 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopical-Chat: Towards Knowledge-Grounded Open-Domain Conversations
Aug 23, 2023



Building socialbots that can have deep, engaging open-domain conversations with humans is one of the grand challenges of artificial intelligence (AI). To this end, bots need to be able to leverage world knowledge spanning several domains effectively when conversing with humans who have their own world knowledge. Existing knowledge-grounded conversation datasets are primarily stylized with explicit roles for conversation partners. These datasets also do not explore depth or breadth of topical coverage with transitions in conversations. We introduce Topical-Chat, a knowledge-grounded human-human conversation dataset where the underlying knowledge spans 8 broad topics and conversation partners don't have explicitly defined roles, to help further research in open-domain conversational AI. We also train several state-of-the-art encoder-decoder conversational models on Topical-Chat and perform automated and human evaluation for benchmarking.
"What do others think?": Task-Oriented Conversational Modeling with Subjective Knowledge
May 20, 2023



Task-oriented Dialogue (TOD) Systems aim to build dialogue systems that assist users in accomplishing specific goals, such as booking a hotel or a restaurant. Traditional TODs rely on domain-specific APIs/DBs or external factual knowledge to generate responses, which cannot accommodate subjective user requests (e.g., "Is the WIFI reliable?" or "Does the restaurant have a good atmosphere?"). To address this issue, we propose a novel task of subjective-knowledge-based TOD (SK-TOD). We also propose the first corresponding dataset, which contains subjective knowledge-seeking dialogue contexts and manually annotated responses grounded in subjective knowledge sources. When evaluated with existing TOD approaches, we find that this task poses new challenges such as aggregating diverse opinions from multiple knowledge snippets. We hope this task and dataset can promote further research on TOD and subjective content understanding. The code and the dataset are available at https://github.com/alexa/dstc11-track5.
DialGuide: Aligning Dialogue Model Behavior with Developer Guidelines
Dec 20, 2022



Dialogue models are able to generate coherent and fluent responses, but they can still be challenging to control and may produce non-engaging, unsafe results. This unpredictability diminishes user trust and can hinder the use of the models in the real world. To address this, we introduce DialGuide, a novel framework for controlling dialogue model behavior using natural language rules, or guidelines. These guidelines provide information about the context they are applicable to and what should be included in the response, allowing the models to generate responses that are more closely aligned with the developer's expectations and intent. We evaluate DialGuide on three tasks in open-domain dialogue response generation: guideline selection, response generation, and response entailment verification. Our dataset contains 10,737 positive and 15,467 negative dialogue context-response-guideline triplets across two domains - chit-chat and safety. We provide baseline models for the tasks and benchmark their performance. We also demonstrate that DialGuide is effective in the dialogue safety domain, producing safe and engaging responses that follow developer guidelines.
A Systematic Evaluation of Response Selection for Open Domain Dialogue
Aug 08, 2022

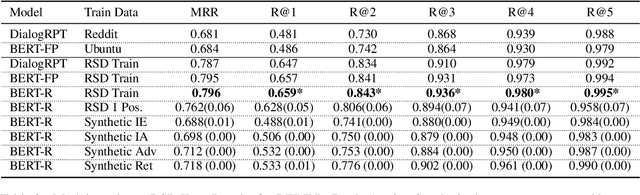
Recent progress on neural approaches for language processing has triggered a resurgence of interest on building intelligent open-domain chatbots. However, even the state-of-the-art neural chatbots cannot produce satisfying responses for every turn in a dialog. A practical solution is to generate multiple response candidates for the same context, and then perform response ranking/selection to determine which candidate is the best. Previous work in response selection typically trains response rankers using synthetic data that is formed from existing dialogs by using a ground truth response as the single appropriate response and constructing inappropriate responses via random selection or using adversarial methods. In this work, we curated a dataset where responses from multiple response generators produced for the same dialog context are manually annotated as appropriate (positive) and inappropriate (negative). We argue that such training data better matches the actual use case examples, enabling the models to learn to rank responses effectively. With this new dataset, we conduct a systematic evaluation of state-of-the-art methods for response selection, and demonstrate that both strategies of using multiple positive candidates and using manually verified hard negative candidates can bring in significant performance improvement in comparison to using the adversarial training data, e.g., increase of 3% and 13% in Recall@1 score, respectively.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
What is wrong with you?: Leveraging User Sentiment for Automatic Dialog Evaluation
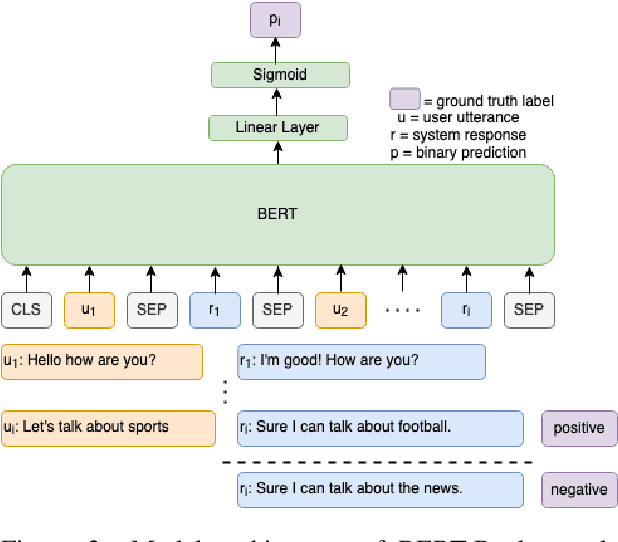
Mar 25, 2022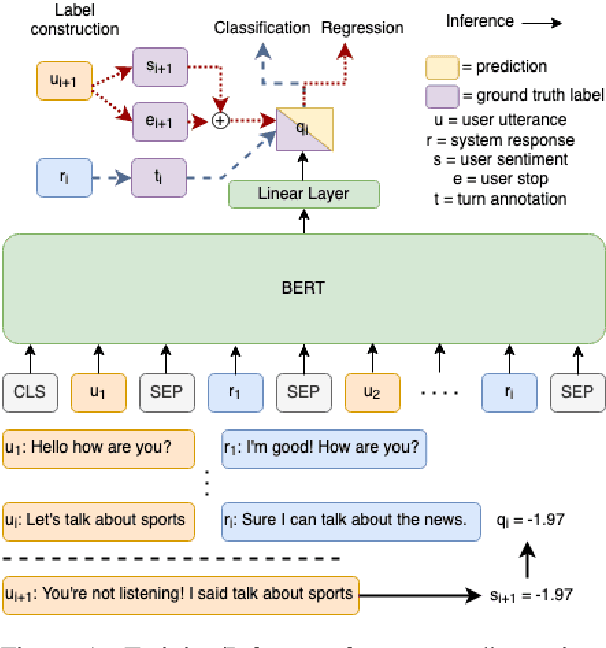

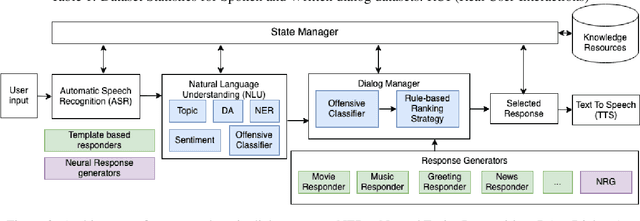
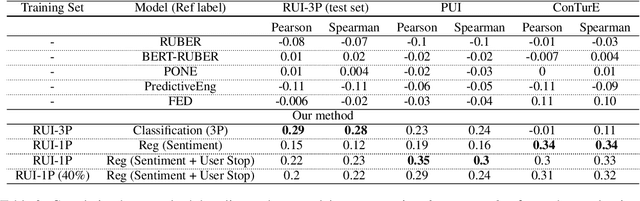
Accurate automatic evaluation metrics for open-domain dialogs are in high demand. Existing model-based metrics for system response evaluation are trained on human annotated data, which is cumbersome to collect. In this work, we propose to use information that can be automatically extracted from the next user utterance, such as its sentiment or whether the user explicitly ends the conversation, as a proxy to measure the quality of the previous system response. This allows us to train on a massive set of dialogs with weak supervision, without requiring manual system turn quality annotations. Experiments show that our model is comparable to models trained on human annotated data. Furthermore, our model generalizes across both spoken and written open-domain dialog corpora collected from real and paid users.
Multi-Sentence Knowledge Selection in Open-Domain Dialogue
Mar 01, 2022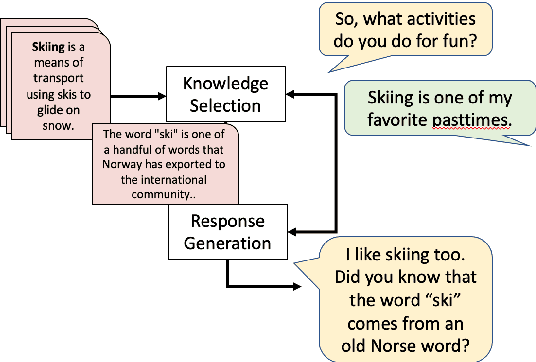



Incorporating external knowledge sources effectively in conversations is a longstanding problem in open-domain dialogue research. The existing literature on open-domain knowledge selection is limited and makes certain brittle assumptions on knowledge sources to simplify the overall task (Dinan et al., 2019), such as the existence of a single relevant knowledge sentence per context. In this work, we evaluate the existing state of open-domain conversation knowledge selection, showing where the existing methodologies regarding data and evaluation are flawed. We then improve on them by proposing a new framework for collecting relevant knowledge, and create an augmented dataset based on the Wizard of Wikipedia (WOW) corpus, which we call WOW++. WOW++ averages 8 relevant knowledge sentences per dialogue context, embracing the inherent ambiguity of open-domain dialogue knowledge selection. We then benchmark various knowledge ranking algorithms on this augmented dataset with both intrinsic evaluation and extrinsic measures of response quality, showing that neural rerankers that use WOW++ can outperform rankers trained on standard datasets.
User Response and Sentiment Prediction for Automatic Dialogue Evaluation
Nov 16, 2021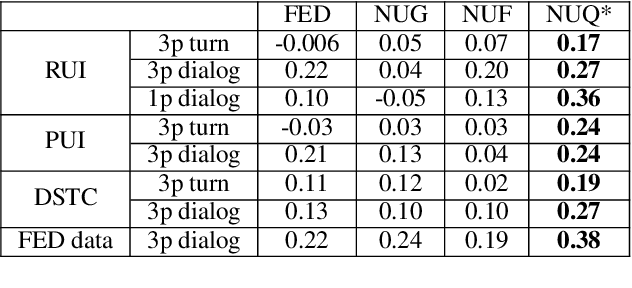
Automatic evaluation is beneficial for open-domain dialog system development. However, standard word-overlap metrics (BLEU, ROUGE) do not correlate well with human judgements of open-domain dialog systems. In this work we propose to use the sentiment of the next user utterance for turn or dialog level evaluation. Specifically we propose three methods: one that predicts the next sentiment directly, and two others that predict the next user utterance using an utterance or a feedback generator model and then classify its sentiment. Experiments show our model outperforming existing automatic evaluation metrics on both written and spoken open-domain dialogue datasets.
Think Before You Speak: Using Self-talk to Generate Implicit Commonsense Knowledge for Response Generation
Oct 16, 2021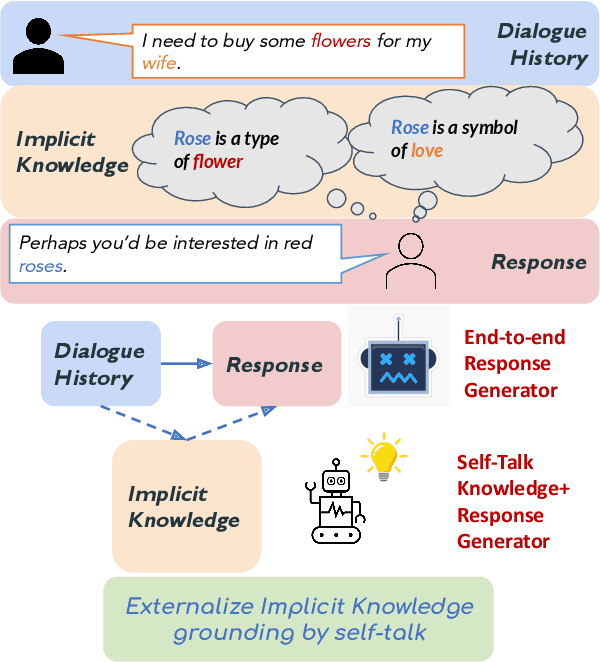
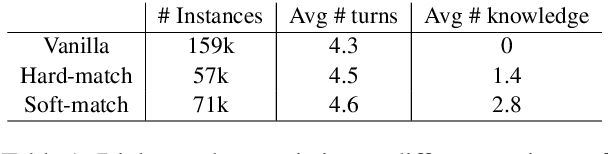
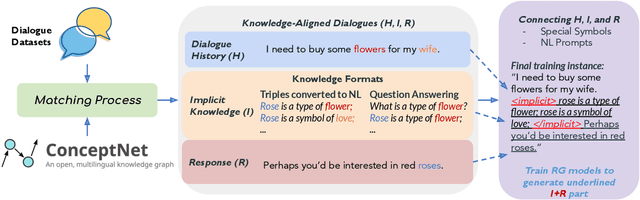

Implicit knowledge, such as common sense, is key to fluid human conversations. Current neural response generation (RG) models are trained end-to-end, omitting unstated implicit knowledge. In this paper, we present a self-talk approach that first generates the implicit commonsense knowledge and then generates response by referencing the externalized knowledge, all using one generative model. We analyze different choices to collect knowledge-aligned dialogues, represent implicit knowledge, and elicit knowledge and responses. We introduce three evaluation aspects: knowledge quality, knowledge-response connection, and response quality and perform extensive human evaluations. Our experimental results show that compared with end-to-end RG models, self-talk models that externalize the knowledge grounding process by explicitly generating implicit knowledge also produce responses that are more informative, specific, and follow common sense. We also find via human evaluation that self-talk models generate high-quality knowledge around 75% of the time. We hope that our findings encourage further work on different approaches to modeling implicit commonsense knowledge and training knowledgeable RG models.
Rome was built in 1776: A Case Study on Factual Correctness in Knowledge-Grounded Response Generation
Oct 11, 2021
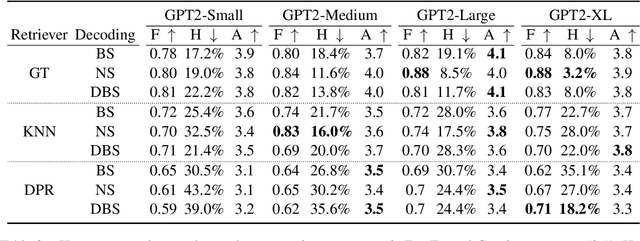


Recently neural response generation models have leveraged large pre-trained transformer models and knowledge snippets to generate relevant and informative responses. However, this does not guarantee that generated responses are factually correct. In this paper, we examine factual correctness in knowledge-grounded neural response generation models. We present a human annotation setup to identify three different response types: responses that are factually consistent with respect to the input knowledge, responses that contain hallucinated knowledge, and non-verifiable chitchat style responses. We use this setup to annotate responses generated using different stateof-the-art models, knowledge snippets, and decoding strategies. In addition, to facilitate the development of a factual consistency detector, we automatically create a new corpus called Conv-FEVER that is adapted from the Wizard of Wikipedia dataset and includes factually consistent and inconsistent responses. We demonstrate the benefit of our Conv-FEVER dataset by showing that the models trained on this data perform reasonably well to detect factually inconsistent responses with respect to the provided knowledge through evaluation on our human annotated data. We will release the Conv-FEVER dataset and the human annotated responses.