 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Do LLMs Recognize Your Preferences? Evaluating Personalized Preference Following in LLMs
Feb 13, 2025



Large Language Models (LLMs) are increasingly used as chatbots, yet their ability to personalize responses to user preferences remains limited. We introduce PrefEval, a benchmark for evaluating LLMs' ability to infer, memorize and adhere to user preferences in a long-context conversational setting. PrefEval comprises 3,000 manually curated user preference and query pairs spanning 20 topics. PrefEval contains user personalization or preference information in both explicit and implicit forms, and evaluates LLM performance using a generation and a classification task. With PrefEval, we evaluated the aforementioned preference following capabilities of 10 open-source and proprietary LLMs in multi-session conversations with varying context lengths up to 100k tokens. We benchmark with various prompting, iterative feedback, and retrieval-augmented generation methods. Our benchmarking effort reveals that state-of-the-art LLMs face significant challenges in proactively following users' preferences during conversations. In particular, in zero-shot settings, preference following accuracy falls below 10% at merely 10 turns (~3k tokens) across most evaluated models. Even with advanced prompting and retrieval methods, preference following still deteriorates in long-context conversations. Furthermore, we show that fine-tuning on PrefEval significantly improves performance. We believe PrefEval serves as a valuable resource for measuring, understanding, and enhancing LLMs' preference following abilities, paving the way for personalized conversational agents. Our code and dataset are available at https://prefeval.github.io/.
From Pixels to Personas: Investigating and Modeling Self-Anthropomorphism in Human-Robot Dialogues
Oct 04, 2024



Self-anthropomorphism in robots manifests itself through their display of human-like characteristics in dialogue, such as expressing preferences and emotions. Our study systematically analyzes self-anthropomorphic expression within various dialogue datasets, outlining the contrasts between self-anthropomorphic and non-self-anthropomorphic responses in dialogue systems. We show significant differences in these two types of responses and propose transitioning from one type to the other. We also introduce Pix2Persona, a novel dataset aimed at developing ethical and engaging AI systems in various embodiments. This dataset preserves the original dialogues from existing corpora and enhances them with paired responses: self-anthropomorphic and non-self-anthropomorphic for each original bot response. Our work not only uncovers a new category of bot responses that were previously under-explored but also lays the groundwork for future studies about dynamically adjusting self-anthropomorphism levels in AI systems to align with ethical standards and user expectations.
CESAR: Automatic Induction of Compositional Instructions for Multi-turn Dialogs
Nov 29, 2023Instruction-based multitasking has played a critical role in the success of large language models (LLMs) in multi-turn dialog applications. While publicly available LLMs have shown promising performance, when exposed to complex instructions with multiple constraints, they lag against state-of-the-art models like ChatGPT. In this work, we hypothesize that the availability of large-scale complex demonstrations is crucial in bridging this gap. Focusing on dialog applications, we propose a novel framework, CESAR, that unifies a large number of dialog tasks in the same format and allows programmatic induction of complex instructions without any manual effort. We apply CESAR on InstructDial, a benchmark for instruction-based dialog tasks. We further enhance InstructDial with new datasets and tasks and utilize CESAR to induce complex tasks with compositional instructions. This results in a new benchmark called InstructDial++, which includes 63 datasets with 86 basic tasks and 68 composite tasks. Through rigorous experiments, we demonstrate the scalability of CESAR in providing rich instructions. Models trained on InstructDial++ can follow compositional prompts, such as prompts that ask for multiple stylistic constraints.
Data-Efficient Alignment of Large Language Models with Human Feedback Through Natural Language
Nov 24, 2023



Learning from human feedback is a prominent technique to align the output of large language models (LLMs) with human expectations. Reinforcement learning from human feedback (RLHF) leverages human preference signals that are in the form of ranking of response pairs to perform this alignment. However, human preference on LLM outputs can come in much richer forms including natural language, which may provide detailed feedback on strengths and weaknesses of a given response. In this work we investigate data efficiency of modeling human feedback that is in natural language. Specifically, we fine-tune an open-source LLM, e.g., Falcon-40B-Instruct, on a relatively small amount (1000 records or even less) of human feedback in natural language in the form of critiques and revisions of responses. We show that this model is able to improve the quality of responses from even some of the strongest LLMs such as ChatGPT, BARD, and Vicuna, through critique and revision of those responses. For instance, through one iteration of revision of ChatGPT responses, the revised responses have 56.6% win rate over the original ones, and this win rate can be further improved to 65.9% after applying the revision for five iterations.
"What do others think?": Task-Oriented Conversational Modeling with Subjective Knowledge
May 20, 2023



Task-oriented Dialogue (TOD) Systems aim to build dialogue systems that assist users in accomplishing specific goals, such as booking a hotel or a restaurant. Traditional TODs rely on domain-specific APIs/DBs or external factual knowledge to generate responses, which cannot accommodate subjective user requests (e.g., "Is the WIFI reliable?" or "Does the restaurant have a good atmosphere?"). To address this issue, we propose a novel task of subjective-knowledge-based TOD (SK-TOD). We also propose the first corresponding dataset, which contains subjective knowledge-seeking dialogue contexts and manually annotated responses grounded in subjective knowledge sources. When evaluated with existing TOD approaches, we find that this task poses new challenges such as aggregating diverse opinions from multiple knowledge snippets. We hope this task and dataset can promote further research on TOD and subjective content understanding. The code and the dataset are available at https://github.com/alexa/dstc11-track5.
KILM: Knowledge Injection into Encoder-Decoder Language Models
Feb 17, 2023



Large pre-trained language models (PLMs) have been shown to retain implicit knowledge within their parameters. To enhance this implicit knowledge, we propose Knowledge Injection into Language Models (KILM), a novel approach that injects entity-related knowledge into encoder-decoder PLMs, via a generative knowledge infilling objective through continued pre-training. This is done without architectural modifications to the PLMs or adding additional parameters. Experimental results over a suite of knowledge-intensive tasks spanning numerous datasets show that KILM enables models to retain more knowledge and hallucinate less, while preserving their original performance on general NLU and NLG tasks. KILM also demonstrates improved zero-shot performances on tasks such as entity disambiguation, outperforming state-of-the-art models having 30x more parameters.
Role of Bias Terms in Dot-Product Attention
Feb 16, 2023Dot-product attention is a core module in the present generation of neural network models, particularly transformers, and is being leveraged across numerous areas such as natural language processing and computer vision. This attention module is comprised of three linear transformations, namely query, key, and value linear transformations, each of which has a bias term. In this work, we study the role of these bias terms, and mathematically show that the bias term of the key linear transformation is redundant and could be omitted without any impact on the attention module. Moreover, we argue that the bias term of the value linear transformation has a more prominent role than that of the bias term of the query linear transformation. We empirically verify these findings through multiple experiments on language modeling, natural language understanding, and natural language generation tasks.
Selective In-Context Data Augmentation for Intent Detection using Pointwise V-Information
Feb 10, 2023

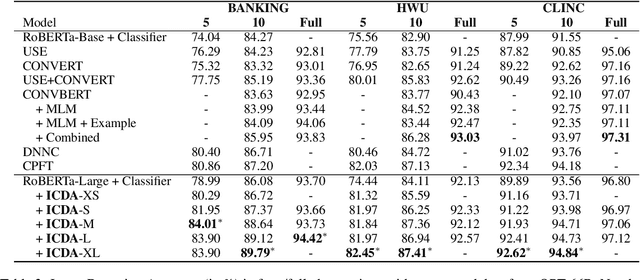
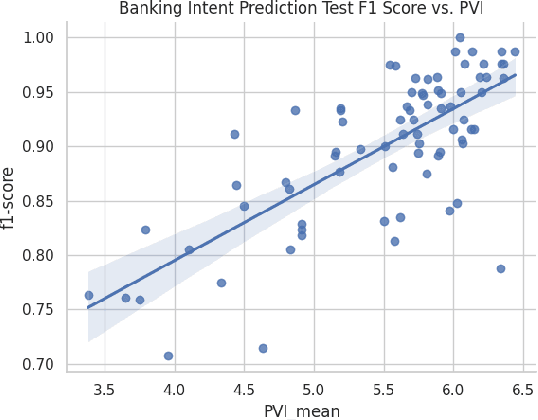
This work focuses on in-context data augmentation for intent detection. Having found that augmentation via in-context prompting of large pre-trained language models (PLMs) alone does not improve performance, we introduce a novel approach based on PLMs and pointwise V-information (PVI), a metric that can measure the usefulness of a datapoint for training a model. Our method first fine-tunes a PLM on a small seed of training data and then synthesizes new datapoints - utterances that correspond to given intents. It then employs intent-aware filtering, based on PVI, to remove datapoints that are not helpful to the downstream intent classifier. Our method is thus able to leverage the expressive power of large language models to produce diverse training data. Empirical results demonstrate that our method can produce synthetic training data that achieve state-of-the-art performance on three challenging intent detection datasets under few-shot settings (1.28% absolute improvement in 5-shot and 1.18% absolute in 10-shot, on average) and perform on par with the state-of-the-art in full-shot settings (within 0.01% absolute, on average).
Using In-Context Learning to Improve Dialogue Safety
Feb 02, 2023



While large neural-based conversational models have become increasingly proficient as dialogue agents, recent work has highlighted safety issues with these systems. For example, these systems can be goaded into generating toxic content, which often perpetuates social biases or stereotypes. We investigate a retrieval-based framework for reducing bias and toxicity in responses generated from neural-based chatbots. It uses in-context learning to steer a model towards safer generations. Concretely, to generate a response to an unsafe dialogue context, we retrieve demonstrations of safe model responses to similar dialogue contexts. We find our proposed approach performs competitively with strong baselines which use fine-tuning. For instance, using automatic evaluation, we find our best fine-tuned baseline only generates safe responses to unsafe dialogue contexts from DiaSafety 2.92% more than our approach. Finally, we also propose a straightforward re-ranking procedure which can further improve response safeness.