 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Are Large Language Models a Good Replacement of Taxonomies?
Jun 17, 2024



Large language models (LLMs) demonstrate an impressive ability to internalize knowledge and answer natural language questions. Although previous studies validate that LLMs perform well on general knowledge while presenting poor performance on long-tail nuanced knowledge, the community is still doubtful about whether the traditional knowledge graphs should be replaced by LLMs. In this paper, we ask if the schema of knowledge graph (i.e., taxonomy) is made obsolete by LLMs. Intuitively, LLMs should perform well on common taxonomies and at taxonomy levels that are common to people. Unfortunately, there lacks a comprehensive benchmark that evaluates the LLMs over a wide range of taxonomies from common to specialized domains and at levels from root to leaf so that we can draw a confident conclusion. To narrow the research gap, we constructed a novel taxonomy hierarchical structure discovery benchmark named TaxoGlimpse to evaluate the performance of LLMs over taxonomies. TaxoGlimpse covers ten representative taxonomies from common to specialized domains with in-depth experiments of different levels of entities in this taxonomy from root to leaf. Our comprehensive experiments of eighteen state-of-the-art LLMs under three prompting settings validate that LLMs can still not well capture the knowledge of specialized taxonomies and leaf-level entities.
CRAG -- Comprehensive RAG Benchmark
Jun 07, 2024



Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution to alleviate Large Language Model (LLM)'s deficiency in lack of knowledge. Existing RAG datasets, however, do not adequately represent the diverse and dynamic nature of real-world Question Answering (QA) tasks. To bridge this gap, we introduce the Comprehensive RAG Benchmark (CRAG), a factual question answering benchmark of 4,409 question-answer pairs and mock APIs to simulate web and Knowledge Graph (KG) search. CRAG is designed to encapsulate a diverse array of questions across five domains and eight question categories, reflecting varied entity popularity from popular to long-tail, and temporal dynamisms ranging from years to seconds. Our evaluation on this benchmark highlights the gap to fully trustworthy QA. Whereas most advanced LLMs achieve <=34% accuracy on CRAG, adding RAG in a straightforward manner improves the accuracy only to 44%. State-of-the-art industry RAG solutions only answer 63% questions without any hallucination. CRAG also reveals much lower accuracy in answering questions regarding facts with higher dynamism, lower popularity, or higher complexity, suggesting future research directions. The CRAG benchmark laid the groundwork for a KDD Cup 2024 challenge, attracting thousands of participants and submissions within the first 50 days of the competition. We commit to maintaining CRAG to serve research communities in advancing RAG solutions and general QA solutions.
KGLink: A column type annotation method that combines knowledge graph and pre-trained language model
Jun 01, 2024The semantic annotation of tabular data plays a crucial role in various downstream tasks. Previous research has proposed knowledge graph (KG)-based and deep learning-based methods, each with its inherent limitations. KG-based methods encounter difficulties annotating columns when there is no match for column cells in the KG. Moreover, KG-based methods can provide multiple predictions for one column, making it challenging to determine the semantic type with the most suitable granularity for the dataset. This type granularity issue limits their scalability. On the other hand, deep learning-based methods face challenges related to the valuable context missing issue. This occurs when the information within the table is insufficient for determining the correct column type. This paper presents KGLink, a method that combines WikiData KG information with a pre-trained deep learning language model for table column annotation, effectively addressing both type granularity and valuable context missing issues. Through comprehensive experiments on widely used tabular datasets encompassing numeric and string columns with varying type granularity, we showcase the effectiveness and efficiency of KGLink. By leveraging the strengths of KGLink, we successfully surmount challenges related to type granularity and valuable context issues, establishing it as a robust solution for the semantic annotation of tabular data.
Multi-level Multiple Instance Learning with Transformer for Whole Slide Image Classification
Jun 08, 2023



Whole slide image (WSI) refers to a type of high-resolution scanned tissue image, which is extensively employed in computer-assisted diagnosis (CAD). The extremely high resolution and limited availability of region-level annotations make it challenging to employ deep learning methods for WSI-based digital diagnosis. Multiple instance learning (MIL) is a powerful tool to address the weak annotation problem, while Transformer has shown great success in the field of visual tasks. The combination of both should provide new insights for deep learning based image diagnosis. However, due to the limitations of single-level MIL and the attention mechanism's constraints on sequence length, directly applying Transformer to WSI-based MIL tasks is not practical. To tackle this issue, we propose a Multi-level MIL with Transformer (MMIL-Transformer) approach. By introducing a hierarchical structure to MIL, this approach enables efficient handling of MIL tasks that involve a large number of instances. To validate its effectiveness, we conducted a set of experiments on WSIs classification task, where MMIL-Transformer demonstrate superior performance compared to existing state-of-the-art methods. Our proposed approach achieves test AUC 94.74% and test accuracy 93.41% on CAMELYON16 dataset, test AUC 99.04% and test accuracy 94.37% on TCGA-NSCLC dataset, respectively. All code and pre-trained models are available at: https://github.com/hustvl/MMIL-Transformer
WeakTr: Exploring Plain Vision Transformer for Weakly-supervised Semantic Segmentation
Apr 27, 2023This paper explores the properties of the plain Vision Transformer (ViT) for Weakly-supervised Semantic Segmentation (WSSS). The class activation map (CAM) is of critical importance for understanding a classification network and launching WSSS. We observe that different attention heads of ViT focus on different image areas. Thus a novel weight-based method is proposed to end-to-end estimate the importance of attention heads, while the self-attention maps are adaptively fused for high-quality CAM results that tend to have more complete objects. Besides, we propose a ViT-based gradient clipping decoder for online retraining with the CAM results to complete the WSSS task. We name this plain Transformer-based Weakly-supervised learning framework WeakTr. It achieves the state-of-the-art WSSS performance on standard benchmarks, i.e., 78.4% mIoU on the val set of PASCAL VOC 2012 and 50.3% mIoU on the val set of COCO 2014. Code is available at https://github.com/hustvl/WeakTr.
Attacking and Defending Machine Learning Applications of Public Cloud
Jul 27, 2020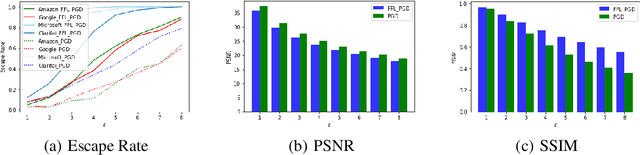


Adversarial attack breaks the boundaries of traditional security defense. For adversarial attack and the characteristics of cloud services, we propose Security Development Lifecycle for Machine Learning applications, e.g., SDL for ML. The SDL for ML helps developers build more secure software by reducing the number and severity of vulnerabilities in ML-as-a-service, while reducing development cost.
Advbox: a toolbox to generate adversarial examples that fool neural networks
Feb 21, 2020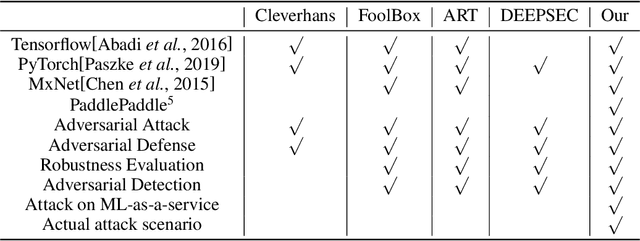



In recent years, neural networks have been extensively deployed for computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance. Recent studies have shown that they are all vulnerable to the attack of adversarial examples. Small and often imperceptible perturbations to the input images are sufficient to fool the most powerful neural networks. \emph{Advbox} is a toolbox to generate adversarial examples that fool neural networks in PaddlePaddle, PyTorch, Caffe2, MxNet, Keras, TensorFlow and it can benchmark the robustness of machine learning models. Compared to previous work, our platform supports black box attacks on Machine-Learning-as-a-service, as well as more attack scenarios, such as Face Recognition Attack, Stealth T-shirt, and DeepFake Face Detect. The code is licensed under the Apache 2.0 and is openly available at https://github.com/advboxes/AdvBox. Advbox now supports Python 3.
Subjective Knowledge Acquisition and Enrichment Powered By Crowdsourcing
May 16, 2017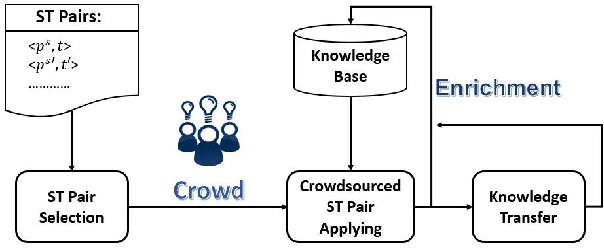
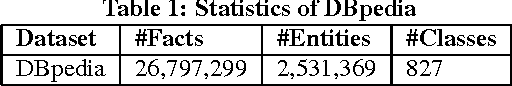
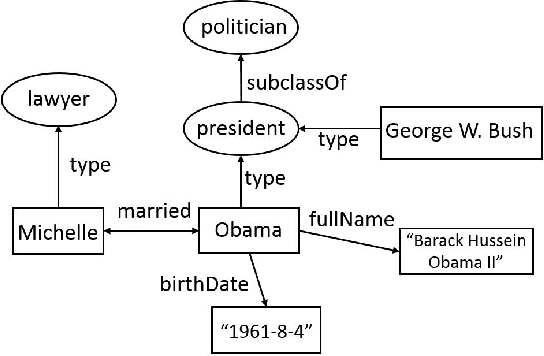

Knowledge bases (KBs) have attracted increasing attention due to its great success in various areas, such as Web and mobile search.Existing KBs are restricted to objective factual knowledge, such as city population or fruit shape, whereas,subjective knowledge, such as big city, which is commonly mentioned in Web and mobile queries, has been neglected. Subjective knowledge differs from objective knowledge in that it has no documented or observed ground truth. Instead, the truth relies on people's dominant opinion. Thus, we can use the crowdsourcing technique to get opinion from the crowd. In our work, we propose a system, called crowdsourced subjective knowledge acquisition (CoSKA),for subjective knowledge acquisition powered by crowdsourcing and existing KBs. The acquired knowledge can be used to enrich existing KBs in the subjective dimension which bridges the gap between existing objective knowledge and subjective queries.The main challenge of CoSKA is the conflict between large scale knowledge facts and limited crowdsourcing resource. To address this challenge, in this work, we define knowledge inference rules and then select the seed knowledge judiciously for crowdsourcing to maximize the inference power under the resource constraint. Our experimental results on real knowledge base and crowdsourcing platform verify the effectiveness of CoSKA system.