 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHLSFactory: A Framework Empowering High-Level Synthesis Datasets for Machine Learning and Beyond
May 01, 2024Machine learning (ML) techniques have been applied to high-level synthesis (HLS) flows for quality-of-result (QoR) prediction and design space exploration (DSE). Nevertheless, the scarcity of accessible high-quality HLS datasets and the complexity of building such datasets present challenges. Existing datasets have limitations in terms of benchmark coverage, design space enumeration, vendor extensibility, or lack of reproducible and extensible software for dataset construction. Many works also lack user-friendly ways to add more designs, limiting wider adoption of such datasets. In response to these challenges, we introduce HLSFactory, a comprehensive framework designed to facilitate the curation and generation of high-quality HLS design datasets. HLSFactory has three main stages: 1) a design space expansion stage to elaborate single HLS designs into large design spaces using various optimization directives across multiple vendor tools, 2) a design synthesis stage to execute HLS and FPGA tool flows concurrently across designs, and 3) a data aggregation stage for extracting standardized data into packaged datasets for ML usage. This tripartite architecture ensures broad design space coverage via design space expansion and supports multiple vendor tools. Users can contribute to each stage with their own HLS designs and synthesis results and extend the framework itself with custom frontends and tool flows. We also include an initial set of built-in designs from common HLS benchmarks curated open-source HLS designs. We showcase the versatility and multi-functionality of our framework through six case studies: I) Design space sampling; II) Fine-grained parallelism backend speedup; III) Targeting Intel's HLS flow; IV) Adding new auxiliary designs; V) Integrating published HLS data; VI) HLS tool version regression benchmarking. Code at https://github.com/sharc-lab/HLSFactory.
INR-Arch: A Dataflow Architecture and Compiler for Arbitrary-Order Gradient Computations in Implicit Neural Representation Processing
Aug 11, 2023



An increasing number of researchers are finding use for nth-order gradient computations for a wide variety of applications, including graphics, meta-learning (MAML), scientific computing, and most recently, implicit neural representations (INRs). Recent work shows that the gradient of an INR can be used to edit the data it represents directly without needing to convert it back to a discrete representation. However, given a function represented as a computation graph, traditional architectures face challenges in efficiently computing its nth-order gradient due to the higher demand for computing power and higher complexity in data movement. This makes it a promising target for FPGA acceleration. In this work, we introduce INR-Arch, a framework that transforms the computation graph of an nth-order gradient into a hardware-optimized dataflow architecture. We address this problem in two phases. First, we design a dataflow architecture that uses FIFO streams and an optimized computation kernel library, ensuring high memory efficiency and parallel computation. Second, we propose a compiler that extracts and optimizes computation graphs, automatically configures hardware parameters such as latency and stream depths to optimize throughput, while ensuring deadlock-free operation, and outputs High-Level Synthesis (HLS) code for FPGA implementation. We utilize INR editing as our benchmark, presenting results that demonstrate 1.8-4.8x and 1.5-3.6x speedup compared to CPU and GPU baselines respectively. Furthermore, we obtain 3.1-8.9x and 1.7-4.3x lower memory usage, and 1.7-11.3x and 5.5-32.8x lower energy-delay product. Our framework will be made open-source and available on GitHub.
Edge-MoE: Memory-Efficient Multi-Task Vision Transformer Architecture with Task-level Sparsity via Mixture-of-Experts
May 30, 2023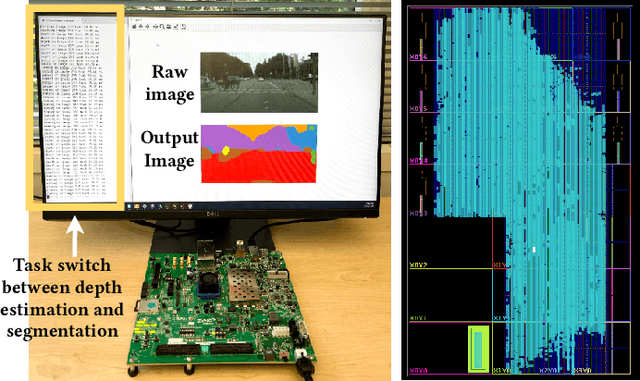


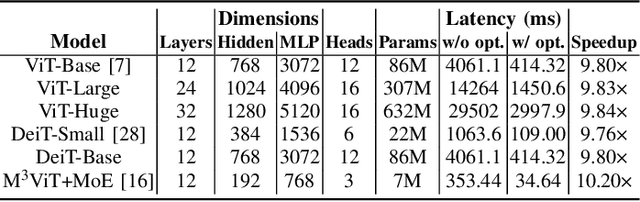
Computer vision researchers are embracing two promising paradigms: Vision Transformers (ViTs) and Multi-task Learning (MTL), which both show great performance but are computation-intensive, given the quadratic complexity of self-attention in ViT and the need to activate an entire large MTL model for one task. M$^3$ViT is the latest multi-task ViT model that introduces mixture-of-experts (MoE), where only a small portion of subnetworks ("experts") are sparsely and dynamically activated based on the current task. M$^3$ViT achieves better accuracy and over 80% computation reduction but leaves challenges for efficient deployment on FPGA. Our work, dubbed Edge-MoE, solves the challenges to introduce the first end-to-end FPGA accelerator for multi-task ViT with a collection of architectural innovations, including (1) a novel reordering mechanism for self-attention, which requires only constant bandwidth regardless of the target parallelism; (2) a fast single-pass softmax approximation; (3) an accurate and low-cost GELU approximation; (4) a unified and flexible computing unit that is shared by almost all computational layers to maximally reduce resource usage; and (5) uniquely for M$^3$ViT, a novel patch reordering method to eliminate memory access overhead. Edge-MoE achieves 2.24x and 4.90x better energy efficiency comparing with GPU and CPU, respectively. A real-time video demonstration is available online, along with our code written using High-Level Synthesis, which will be open-sourced.
M$^3$ViT: Mixture-of-Experts Vision Transformer for Efficient Multi-task Learning with Model-Accelerator Co-design
Oct 26, 2022



Multi-task learning (MTL) encapsulates multiple learned tasks in a single model and often lets those tasks learn better jointly. However, when deploying MTL onto those real-world systems that are often resource-constrained or latency-sensitive, two prominent challenges arise: (i) during training, simultaneously optimizing all tasks is often difficult due to gradient conflicts across tasks; (ii) at inference, current MTL regimes have to activate nearly the entire model even to just execute a single task. Yet most real systems demand only one or two tasks at each moment, and switch between tasks as needed: therefore such all tasks activated inference is also highly inefficient and non-scalable. In this paper, we present a model-accelerator co-design framework to enable efficient on-device MTL. Our framework, dubbed M$^3$ViT, customizes mixture-of-experts (MoE) layers into a vision transformer (ViT) backbone for MTL, and sparsely activates task-specific experts during training. Then at inference with any task of interest, the same design allows for activating only the task-corresponding sparse expert pathway, instead of the full model. Our new model design is further enhanced by hardware-level innovations, in particular, a novel computation reordering scheme tailored for memory-constrained MTL that achieves zero-overhead switching between tasks and can scale to any number of experts. When executing single-task inference, M$^{3}$ViT achieves higher accuracies than encoder-focused MTL methods, while significantly reducing 88% inference FLOPs. When implemented on a hardware platform of one Xilinx ZCU104 FPGA, our co-design framework reduces the memory requirement by 2.4 times, while achieving energy efficiency up to 9.23 times higher than a comparable FPGA baseline. Code is available at: https://github.com/VITA-Group/M3ViT.
FlowGNN: A Dataflow Architecture for Universal Graph Neural Network Inference via Multi-Queue Streaming
Apr 27, 2022
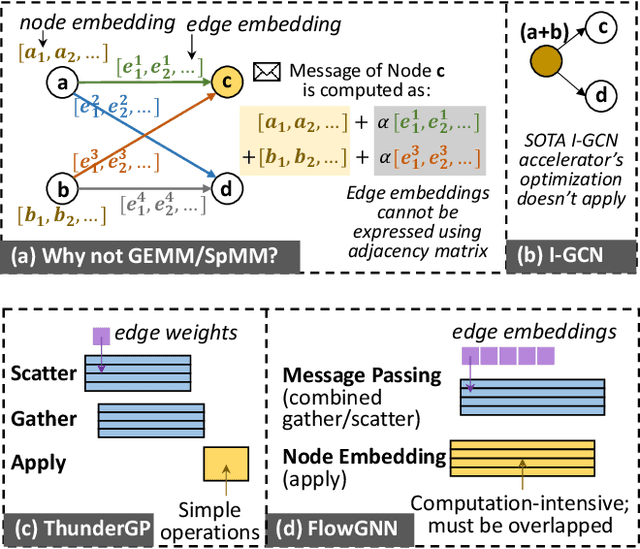
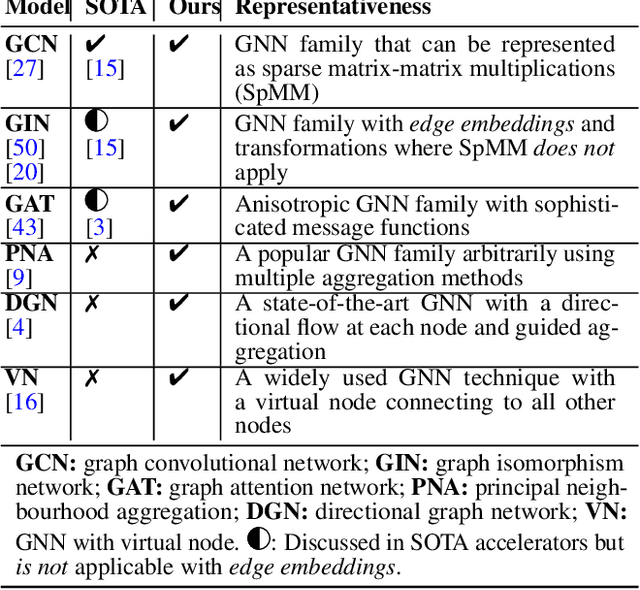
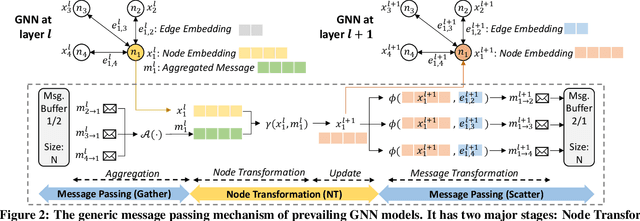
Graph neural networks (GNNs) have recently exploded in popularity thanks to their broad applicability to graph-related problems such as quantum chemistry, drug discovery, and high energy physics. However, meeting demand for novel GNN models and fast inference simultaneously is challenging because of the gap between developing efficient accelerators and the rapid creation of new GNN models. Prior art focuses on the acceleration of specific classes of GNNs, such as Graph Convolutional Network (GCN), but lacks the generality to support a wide range of existing or new GNN models. Meanwhile, most work rely on graph pre-processing to exploit data locality, making them unsuitable for real-time applications. To address these limitations, in this work, we propose a generic dataflow architecture for GNN acceleration, named FlowGNN, which can flexibly support the majority of message-passing GNNs. The contributions are three-fold. First, we propose a novel and scalable dataflow architecture, which flexibly supports a wide range of GNN models with message-passing mechanism. The architecture features a configurable dataflow optimized for simultaneous computation of node embedding, edge embedding, and message passing, which is generally applicable to all models. We also propose a rich library of model-specific components. Second, we deliver ultra-fast real-time GNN inference without any graph pre-processing, making it agnostic to dynamically changing graph structures. Third, we verify our architecture on the Xilinx Alveo U50 FPGA board and measure the on-board end-to-end performance. We achieve a speed-up of up to 51-254x against CPU (6226R) and 1.3-477x against GPU (A6000) (with batch sizes 1 through 1024); we also outperform the SOTA GNN accelerator I-GCN by 1.03x and 1.25x across two datasets. Our implementation code and on-board measurement are publicly available on GitHub.
GenGNN: A Generic FPGA Framework for Graph Neural Network Acceleration
Jan 20, 2022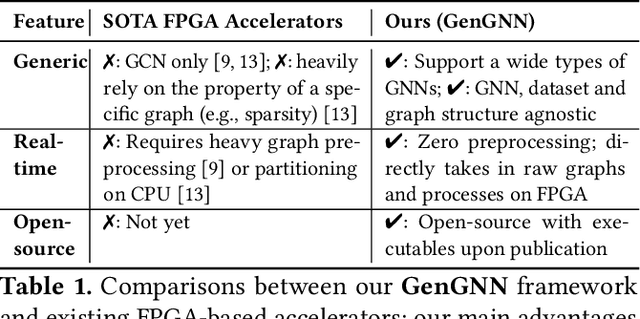
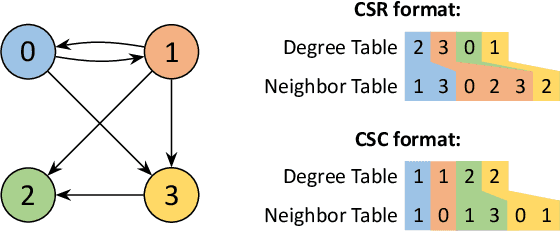
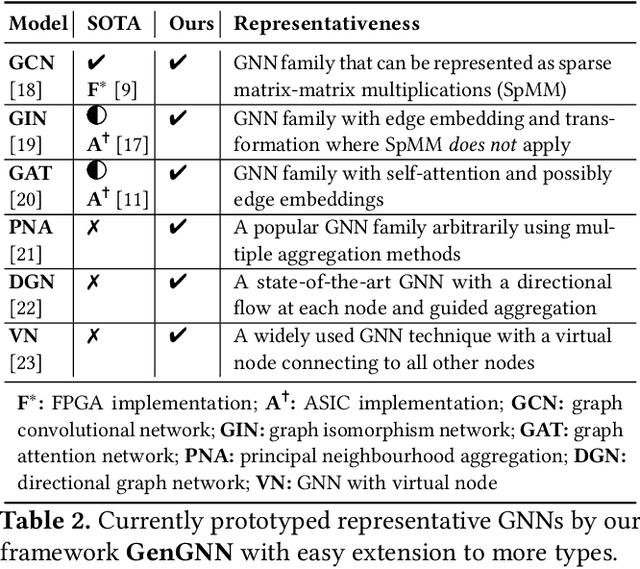
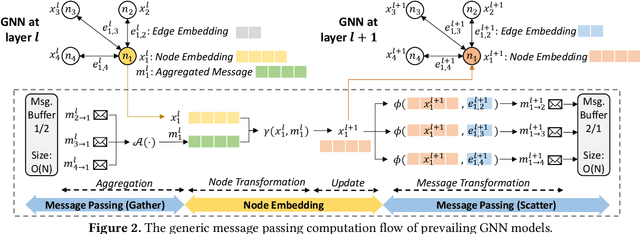
Graph neural networks (GNNs) have recently exploded in popularity thanks to their broad applicability to ubiquitous graph-related problems such as quantum chemistry, drug discovery, and high energy physics. However, meeting demand for novel GNN models and fast inference simultaneously is challenging because of the gap between the difficulty in developing efficient FPGA accelerators and the rapid pace of creation of new GNN models. Prior art focuses on the acceleration of specific classes of GNNs but lacks the generality to work across existing models or to extend to new and emerging GNN models. In this work, we propose a generic GNN acceleration framework using High-Level Synthesis (HLS), named GenGNN, with two-fold goals. First, we aim to deliver ultra-fast GNN inference without any graph pre-processing for real-time requirements. Second, we aim to support a diverse set of GNN models with the extensibility to flexibly adapt to new models. The framework features an optimized message-passing structure applicable to all models, combined with a rich library of model-specific components. We verify our implementation on-board on the Xilinx Alveo U50 FPGA and observe a speed-up of up to 25x against CPU (6226R) baseline and 13x against GPU (A6000) baseline. Our HLS code will be open-source on GitHub upon acceptance.