 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnapNTell: Enhancing Entity-Centric Visual Question Answering with Retrieval Augmented Multimodal LLM
Mar 07, 2024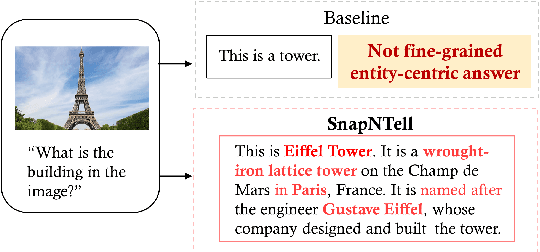

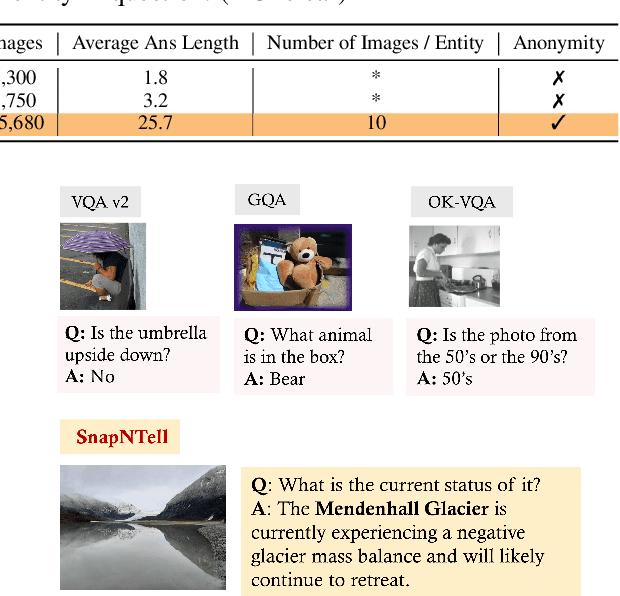
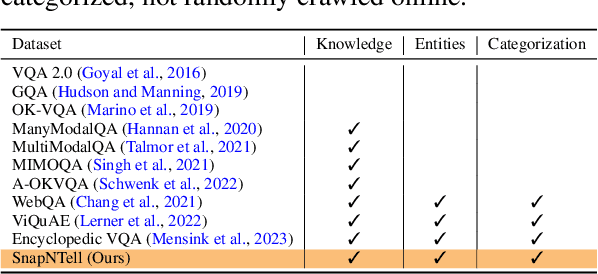
Vision-extended LLMs have made significant strides in Visual Question Answering (VQA). Despite these advancements, VLLMs still encounter substantial difficulties in handling queries involving long-tail entities, with a tendency to produce erroneous or hallucinated responses. In this work, we introduce a novel evaluative benchmark named \textbf{SnapNTell}, specifically tailored for entity-centric VQA. This task aims to test the models' capabilities in identifying entities and providing detailed, entity-specific knowledge. We have developed the \textbf{SnapNTell Dataset}, distinct from traditional VQA datasets: (1) It encompasses a wide range of categorized entities, each represented by images and explicitly named in the answers; (2) It features QA pairs that require extensive knowledge for accurate responses. The dataset is organized into 22 major categories, containing 7,568 unique entities in total. For each entity, we curated 10 illustrative images and crafted 10 knowledge-intensive QA pairs. To address this novel task, we devised a scalable, efficient, and transparent retrieval-augmented multimodal LLM. Our approach markedly outperforms existing methods on the SnapNTell dataset, achieving a 66.5\% improvement in the BELURT score. We will soon make the dataset and the source code publicly accessible.
Large Language Models as Zero-shot Dialogue State Tracker through Function Calling
Feb 16, 2024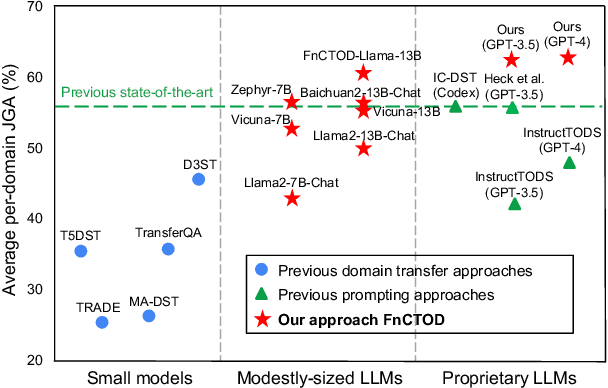

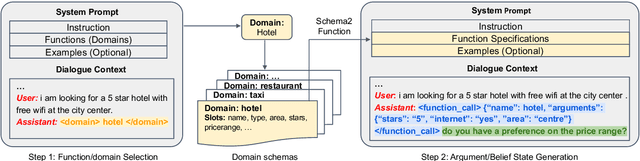
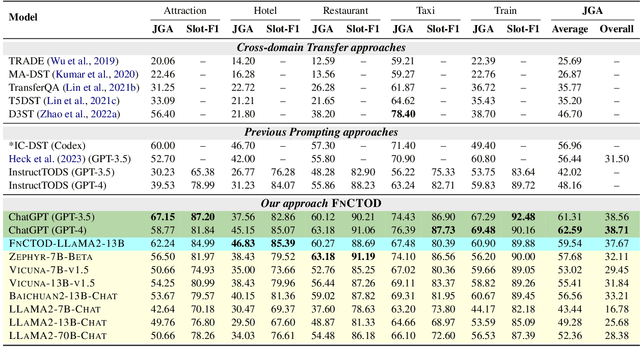
Large language models (LLMs) are increasingly prevalent in conversational systems due to their advanced understanding and generative capabilities in general contexts. However, their effectiveness in task-oriented dialogues (TOD), which requires not only response generation but also effective dialogue state tracking (DST) within specific tasks and domains, remains less satisfying. In this work, we propose a novel approach FnCTOD for solving DST with LLMs through function calling. This method improves zero-shot DST, allowing adaptation to diverse domains without extensive data collection or model tuning. Our experimental results demonstrate that our approach achieves exceptional performance with both modestly sized open-source and also proprietary LLMs: with in-context prompting it enables various 7B or 13B parameter models to surpass the previous state-of-the-art (SOTA) achieved by ChatGPT, and improves ChatGPT's performance beating the SOTA by 5.6% Avg. JGA. Individual model results for GPT-3.5 and GPT-4 are boosted by 4.8% and 14%, respectively. We also show that by fine-tuning on a small collection of diverse task-oriented dialogues, we can equip modestly sized models, specifically a 13B parameter LLaMA2-Chat model, with function-calling capabilities and DST performance comparable to ChatGPT while maintaining their chat capabilities. We plan to open-source experimental code and model.
Teaching Models new APIs: Domain-Agnostic Simulators for Task Oriented Dialogue
Oct 13, 2021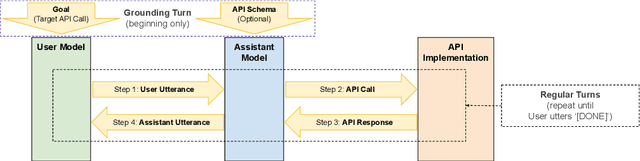
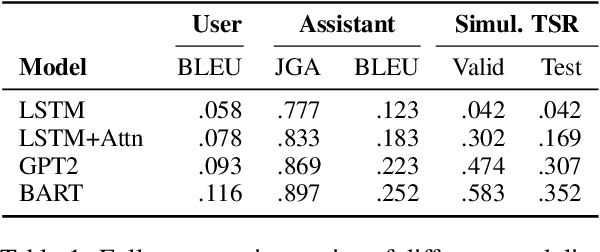
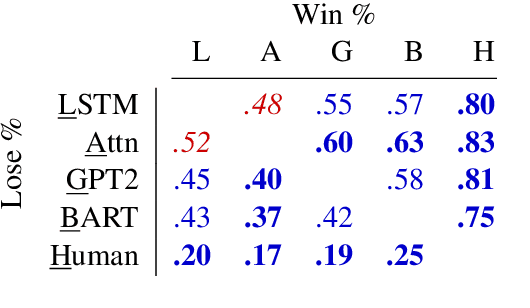
We demonstrate that large language models are able to simulate Task Oriented Dialogues in novel domains, provided only with an API implementation and a list of goals. We show these simulations can formulate online, automatic metrics that correlate well with human evaluations. Furthermore, by checking for whether the User's goals are met, we can use simulation to repeatedly generate training data and improve the quality of simulations themselves. With no human intervention or domain-specific training data, our simulations bootstrap end-to-end models which achieve a 37\% error reduction in previously unseen domains. By including as few as 32 domain-specific conversations, bootstrapped models can match the performance of a fully-supervised model with $10\times$ more data. To our knowledge, this is the first time simulations have been shown to be effective at bootstrapping models without explicitly requiring any domain-specific training data, rule-engineering, or humans-in-the-loop.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020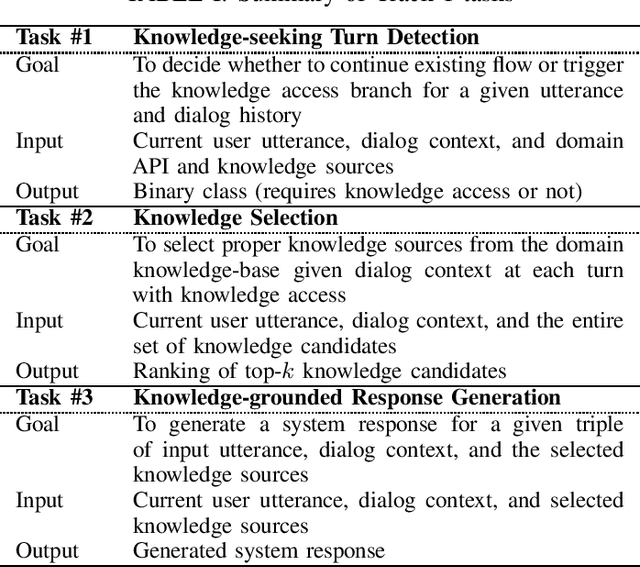
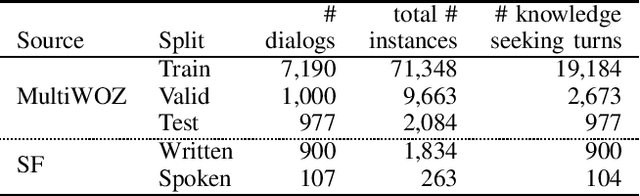

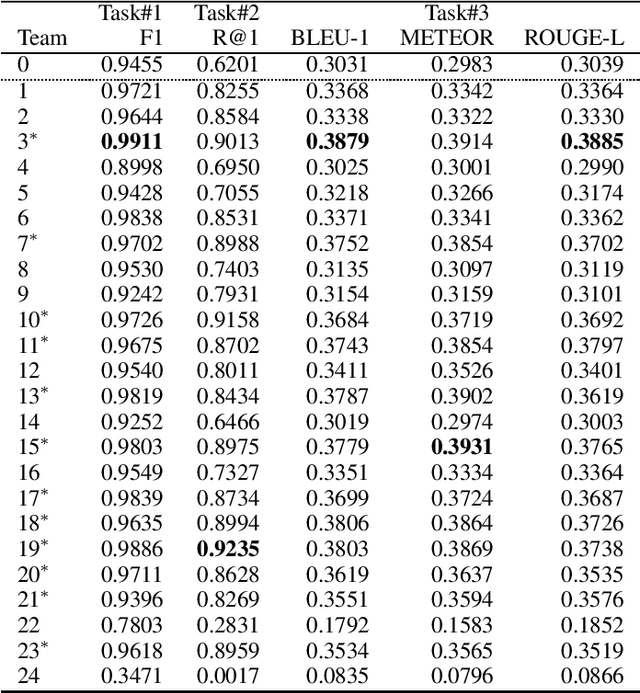
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Situated and Interactive Multimodal Conversations
Jun 02, 2020
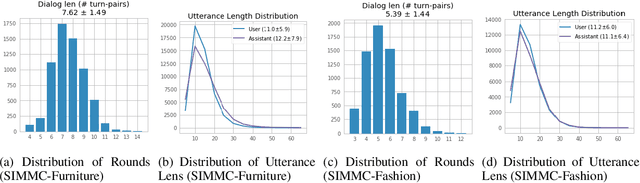
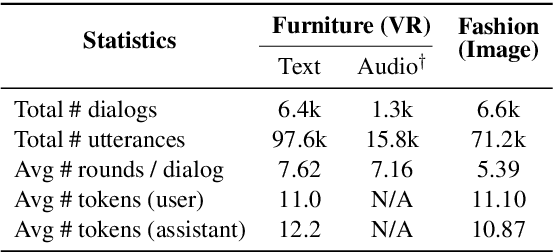
Next generation virtual assistants are envisioned to handle multimodal inputs (e.g., vision, memories of previous interactions, etc., in addition to the user's utterances), and perform multimodal actions (e.g., displaying a route in addition to generating the system's utterance). We introduce Situated Interactive MultiModal Conversations (SIMMC) as a new direction aimed at training agents that take multimodal actions grounded in a co-evolving multimodal input context in addition to the dialog history. We provide two SIMMC datasets totalling ~13K human-human dialogs (~169K utterances) using a multimodal Wizard-of-Oz (WoZ) setup, on two shopping domains: (a) furniture (grounded in a shared virtual environment) and, (b) fashion (grounded in an evolving set of images). We also provide logs of the items appearing in each scene, and contextual NLU and coreference annotations, using a novel and unified framework of SIMMC conversational acts for both user and assistant utterances. Finally, we present several tasks within SIMMC as objective evaluation protocols, such as Structural API Prediction and Response Generation. We benchmark a collection of existing models on these SIMMC tasks as strong baselines, and demonstrate rich multimodal conversational interactions. Our data, annotations, code, and models will be made publicly available.
SIMMC: Situated Interactive Multi-Modal Conversational Data Collection And Evaluation Platform
Nov 07, 2019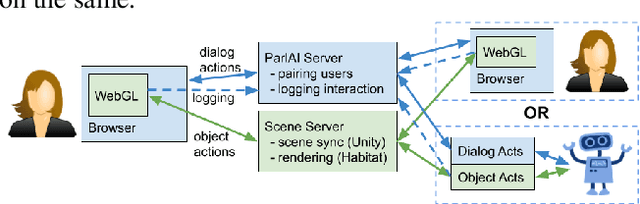
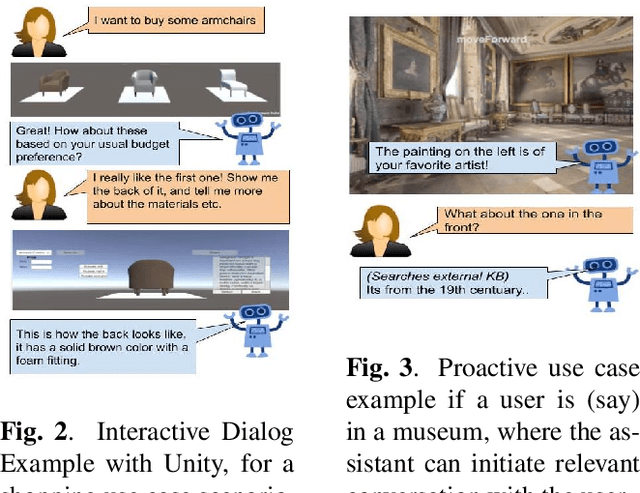
As digital virtual assistants become ubiquitous, it becomes increasingly important to understand the situated behaviour of users as they interact with these assistants. To this end, we introduce SIMMC, an extension to ParlAI for multi-modal conversational data collection and system evaluation. SIMMC simulates an immersive setup, where crowd workers are able to interact with environments constructed in AI Habitat or Unity while engaging in a conversation. The assistant in SIMMC can be a crowd worker or Artificial Intelligent (AI) agent. This enables both (i) a multi-player / Wizard of Oz setting for data collection, or (ii) a single player mode for model / system evaluation. We plan to open-source a situated conversational data-set collected on this platform for the Conversational AI research community.
On the Linear Belief Compression of POMDPs: A re-examination of current methods
Aug 05, 2015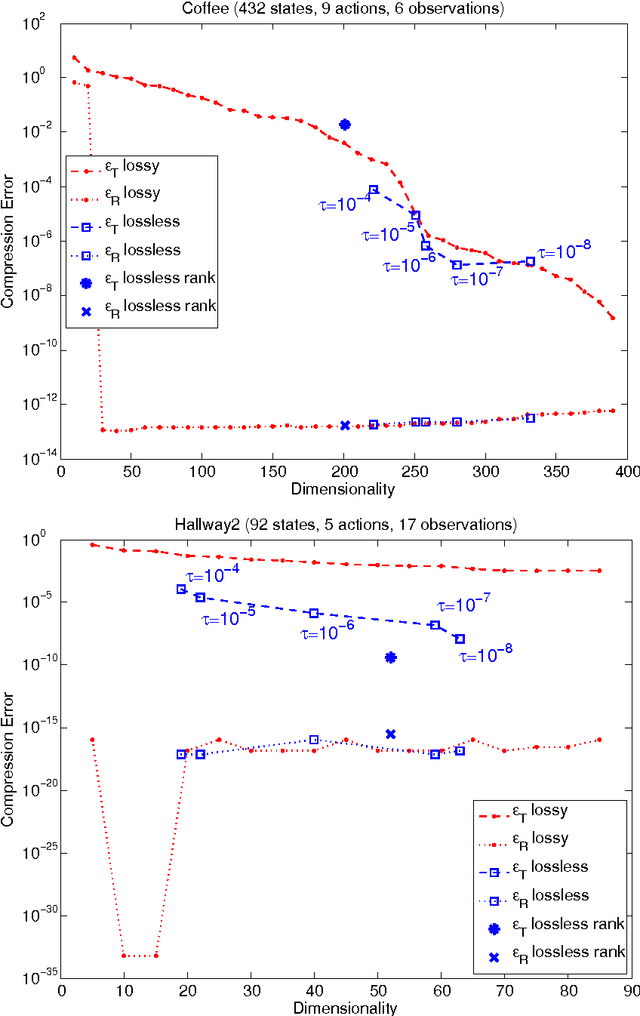
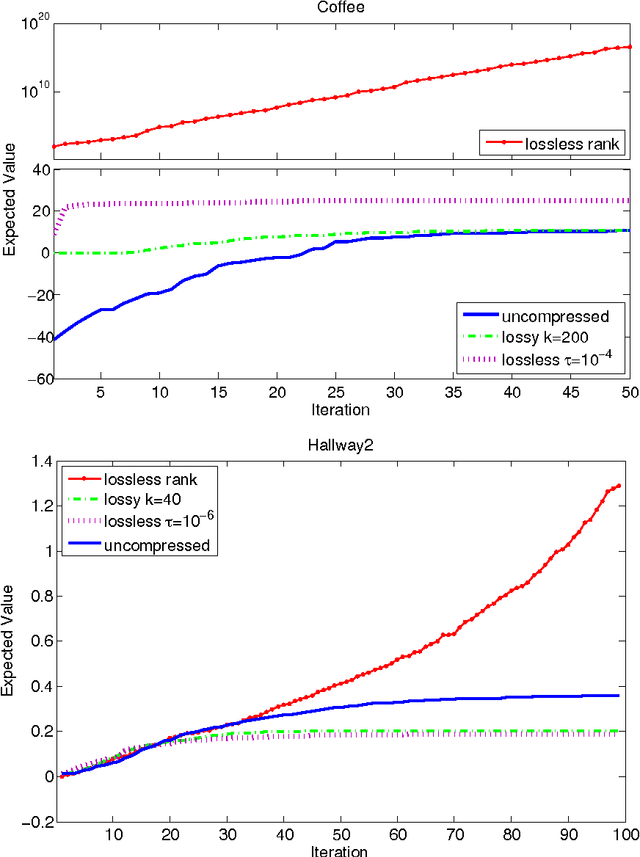
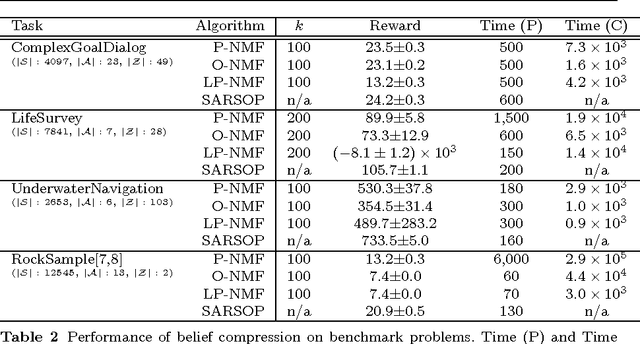
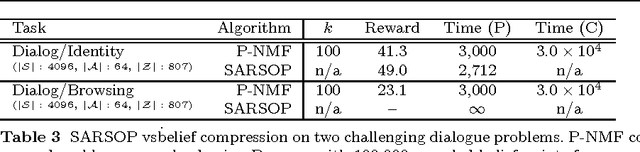
Belief compression improves the tractability of large-scale partially observable Markov decision processes (POMDPs) by finding projections from high-dimensional belief space onto low-dimensional approximations, where solving to obtain action selection policies requires fewer computations. This paper develops a unified theoretical framework to analyse three existing linear belief compression approaches, including value-directed compression and two non-negative matrix factorisation (NMF) based algorithms. The results indicate that all the three known belief compression methods have their own critical deficiencies. Therefore, projective NMF belief compression is proposed (P-NMF), aiming to overcome the drawbacks of the existing techniques. The performance of the proposed algorithm is examined on four POMDP problems of reasonably large scale, in comparison with existing techniques. Additionally, the competitiveness of belief compression is compared empirically to a state-of-the-art heuristic search based POMDP solver and their relative merits in solving large-scale POMDPs are investigated.