
Turbo Autoencoder with a Trainable Interleaver
Nov 22, 2021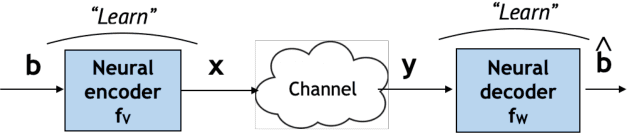
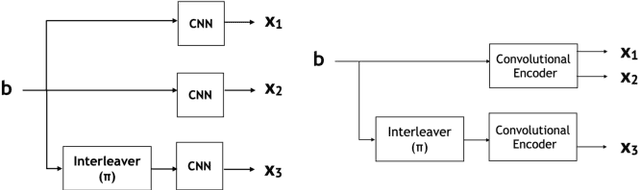
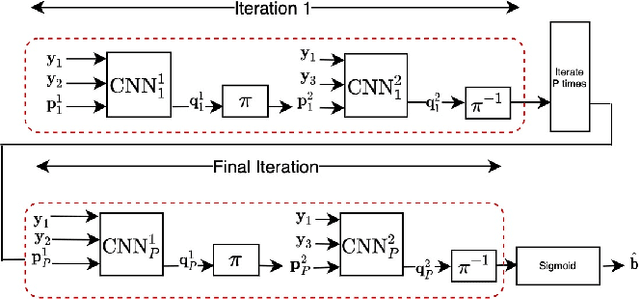
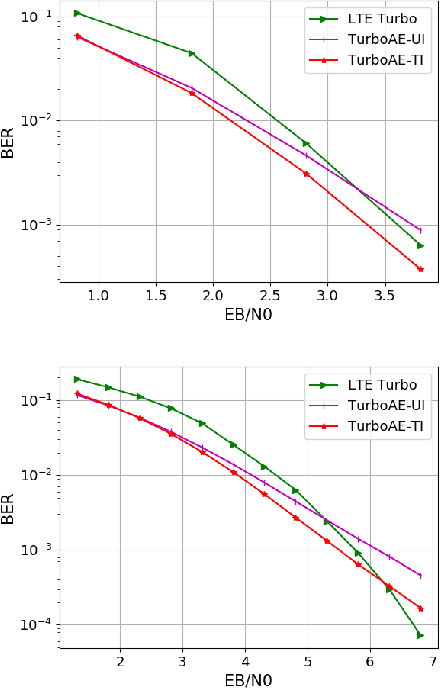
A critical aspect of reliable communication involves the design of codes that allow transmissions to be robustly and computationally efficiently decoded under noisy conditions. Advances in the design of reliable codes have been driven by coding theory and have been sporadic. Recently, it is shown that channel codes that are comparable to modern codes can be learned solely via deep learning. In particular, Turbo Autoencoder (TURBOAE), introduced by Jiang et al., is shown to achieve the reliability of Turbo codes for Additive White Gaussian Noise channels. In this paper, we focus on applying the idea of TURBOAE to various practical channels, such as fading channels and chirp noise channels. We introduce TURBOAE-TI, a novel neural architecture that combines TURBOAE with a trainable interleaver design. We develop a carefully-designed training procedure and a novel interleaver penalty function that are crucial in learning the interleaver and TURBOAE jointly. We demonstrate that TURBOAE-TI outperforms TURBOAE and LTE Turbo codes for several channels of interest. We also provide interpretation analysis to better understand TURBOAE-TI.
Deepcode and Modulo-SK are Designed for Different Settings
Aug 18, 2020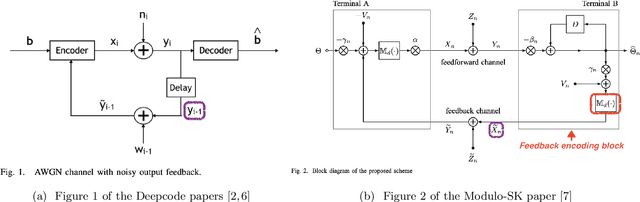

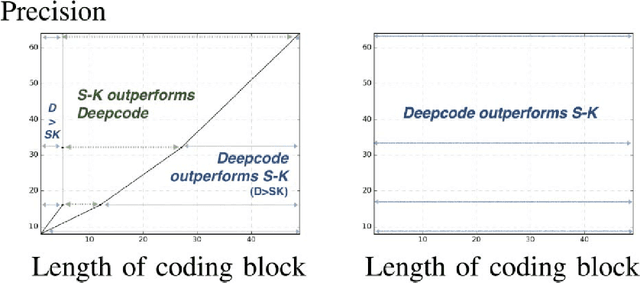
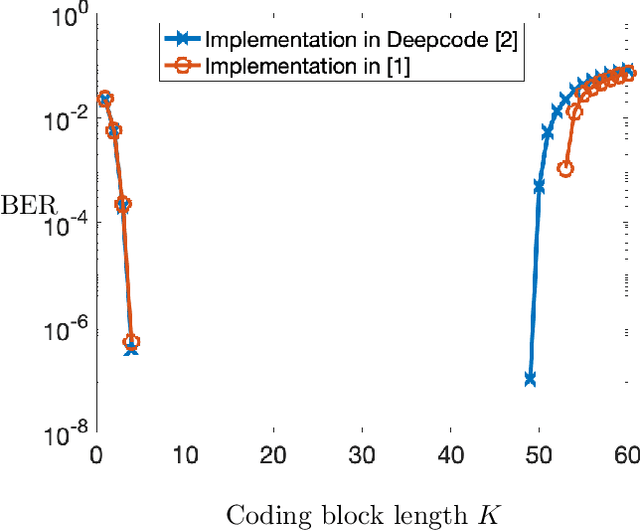
We respond to [1] which claimed that "Modulo-SK scheme outperforms Deepcode [2]". We demonstrate that this statement is not true: the two schemes are designed and evaluated for entirely different settings. DeepCode is designed and evaluated for the AWGN channel with (potentially delayed) uncoded output feedback. Modulo-SK is evaluated on the AWGN channel with coded feedback and unit delay. [1] also claimed an implementation of Schalkwijk and Kailath (SK) [3] which was numerically stable for any number of information bits and iterations. However, we observe that while their implementation does marginally improve over ours, it also suffers from a fundamental issue with precision. Finally, we show that Deepcode dominates the optimized performance of SK, over a natural choice of parameterizations when the feedback is noisy.
Turbo Autoencoder: Deep learning based channel codes for point-to-point communication channels
Nov 08, 2019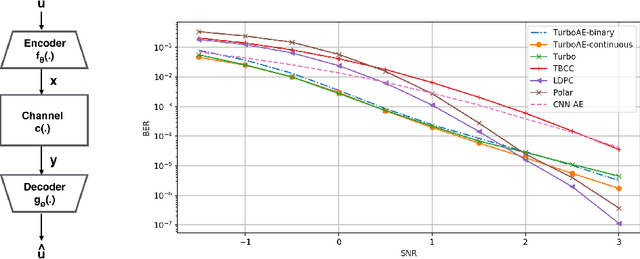

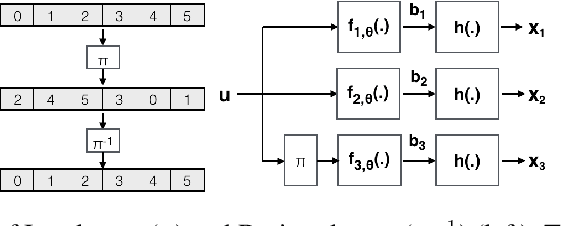

Designing codes that combat the noise in a communication medium has remained a significant area of research in information theory as well as wireless communications. Asymptotically optimal channel codes have been developed by mathematicians for communicating under canonical models after over 60 years of research. On the other hand, in many non-canonical channel settings, optimal codes do not exist and the codes designed for canonical models are adapted via heuristics to these channels and are thus not guaranteed to be optimal. In this work, we make significant progress on this problem by designing a fully end-to-end jointly trained neural encoder and decoder, namely, Turbo Autoencoder (TurboAE), with the following contributions: ($a$) under moderate block lengths, TurboAE approaches state-of-the-art performance under canonical channels; ($b$) moreover, TurboAE outperforms the state-of-the-art codes under non-canonical settings in terms of reliability. TurboAE shows that the development of channel coding design can be automated via deep learning, with near-optimal performance.
Improving Federated Learning Personalization via Model Agnostic Meta Learning
Sep 27, 2019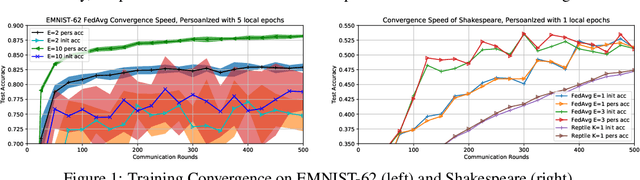
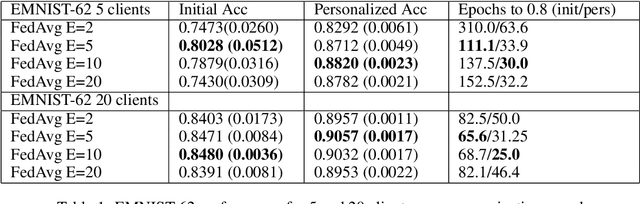
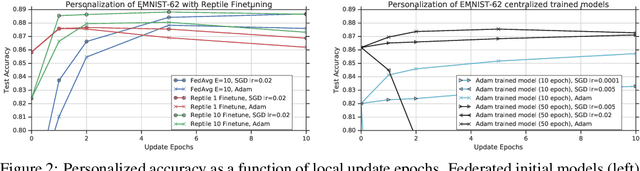

Federated Learning (FL) refers to learning a high quality global model based on decentralized data storage, without ever copying the raw data. A natural scenario arises with data created on mobile phones by the activity of their users. Given the typical data heterogeneity in such situations, it is natural to ask how can the global model be personalized for every such device, individually. In this work, we point out that the setting of Model Agnostic Meta Learning (MAML), where one optimizes for a fast, gradient-based, few-shot adaptation to a heterogeneous distribution of tasks, has a number of similarities with the objective of personalization for FL. We present FL as a natural source of practical applications for MAML algorithms, and make the following observations. 1) The popular FL algorithm, Federated Averaging, can be interpreted as a meta learning algorithm. 2) Careful fine-tuning can yield a global model with higher accuracy, which is at the same time easier to personalize. However, solely optimizing for the global model accuracy yields a weaker personalization result. 3) A model trained using a standard datacenter optimization method is much harder to personalize, compared to one trained using Federated Averaging, supporting the first claim. These results raise new questions for FL, MAML, and broader ML research.