 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKERAG: Knowledge-Enhanced Retrieval-Augmented Generation for Advanced Question Answering
Sep 05, 2025Retrieval-Augmented Generation (RAG) mitigates hallucination in Large Language Models (LLMs) by incorporating external data, with Knowledge Graphs (KGs) offering crucial information for question answering. Traditional Knowledge Graph Question Answering (KGQA) methods rely on semantic parsing, which typically retrieves knowledge strictly necessary for answer generation, thus often suffer from low coverage due to rigid schema requirements and semantic ambiguity. We present KERAG, a novel KG-based RAG pipeline that enhances QA coverage by retrieving a broader subgraph likely to contain relevant information. Our retrieval-filtering-summarization approach, combined with fine-tuned LLMs for Chain-of-Thought reasoning on knowledge sub-graphs, reduces noises and improves QA for both simple and complex questions. Experiments demonstrate that KERAG surpasses state-of-the-art solutions by about 7% in quality and exceeds GPT-4o (Tool) by 10-21%.
ConfQA: Answer Only If You Are Confident
Jun 08, 2025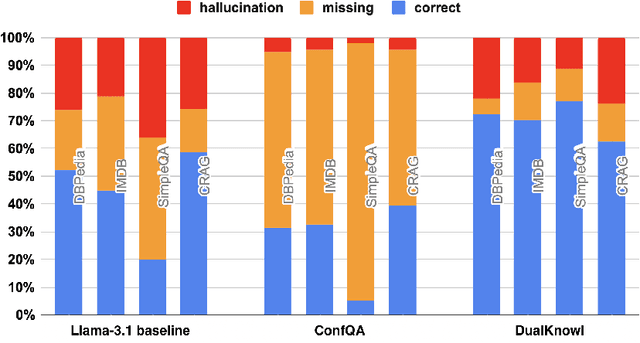
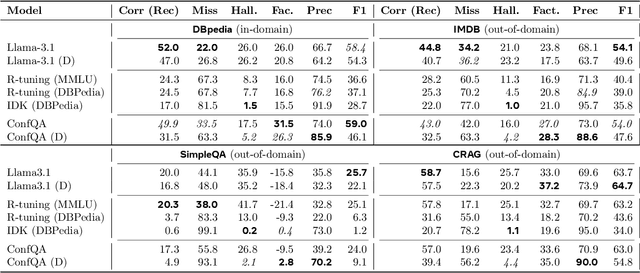
Can we teach Large Language Models (LLMs) to refrain from hallucinating factual statements? In this paper we present a fine-tuning strategy that we call ConfQA, which can reduce hallucination rate from 20-40% to under 5% across multiple factuality benchmarks. The core idea is simple: when the LLM answers a question correctly, it is trained to continue with the answer; otherwise, it is trained to admit "I am unsure". But there are two key factors that make the training highly effective. First, we introduce a dampening prompt "answer only if you are confident" to explicitly guide the behavior, without which hallucination remains high as 15%-25%. Second, we leverage simple factual statements, specifically attribute values from knowledge graphs, to help LLMs calibrate the confidence, resulting in robust generalization across domains and question types. Building on this insight, we propose the Dual Neural Knowledge framework, which seamlessly select between internally parameterized neural knowledge and externally recorded symbolic knowledge based on ConfQA's confidence. The framework enables potential accuracy gains to beyond 95%, while reducing unnecessary external retrievals by over 30%.
Are Large Language Models a Good Replacement of Taxonomies?
Jun 17, 2024Large language models (LLMs) demonstrate an impressive ability to internalize knowledge and answer natural language questions. Although previous studies validate that LLMs perform well on general knowledge while presenting poor performance on long-tail nuanced knowledge, the community is still doubtful about whether the traditional knowledge graphs should be replaced by LLMs. In this paper, we ask if the schema of knowledge graph (i.e., taxonomy) is made obsolete by LLMs. Intuitively, LLMs should perform well on common taxonomies and at taxonomy levels that are common to people. Unfortunately, there lacks a comprehensive benchmark that evaluates the LLMs over a wide range of taxonomies from common to specialized domains and at levels from root to leaf so that we can draw a confident conclusion. To narrow the research gap, we constructed a novel taxonomy hierarchical structure discovery benchmark named TaxoGlimpse to evaluate the performance of LLMs over taxonomies. TaxoGlimpse covers ten representative taxonomies from common to specialized domains with in-depth experiments of different levels of entities in this taxonomy from root to leaf. Our comprehensive experiments of eighteen state-of-the-art LLMs under three prompting settings validate that LLMs can still not well capture the knowledge of specialized taxonomies and leaf-level entities.
CRAG -- Comprehensive RAG Benchmark
Jun 07, 2024



Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution to alleviate Large Language Model (LLM)'s deficiency in lack of knowledge. Existing RAG datasets, however, do not adequately represent the diverse and dynamic nature of real-world Question Answering (QA) tasks. To bridge this gap, we introduce the Comprehensive RAG Benchmark (CRAG), a factual question answering benchmark of 4,409 question-answer pairs and mock APIs to simulate web and Knowledge Graph (KG) search. CRAG is designed to encapsulate a diverse array of questions across five domains and eight question categories, reflecting varied entity popularity from popular to long-tail, and temporal dynamisms ranging from years to seconds. Our evaluation on this benchmark highlights the gap to fully trustworthy QA. Whereas most advanced LLMs achieve <=34% accuracy on CRAG, adding RAG in a straightforward manner improves the accuracy only to 44%. State-of-the-art industry RAG solutions only answer 63% questions without any hallucination. CRAG also reveals much lower accuracy in answering questions regarding facts with higher dynamism, lower popularity, or higher complexity, suggesting future research directions. The CRAG benchmark laid the groundwork for a KDD Cup 2024 challenge, attracting thousands of participants and submissions within the first 50 days of the competition. We commit to maintaining CRAG to serve research communities in advancing RAG solutions and general QA solutions.
SnapNTell: Enhancing Entity-Centric Visual Question Answering with Retrieval Augmented Multimodal LLM
Mar 07, 2024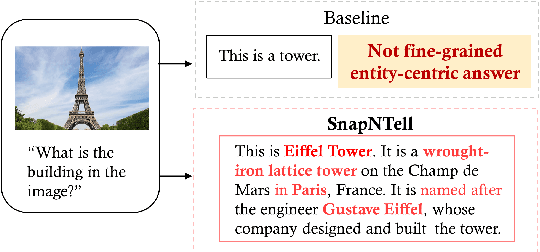

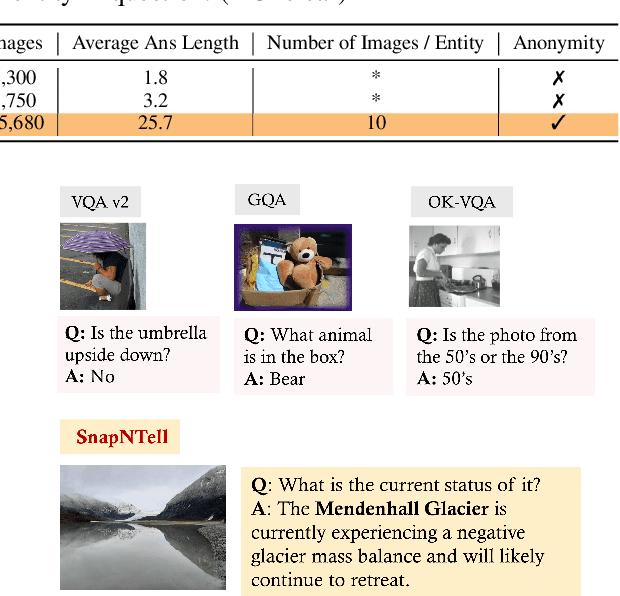
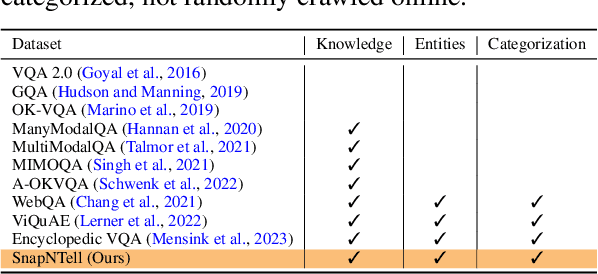
Vision-extended LLMs have made significant strides in Visual Question Answering (VQA). Despite these advancements, VLLMs still encounter substantial difficulties in handling queries involving long-tail entities, with a tendency to produce erroneous or hallucinated responses. In this work, we introduce a novel evaluative benchmark named \textbf{SnapNTell}, specifically tailored for entity-centric VQA. This task aims to test the models' capabilities in identifying entities and providing detailed, entity-specific knowledge. We have developed the \textbf{SnapNTell Dataset}, distinct from traditional VQA datasets: (1) It encompasses a wide range of categorized entities, each represented by images and explicitly named in the answers; (2) It features QA pairs that require extensive knowledge for accurate responses. The dataset is organized into 22 major categories, containing 7,568 unique entities in total. For each entity, we curated 10 illustrative images and crafted 10 knowledge-intensive QA pairs. To address this novel task, we devised a scalable, efficient, and transparent retrieval-augmented multimodal LLM. Our approach markedly outperforms existing methods on the SnapNTell dataset, achieving a 66.5\% improvement in the BELURT score. We will soon make the dataset and the source code publicly accessible.
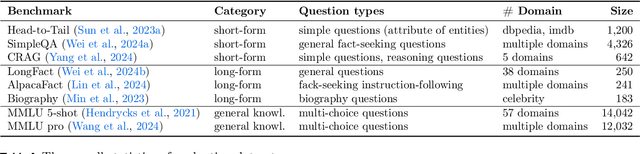
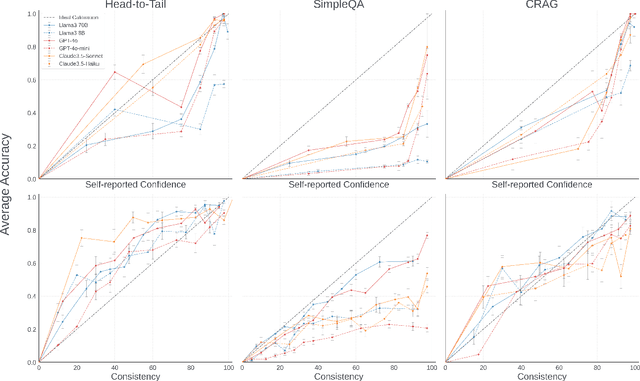
Head-to-Tail: How Knowledgeable are Large Language Models ? A.K.A. Will LLMs Replace Knowledge Graphs?
Aug 20, 2023



Since the recent prosperity of Large Language Models (LLMs), there have been interleaved discussions regarding how to reduce hallucinations from LLM responses, how to increase the factuality of LLMs, and whether Knowledge Graphs (KGs), which store the world knowledge in a symbolic form, will be replaced with LLMs. In this paper, we try to answer these questions from a new angle: How knowledgeable are LLMs? To answer this question, we constructed Head-to-Tail, a benchmark that consists of 18K question-answer (QA) pairs regarding head, torso, and tail facts in terms of popularity. We designed an automated evaluation method and a set of metrics that closely approximate the knowledge an LLM confidently internalizes. Through a comprehensive evaluation of 14 publicly available LLMs, we show that existing LLMs are still far from being perfect in terms of their grasp of factual knowledge, especially for facts of torso-to-tail entities.
AutoKnow: Self-Driving Knowledge Collection for Products of Thousands of Types
Jun 24, 2020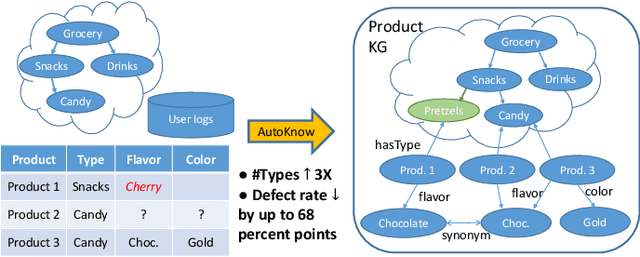

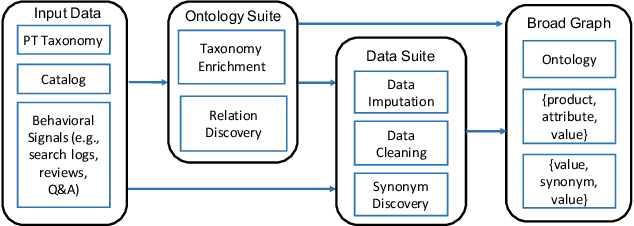
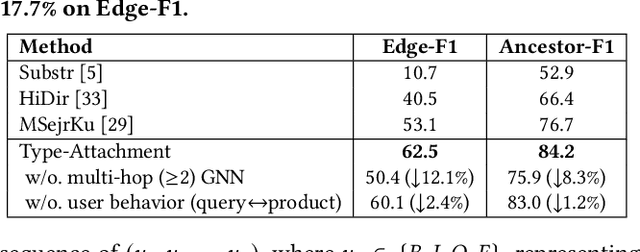
Can one build a knowledge graph (KG) for all products in the world? Knowledge graphs have firmly established themselves as valuable sources of information for search and question answering, and it is natural to wonder if a KG can contain information about products offered at online retail sites. There have been several successful examples of generic KGs, but organizing information about products poses many additional challenges, including sparsity and noise of structured data for products, complexity of the domain with millions of product types and thousands of attributes, heterogeneity across large number of categories, as well as large and constantly growing number of products. We describe AutoKnow, our automatic (self-driving) system that addresses these challenges. The system includes a suite of novel techniques for taxonomy construction, product property identification, knowledge extraction, anomaly detection, and synonym discovery. AutoKnow is (a) automatic, requiring little human intervention, (b) multi-scalable, scalable in multiple dimensions (many domains, many products, and many attributes), and (c) integrative, exploiting rich customer behavior logs. AutoKnow has been operational in collecting product knowledge for over 11K product types.
Automatic Validation of Textual Attribute Values in E-commerce Catalog by Learning with Limited Labeled Data
Jun 23, 2020

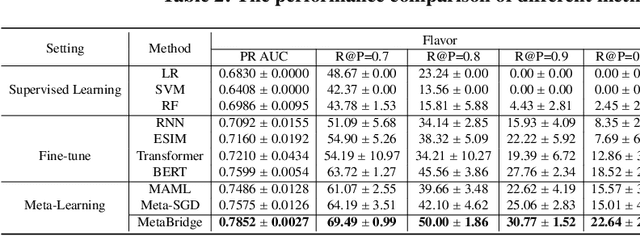

Product catalogs are valuable resources for eCommerce website. In the catalog, a product is associated with multiple attributes whose values are short texts, such as product name, brand, functionality and flavor. Usually individual retailers self-report these key values, and thus the catalog information unavoidably contains noisy facts. Although existing deep neural network models have shown success in conducting cross-checking between two pieces of texts, their success has to be dependent upon a large set of quality labeled data, which are hard to obtain in this validation task: products span a variety of categories. To address the aforementioned challenges, we propose a novel meta-learning latent variable approach, called MetaBridge, which can learn transferable knowledge from a subset of categories with limited labeled data and capture the uncertainty of never-seen categories with unlabeled data. More specifically, we make the following contributions. (1) We formalize the problem of validating the textual attribute values of products from a variety of categories as a natural language inference task in the few-shot learning setting, and propose a meta-learning latent variable model to jointly process the signals obtained from product profiles and textual attribute values. (2) We propose to integrate meta learning and latent variable in a unified model to effectively capture the uncertainty of various categories. (3) We propose a novel objective function based on latent variable model in the few-shot learning setting, which ensures distribution consistency between unlabeled and labeled data and prevents overfitting by sampling from the learned distribution. Extensive experiments on real eCommerce datasets from hundreds of categories demonstrate the effectiveness of MetaBridge on textual attribute validation and its outstanding performance compared with state-of-the-art approaches.