 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Mixture-of-Agents Serving via Tree-Structured Routing, Adaptive Pruning, and Dependency-Aware Prefill-Decode Overlap
Dec 19, 2025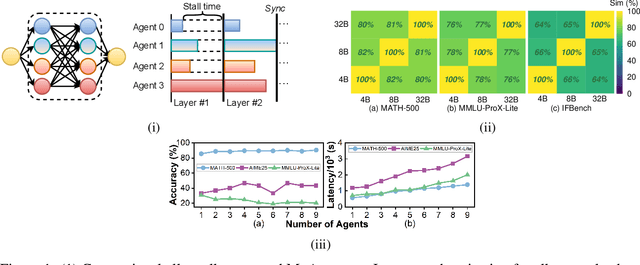
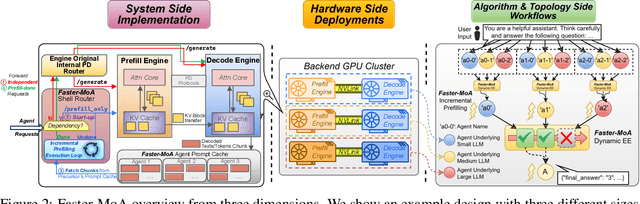
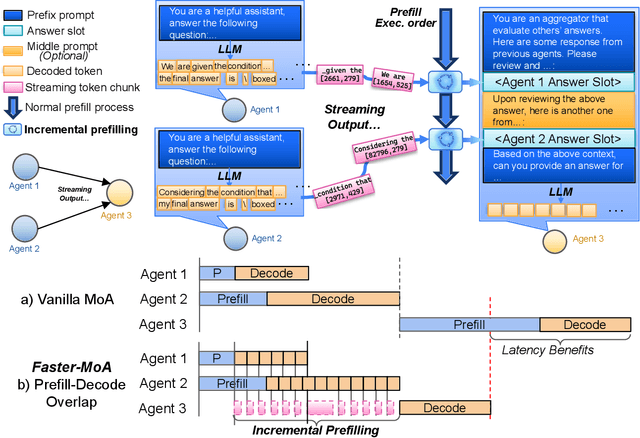
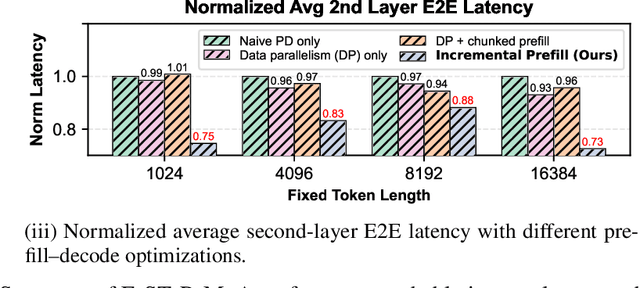
Mixture-of-Agents (MoA) inference can suffer from dense inter-agent communication and low hardware utilization, which jointly inflate serving latency. We present a serving design that targets these bottlenecks through an algorithm-system co-design. First, we replace dense agent interaction graphs with a hierarchical tree topology that induces structured sparsity in inter-agent communication. Second, we introduce a runtime adaptive mechanism that selectively terminates or skips downstream agent invocations using semantic agreement and confidence signals from intermediate outputs. Third, we pipeline agent execution by overlapping incremental prefilling with decoding across dependency-related agents, improving utilization and reducing inference latency. Across representative tasks, this approach substantially reduces end-to-end latency (up to 90%) while maintaining comparable accuracy (within $\pm$1%) relative to dense-connectivity MoA baselines, and can improve accuracy in certain settings.
Residual-INR: Communication Efficient On-Device Learning Using Implicit Neural Representation
Aug 10, 2024



Edge computing is a distributed computing paradigm that collects and processes data at or near the source of data generation. The on-device learning at edge relies on device-to-device wireless communication to facilitate real-time data sharing and collaborative decision-making among multiple devices. This significantly improves the adaptability of the edge computing system to the changing environments. However, as the scale of the edge computing system is getting larger, communication among devices is becoming the bottleneck because of the limited bandwidth of wireless communication leads to large data transfer latency. To reduce the amount of device-to-device data transmission and accelerate on-device learning, in this paper, we propose Residual-INR, a fog computing-based communication-efficient on-device learning framework by utilizing implicit neural representation (INR) to compress images/videos into neural network weights. Residual-INR enhances data transfer efficiency by collecting JPEG images from edge devices, compressing them into INR format at the fog node, and redistributing them for on-device learning. By using a smaller INR for full image encoding and a separate object INR for high-quality object region reconstruction through residual encoding, our technique can reduce the encoding redundancy while maintaining the object quality. Residual-INR is a promising solution for edge on-device learning because it reduces data transmission by up to 5.16 x across a network of 10 edge devices. It also facilitates CPU-free accelerated on-device learning, achieving up to 2.9 x speedup without sacrificing accuracy. Our code is available at: https://github.com/sharclab/Residual-INR.
HLSFactory: A Framework Empowering High-Level Synthesis Datasets for Machine Learning and Beyond
May 01, 2024Machine learning (ML) techniques have been applied to high-level synthesis (HLS) flows for quality-of-result (QoR) prediction and design space exploration (DSE). Nevertheless, the scarcity of accessible high-quality HLS datasets and the complexity of building such datasets present challenges. Existing datasets have limitations in terms of benchmark coverage, design space enumeration, vendor extensibility, or lack of reproducible and extensible software for dataset construction. Many works also lack user-friendly ways to add more designs, limiting wider adoption of such datasets. In response to these challenges, we introduce HLSFactory, a comprehensive framework designed to facilitate the curation and generation of high-quality HLS design datasets. HLSFactory has three main stages: 1) a design space expansion stage to elaborate single HLS designs into large design spaces using various optimization directives across multiple vendor tools, 2) a design synthesis stage to execute HLS and FPGA tool flows concurrently across designs, and 3) a data aggregation stage for extracting standardized data into packaged datasets for ML usage. This tripartite architecture ensures broad design space coverage via design space expansion and supports multiple vendor tools. Users can contribute to each stage with their own HLS designs and synthesis results and extend the framework itself with custom frontends and tool flows. We also include an initial set of built-in designs from common HLS benchmarks curated open-source HLS designs. We showcase the versatility and multi-functionality of our framework through six case studies: I) Design space sampling; II) Fine-grained parallelism backend speedup; III) Targeting Intel's HLS flow; IV) Adding new auxiliary designs; V) Integrating published HLS data; VI) HLS tool version regression benchmarking. Code at https://github.com/sharc-lab/HLSFactory.
Rapid-INR: Storage Efficient CPU-free DNN Training Using Implicit Neural Representation
Jun 29, 2023Implicit Neural Representation (INR) is an innovative approach for representing complex shapes or objects without explicitly defining their geometry or surface structure. Instead, INR represents objects as continuous functions. Previous research has demonstrated the effectiveness of using neural networks as INR for image compression, showcasing comparable performance to traditional methods such as JPEG. However, INR holds potential for various applications beyond image compression. This paper introduces Rapid-INR, a novel approach that utilizes INR for encoding and compressing images, thereby accelerating neural network training in computer vision tasks. Our methodology involves storing the whole dataset directly in INR format on a GPU, mitigating the significant data communication overhead between the CPU and GPU during training. Additionally, the decoding process from INR to RGB format is highly parallelized and executed on-the-fly. To further enhance compression, we propose iterative and dynamic pruning, as well as layer-wise quantization, building upon previous work. We evaluate our framework on the image classification task, utilizing the ResNet-18 backbone network and three commonly used datasets with varying image sizes. Rapid-INR reduces memory consumption to only 5% of the original dataset size and achieves a maximum 6$\times$ speedup over the PyTorch training pipeline, as well as a maximum 1.2x speedup over the DALI training pipeline, with only a marginal decrease in accuracy. Importantly, Rapid-INR can be readily applied to other computer vision tasks and backbone networks with reasonable engineering efforts. Our implementation code is publicly available at https://anonymous.4open.science/r/INR-4BF7.
DGNN-Booster: A Generic FPGA Accelerator Framework For Dynamic Graph Neural Network Inference
Apr 13, 2023



Dynamic Graph Neural Networks (DGNNs) are becoming increasingly popular due to their effectiveness in analyzing and predicting the evolution of complex interconnected graph-based systems. However, hardware deployment of DGNNs still remains a challenge. First, DGNNs do not fully utilize hardware resources because temporal data dependencies cause low hardware parallelism. Additionally, there is currently a lack of generic DGNN hardware accelerator frameworks, and existing GNN accelerator frameworks have limited ability to handle dynamic graphs with changing topologies and node features. To address the aforementioned challenges, in this paper, we propose DGNN-Booster, which is a novel Field-Programmable Gate Array (FPGA) accelerator framework for real-time DGNN inference using High-Level Synthesis (HLS). It includes two different FPGA accelerator designs with different dataflows that can support the most widely used DGNNs. We showcase the effectiveness of our designs by implementing and evaluating two representative DGNN models on ZCU102 board and measuring the end-to-end performance. The experiment results demonstrate that DGNN-Booster can achieve a speedup of up to 5.6x compared to the CPU baseline (6226R), 8.4x compared to the GPU baseline (A6000) and 2.1x compared to the FPGA baseline without applying optimizations proposed in this paper. Moreover, DGNN-Booster can achieve over 100x and over 1000x runtime energy efficiency than the CPU and GPU baseline respectively. Our implementation code and on-board measurements are publicly available at https://github.com/sharc-lab/DGNN-Booster.
Bottleneck Analysis of Dynamic Graph Neural Network Inference on CPU and GPU
Oct 08, 2022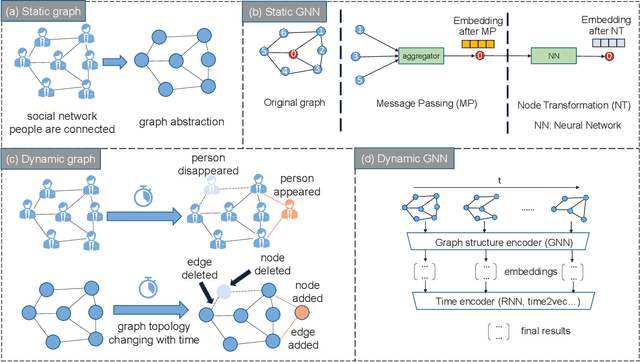
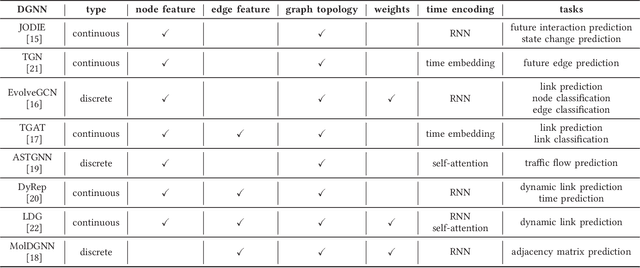
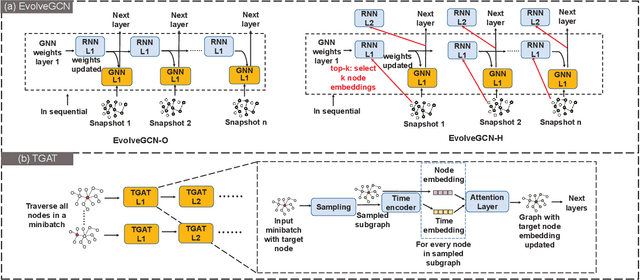
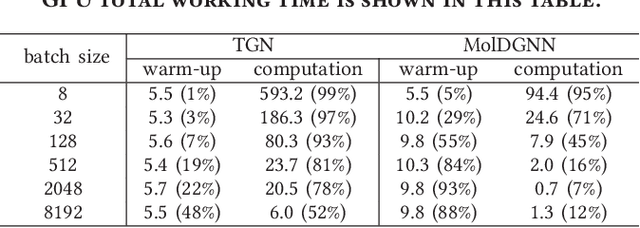
Dynamic graph neural network (DGNN) is becoming increasingly popular because of its widespread use in capturing dynamic features in the real world. A variety of dynamic graph neural networks designed from algorithmic perspectives have succeeded in incorporating temporal information into graph processing. Despite the promising algorithmic performance, deploying DGNNs on hardware presents additional challenges due to the model complexity, diversity, and the nature of the time dependency. Meanwhile, the differences between DGNNs and static graph neural networks make hardware-related optimizations for static graph neural networks unsuitable for DGNNs. In this paper, we select eight prevailing DGNNs with different characteristics and profile them on both CPU and GPU. The profiling results are summarized and analyzed, providing in-depth insights into the bottlenecks of DGNNs on hardware and identifying potential optimization opportunities for future DGNN acceleration. Followed by a comprehensive survey, we provide a detailed analysis of DGNN performance bottlenecks on hardware, including temporal data dependency, workload imbalance, data movement, and GPU warm-up. We suggest several optimizations from both software and hardware perspectives. This paper is the first to provide an in-depth analysis of the hardware performance of DGNN Code is available at https://github.com/sharc-lab/DGNN_analysis.