 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoment-Based Inference for Regression with Latent Dirichlet Covariates
May 29, 2026Topic models are often used as dimension-reduction tools before regression, with estimated document-level topic shares treated as observed covariates. This plug-in workflow creates two inferential difficulties: valid inference requires a regular first-stage-to-second-stage expansion that propagates topic-estimation uncertainty, and, at fixed document length, a document's topic mixture cannot be consistently recovered from its own words even when the population topic matrix is known. Corrected spectral moment methods for latent Dirichlet allocation (LDA) offer a starting point: when the total Dirichlet concentration is known, low-order word moments can be corrected to yield operators diagonal in the latent topic basis. We extend this to downstream regression. Under a finite LDA model with response residuals orthogonal to the low-order token moments used for identification, response-weighted word moments admit the same correction, and the resulting supervised operator identifies the regression coefficient $β$ directly, without estimating document-level topic shares. The main obstacle is that the correction depends on the unknown total concentration $α_0$. We show that, for $k\ge3$ topics and under a generic finite-probe condition, $α_0$ is identified by commutativity: at the true value a family of corrected word-moment operators commute, whereas away from it they generically do not. This yields a feasible estimator and lets uncertainty in $\hatα_0$ propagate into inference for $β$. The estimator is asymptotically linear as the number of documents grows with fixed document length, with sandwich standard errors from document-level moment contributions. Simulations show near-nominal coverage where plug-in topic-share regressions can undercover, and an application to top economics journals illustrates contrast inference for latent topic effects.
HorizonWeaver: Generalizable Multi-Level Semantic Editing for Driving Scenes
Apr 06, 2026Ensuring safety in autonomous driving requires scalable generation of realistic, controllable driving scenes beyond what real-world testing provides. Yet existing instruction guided image editors, trained on object-centric or artistic data, struggle with dense, safety-critical driving layouts. We propose HorizonWeaver, which tackles three fundamental challenges in driving scene editing: (1) multi-level granularity, requiring coherent object- and scene-level edits in dense environments; (2) rich high-level semantics, preserving diverse objects while following detailed instructions; and (3) ubiquitous domain shifts, handling changes in climate, layout, and traffic across unseen environments. The core of HorizonWeaver is a set of complementary contributions across data, model, and training: (1) Data: Large-scale dataset generation, where we build a paired real/synthetic dataset from Boreas, nuScenes, and Argoverse2 to improve generalization; (2) Model: Language-Guided Masks for fine-grained editing, where semantics-enriched masks and prompts enable precise, language-guided edits; and (3) Training: Content preservation and instruction alignment, where joint losses enforce scene consistency and instruction fidelity. Together, HorizonWeaver provides a scalable framework for photorealistic, instruction-driven editing of complex driving scenes, collecting 255K images across 13 editing categories and outperforming prior methods in L1, CLIP, and DINO metrics, achieving +46.4% user preference and improving BEV segmentation IoU by +33%. Project page: https://msoroco.github.io/horizonweaver/
HorizonForge: Driving Scene Editing with Any Trajectories and Any Vehicles
Feb 24, 2026Controllable driving scene generation is critical for realistic and scalable autonomous driving simulation, yet existing approaches struggle to jointly achieve photorealism and precise control. We introduce HorizonForge, a unified framework that reconstructs scenes as editable Gaussian Splats and Meshes, enabling fine-grained 3D manipulation and language-driven vehicle insertion. Edits are rendered through a noise-aware video diffusion process that enforces spatial and temporal consistency, producing diverse scene variations in a single feed-forward pass without per-trajectory optimization. To standardize evaluation, we further propose HorizonSuite, a comprehensive benchmark spanning ego- and agent-level editing tasks such as trajectory modifications and object manipulation. Extensive experiments show that Gaussian-Mesh representation delivers substantially higher fidelity than alternative 3D representations, and that temporal priors from video diffusion are essential for coherent synthesis. Combining these findings, HorizonForge establishes a simple yet powerful paradigm for photorealistic, controllable driving simulation, achieving an 83.4% user-preference gain and a 25.19% FID improvement over the second best state-of-the-art method. Project page: https://horizonforge.github.io/ .
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
LangDriveCTRL: Natural Language Controllable Driving Scene Editing with Multi-modal Agents
Dec 19, 2025

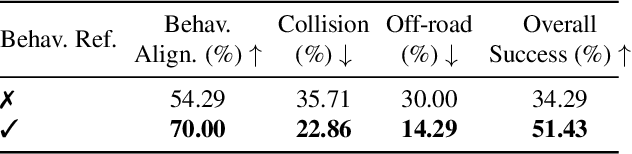

LangDriveCTRL is a natural-language-controllable framework for editing real-world driving videos to synthesize diverse traffic scenarios. It leverages explicit 3D scene decomposition to represent driving videos as a scene graph, containing static background and dynamic objects. To enable fine-grained editing and realism, it incorporates an agentic pipeline in which an Orchestrator transforms user instructions into execution graphs that coordinate specialized agents and tools. Specifically, an Object Grounding Agent establishes correspondence between free-form text descriptions and target object nodes in the scene graph; a Behavior Editing Agent generates multi-object trajectories from language instructions; and a Behavior Reviewer Agent iteratively reviews and refines the generated trajectories. The edited scene graph is rendered and then refined using a video diffusion tool to address artifacts introduced by object insertion and significant view changes. LangDriveCTRL supports both object node editing (removal, insertion and replacement) and multi-object behavior editing from a single natural-language instruction. Quantitatively, it achieves nearly $2\times$ higher instruction alignment than the previous SoTA, with superior structural preservation, photorealism, and traffic realism. Project page is available at: https://yunhe24.github.io/langdrivectrl/.
AutoScape: Geometry-Consistent Long-Horizon Scene Generation
Oct 23, 2025This paper proposes AutoScape, a long-horizon driving scene generation framework. At its core is a novel RGB-D diffusion model that iteratively generates sparse, geometrically consistent keyframes, serving as reliable anchors for the scene's appearance and geometry. To maintain long-range geometric consistency, the model 1) jointly handles image and depth in a shared latent space, 2) explicitly conditions on the existing scene geometry (i.e., rendered point clouds) from previously generated keyframes, and 3) steers the sampling process with a warp-consistent guidance. Given high-quality RGB-D keyframes, a video diffusion model then interpolates between them to produce dense and coherent video frames. AutoScape generates realistic and geometrically consistent driving videos of over 20 seconds, improving the long-horizon FID and FVD scores over the prior state-of-the-art by 48.6\% and 43.0\%, respectively.
Identification and Estimation of Simultaneous Equation Models Using Higher-Order Cumulant Restrictions
Jan 12, 2025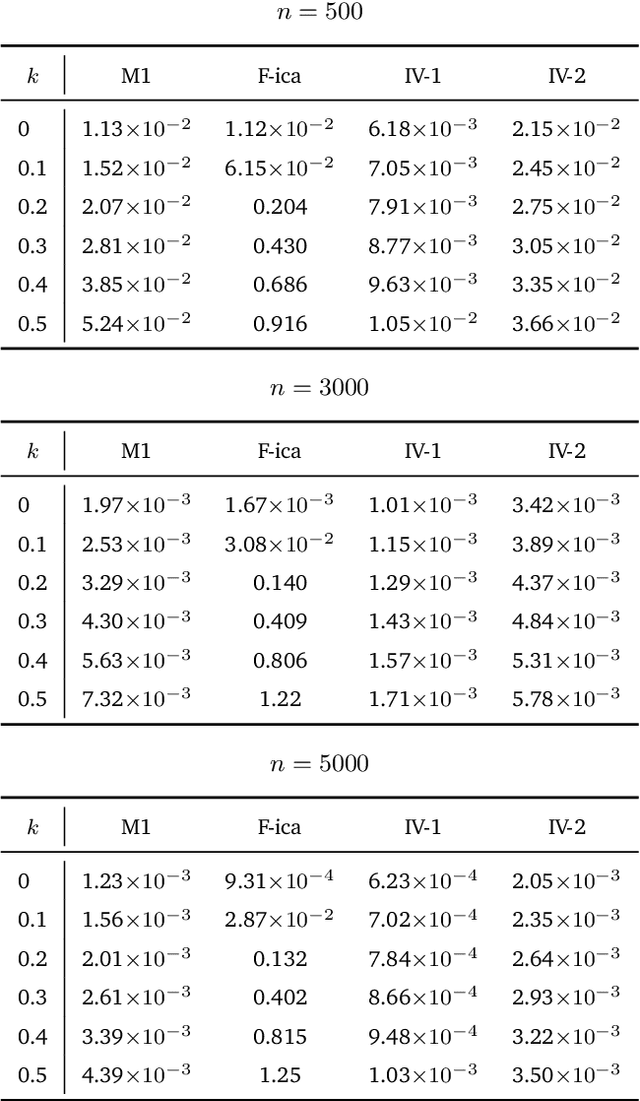

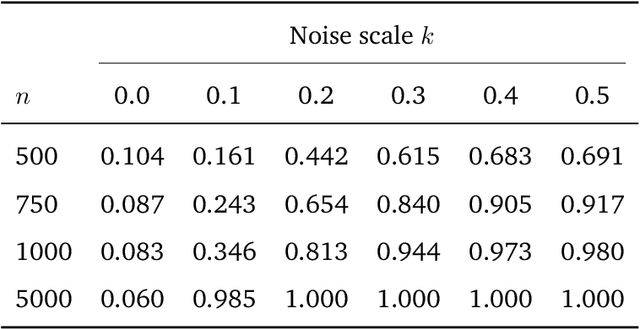
Identifying structural parameters in linear simultaneous equation models is a fundamental challenge in economics and related fields. Recent work leverages higher-order distributional moments, exploiting the fact that non-Gaussian data carry more structural information than the Gaussian framework. While many of these contributions still require zero-covariance assumptions for structural errors, this paper shows that such an assumption can be dispensed with. Specifically, we demonstrate that under any diagonal higher-cumulant condition, the structural parameter matrix can be identified by solving an eigenvector problem. This yields a direct identification argument and motivates a simple sample-analogue estimator that is both consistent and asymptotically normal. Moreover, when uncorrelatedness may still be plausible -- such as in vector autoregression models -- our framework offers a transparent way to test for it, all within the same higher-order orthogonality setting employed by earlier studies. Monte Carlo simulations confirm desirable finite-sample performance, and we further illustrate the method's practical value in two empirical applications.
Drive-1-to-3: Enriching Diffusion Priors for Novel View Synthesis of Real Vehicles
Dec 19, 2024The recent advent of large-scale 3D data, e.g. Objaverse, has led to impressive progress in training pose-conditioned diffusion models for novel view synthesis. However, due to the synthetic nature of such 3D data, their performance drops significantly when applied to real-world images. This paper consolidates a set of good practices to finetune large pretrained models for a real-world task -- harvesting vehicle assets for autonomous driving applications. To this end, we delve into the discrepancies between the synthetic data and real driving data, then develop several strategies to account for them properly. Specifically, we start with a virtual camera rotation of real images to ensure geometric alignment with synthetic data and consistency with the pose manifold defined by pretrained models. We also identify important design choices in object-centric data curation to account for varying object distances in real driving scenes -- learn across varying object scales with fixed camera focal length. Further, we perform occlusion-aware training in latent spaces to account for ubiquitous occlusions in real data, and handle large viewpoint changes by leveraging a symmetric prior. Our insights lead to effective finetuning that results in a $68.8\%$ reduction in FID for novel view synthesis over prior arts.
CRAG -- Comprehensive RAG Benchmark
Jun 07, 2024



Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution to alleviate Large Language Model (LLM)'s deficiency in lack of knowledge. Existing RAG datasets, however, do not adequately represent the diverse and dynamic nature of real-world Question Answering (QA) tasks. To bridge this gap, we introduce the Comprehensive RAG Benchmark (CRAG), a factual question answering benchmark of 4,409 question-answer pairs and mock APIs to simulate web and Knowledge Graph (KG) search. CRAG is designed to encapsulate a diverse array of questions across five domains and eight question categories, reflecting varied entity popularity from popular to long-tail, and temporal dynamisms ranging from years to seconds. Our evaluation on this benchmark highlights the gap to fully trustworthy QA. Whereas most advanced LLMs achieve <=34% accuracy on CRAG, adding RAG in a straightforward manner improves the accuracy only to 44%. State-of-the-art industry RAG solutions only answer 63% questions without any hallucination. CRAG also reveals much lower accuracy in answering questions regarding facts with higher dynamism, lower popularity, or higher complexity, suggesting future research directions. The CRAG benchmark laid the groundwork for a KDD Cup 2024 challenge, attracting thousands of participants and submissions within the first 50 days of the competition. We commit to maintaining CRAG to serve research communities in advancing RAG solutions and general QA solutions.
LidaRF: Delving into Lidar for Neural Radiance Field on Street Scenes
May 04, 2024Photorealistic simulation plays a crucial role in applications such as autonomous driving, where advances in neural radiance fields (NeRFs) may allow better scalability through the automatic creation of digital 3D assets. However, reconstruction quality suffers on street scenes due to largely collinear camera motions and sparser samplings at higher speeds. On the other hand, the application often demands rendering from camera views that deviate from the inputs to accurately simulate behaviors like lane changes. In this paper, we propose several insights that allow a better utilization of Lidar data to improve NeRF quality on street scenes. First, our framework learns a geometric scene representation from Lidar, which is fused with the implicit grid-based representation for radiance decoding, thereby supplying stronger geometric information offered by explicit point cloud. Second, we put forth a robust occlusion-aware depth supervision scheme, which allows utilizing densified Lidar points by accumulation. Third, we generate augmented training views from Lidar points for further improvement. Our insights translate to largely improved novel view synthesis under real driving scenes.