 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Jan 26, 2026Knowledge distillation improves large language model (LLM) reasoning by compressing the knowledge of a teacher LLM to train smaller LLMs. On-policy distillation advances this approach by having the student sample its own trajectories while a teacher LLM provides dense token-level supervision, addressing the distribution mismatch between training and inference in off-policy distillation methods. However, on-policy distillation typically requires a separate, often larger, teacher LLM and does not explicitly leverage ground-truth solutions available in reasoning datasets. Inspired by the intuition that a sufficiently capable LLM can rationalize external privileged reasoning traces and teach its weaker self (i.e., the version without access to privileged information), we introduce On-Policy Self-Distillation (OPSD), a framework where a single model acts as both teacher and student by conditioning on different contexts. The teacher policy conditions on privileged information (e.g., verified reasoning traces) while the student policy sees only the question; training minimizes the per-token divergence between these distributions over the student's own rollouts. We demonstrate the efficacy of our method on multiple mathematical reasoning benchmarks, achieving 4-8x token efficiency compared to reinforcement learning methods such as GRPO and superior performance over off-policy distillation methods.
The performances of the Chinese and U.S. Large Language Models on the Topic of Chinese Culture
Jan 07, 2026Cultural backgrounds shape individuals' perspectives and approaches to problem-solving. Since the emergence of GPT-1 in 2018, large language models (LLMs) have undergone rapid development. To date, the world's ten leading LLM developers are primarily based in China and the United States. To examine whether LLMs released by Chinese and U.S. developers exhibit cultural differences in Chinese-language settings, we evaluate their performance on questions about Chinese culture. This study adopts a direct-questioning paradigm to evaluate models such as GPT-5.1, DeepSeek-V3.2, Qwen3-Max, and Gemini2.5Pro. We assess their understanding of traditional Chinese culture, including history, literature, poetry, and related domains. Comparative analyses between LLMs developed in China and the U.S. indicate that Chinese models generally outperform their U.S. counterparts on these tasks. Among U.S.-developed models, Gemini 2.5Pro and GPT-5.1 achieve relatively higher accuracy. The observed performance differences may potentially arise from variations in training data distribution, localization strategies, and the degree of emphasis on Chinese cultural content during model development.
SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models
Oct 10, 2025Diffusion large language models (dLLMs) are emerging as an efficient alternative to autoregressive models due to their ability to decode multiple tokens in parallel. However, aligning dLLMs with human preferences or task-specific rewards via reinforcement learning (RL) is challenging because their intractable log-likelihood precludes the direct application of standard policy gradient methods. While prior work uses surrogates like the evidence lower bound (ELBO), these one-sided approximations can introduce significant policy gradient bias. To address this, we propose the Sandwiched Policy Gradient (SPG) that leverages both an upper and a lower bound of the true log-likelihood. Experiments show that SPG significantly outperforms baselines based on ELBO or one-step estimation. Specifically, SPG improves the accuracy over state-of-the-art RL methods for dLLMs by 3.6% in GSM8K, 2.6% in MATH500, 18.4% in Countdown and 27.0% in Sudoku.
d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning
Apr 16, 2025Recent large language models (LLMs) have demonstrated strong reasoning capabilities that benefits from online reinforcement learning (RL). These capabilities have primarily been demonstrated within the left-to-right autoregressive (AR) generation paradigm. In contrast, non-autoregressive paradigms based on diffusion generate text in a coarse-to-fine manner. Although recent diffusion-based large language models (dLLMs) have achieved competitive language modeling performance compared to their AR counterparts, it remains unclear if dLLMs can also leverage recent advances in LLM reasoning. To this end, we propose d1, a framework to adapt pre-trained masked dLLMs into reasoning models via a combination of supervised finetuning (SFT) and RL. Specifically, we develop and extend techniques to improve reasoning in pretrained dLLMs: (a) we utilize a masked SFT technique to distill knowledge and instill self-improvement behavior directly from existing datasets, and (b) we introduce a novel critic-free, policy-gradient based RL algorithm called diffu-GRPO. Through empirical studies, we investigate the performance of different post-training recipes on multiple mathematical and logical reasoning benchmarks. We find that d1 yields the best performance and significantly improves performance of a state-of-the-art dLLM.
Multi-fidelity Reinforcement Learning Control for Complex Dynamical Systems
Apr 08, 2025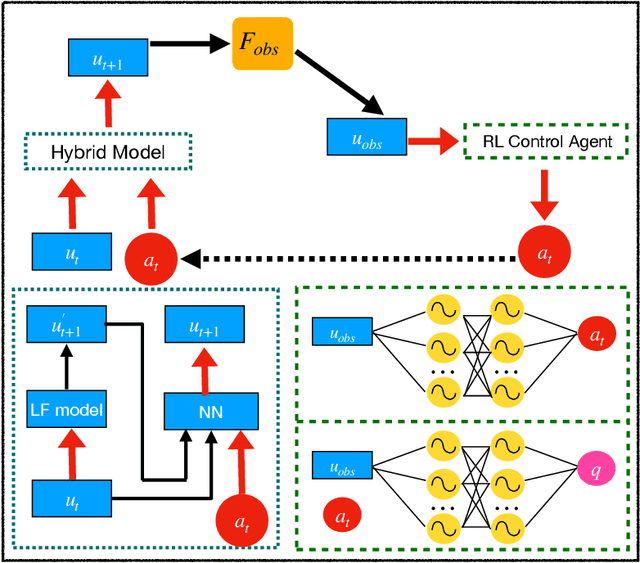
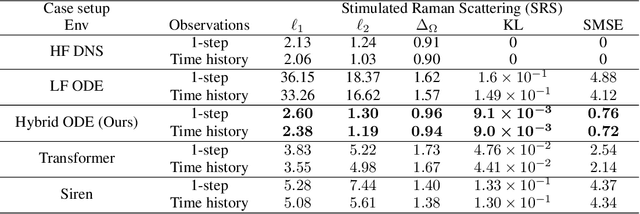
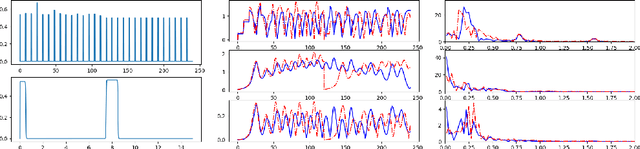
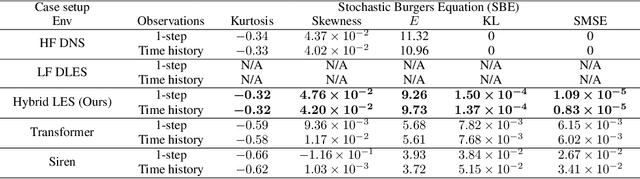
Controlling instabilities in complex dynamical systems is challenging in scientific and engineering applications. Deep reinforcement learning (DRL) has seen promising results for applications in different scientific applications. The many-query nature of control tasks requires multiple interactions with real environments of the underlying physics. However, it is usually sparse to collect from the experiments or expensive to simulate for complex dynamics. Alternatively, controlling surrogate modeling could mitigate the computational cost issue. However, a fast and accurate learning-based model by offline training makes it very hard to get accurate pointwise dynamics when the dynamics are chaotic. To bridge this gap, the current work proposes a multi-fidelity reinforcement learning (MFRL) framework that leverages differentiable hybrid models for control tasks, where a physics-based hybrid model is corrected by limited high-fidelity data. We also proposed a spectrum-based reward function for RL learning. The effect of the proposed framework is demonstrated on two complex dynamics in physics. The statistics of the MFRL control result match that computed from many-query evaluations of the high-fidelity environments and outperform other SOTA baselines.
Do LLMs Recognize Your Preferences? Evaluating Personalized Preference Following in LLMs
Feb 13, 2025



Large Language Models (LLMs) are increasingly used as chatbots, yet their ability to personalize responses to user preferences remains limited. We introduce PrefEval, a benchmark for evaluating LLMs' ability to infer, memorize and adhere to user preferences in a long-context conversational setting. PrefEval comprises 3,000 manually curated user preference and query pairs spanning 20 topics. PrefEval contains user personalization or preference information in both explicit and implicit forms, and evaluates LLM performance using a generation and a classification task. With PrefEval, we evaluated the aforementioned preference following capabilities of 10 open-source and proprietary LLMs in multi-session conversations with varying context lengths up to 100k tokens. We benchmark with various prompting, iterative feedback, and retrieval-augmented generation methods. Our benchmarking effort reveals that state-of-the-art LLMs face significant challenges in proactively following users' preferences during conversations. In particular, in zero-shot settings, preference following accuracy falls below 10% at merely 10 turns (~3k tokens) across most evaluated models. Even with advanced prompting and retrieval methods, preference following still deteriorates in long-context conversations. Furthermore, we show that fine-tuning on PrefEval significantly improves performance. We believe PrefEval serves as a valuable resource for measuring, understanding, and enhancing LLMs' preference following abilities, paving the way for personalized conversational agents. Our code and dataset are available at https://prefeval.github.io/.
MedMax: Mixed-Modal Instruction Tuning for Training Biomedical Assistants
Dec 17, 2024Recent advancements in mixed-modal generative models have enabled flexible integration of information across image-text content. These models have opened new avenues for developing unified biomedical assistants capable of analyzing biomedical images, answering complex questions about them, and predicting the impact of medical procedures on a patient's health. However, existing resources face challenges such as limited data availability, narrow domain coverage, and restricted sources (e.g., medical papers). To address these gaps, we present MedMax, the first large-scale multimodal biomedical instruction-tuning dataset for mixed-modal foundation models. With 1.47 million instances, MedMax encompasses a diverse range of tasks, including multimodal content generation (interleaved image-text data), biomedical image captioning and generation, visual chatting, and report understanding. These tasks span diverse medical domains such as radiology and histopathology. Subsequently, we fine-tune a mixed-modal foundation model on the MedMax dataset, achieving significant performance improvements: a 26% gain over the Chameleon model and an 18.3% improvement over GPT-4o across 12 downstream biomedical visual question-answering tasks. Additionally, we introduce a unified evaluation suite for biomedical tasks, providing a robust framework to guide the development of next-generation mixed-modal biomedical AI assistants.
DODT: Enhanced Online Decision Transformer Learning through Dreamer's Actor-Critic Trajectory Forecasting
Oct 15, 2024
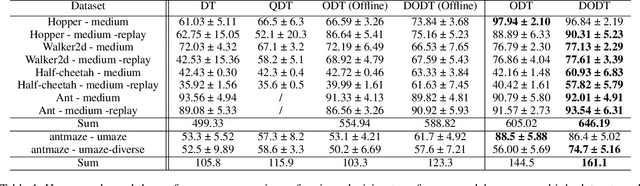
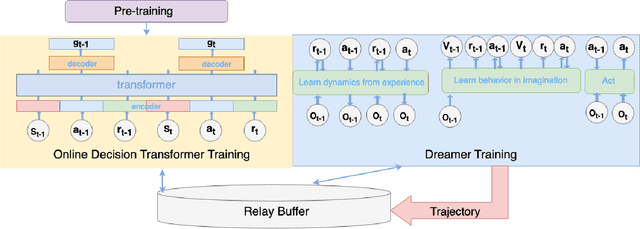
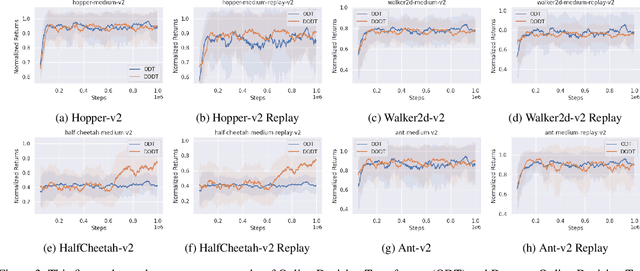
Advancements in reinforcement learning have led to the development of sophisticated models capable of learning complex decision-making tasks. However, efficiently integrating world models with decision transformers remains a challenge. In this paper, we introduce a novel approach that combines the Dreamer algorithm's ability to generate anticipatory trajectories with the adaptive learning strengths of the Online Decision Transformer. Our methodology enables parallel training where Dreamer-produced trajectories enhance the contextual decision-making of the transformer, creating a bidirectional enhancement loop. We empirically demonstrate the efficacy of our approach on a suite of challenging benchmarks, achieving notable improvements in sample efficiency and reward maximization over existing methods. Our results indicate that the proposed integrated framework not only accelerates learning but also showcases robustness in diverse and dynamic scenarios, marking a significant step forward in model-based reinforcement learning.
Probing the Decision Boundaries of In-context Learning in Large Language Models
Jun 17, 2024

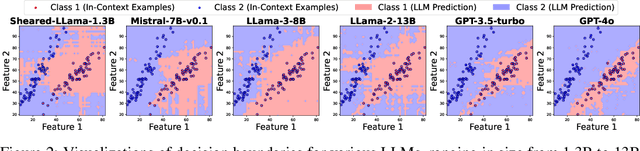

In-context learning is a key paradigm in large language models (LLMs) that enables them to generalize to new tasks and domains by simply prompting these models with a few exemplars without explicit parameter updates. Many attempts have been made to understand in-context learning in LLMs as a function of model scale, pretraining data, and other factors. In this work, we propose a new mechanism to probe and understand in-context learning from the lens of decision boundaries for in-context binary classification. Decision boundaries are straightforward to visualize and provide important information about the qualitative behavior of the inductive biases of standard classifiers. To our surprise, we find that the decision boundaries learned by current LLMs in simple binary classification tasks are often irregular and non-smooth, regardless of linear separability in the underlying task. This paper investigates the factors influencing these decision boundaries and explores methods to enhance their generalizability. We assess various approaches, including training-free and fine-tuning methods for LLMs, the impact of model architecture, and the effectiveness of active prompting techniques for smoothing decision boundaries in a data-efficient manner. Our findings provide a deeper understanding of in-context learning dynamics and offer practical improvements for enhancing robustness and generalizability of in-context learning.
Prepacking: A Simple Method for Fast Prefilling and Increased Throughput in Large Language Models
Apr 15, 2024



During inference for transformer-based large language models (LLM), prefilling is the computation of the key-value (KV) cache for input tokens in the prompt prior to autoregressive generation. For longer input prompt lengths, prefilling will incur a significant overhead on decoding time. In this work, we highlight the following pitfall of prefilling: for batches containing high-varying prompt lengths, significant computation is wasted by the standard practice of padding sequences to the maximum length. As LLMs increasingly support longer context lengths, potentially up to 10 million tokens, variations in prompt lengths within a batch become more pronounced. To address this, we propose Prepacking, a simple yet effective method to optimize prefilling computation. To avoid redundant computation on pad tokens, prepacking combines prompts of varying lengths into a sequence and packs multiple sequences into a compact batch using a bin-packing algorithm. It then modifies the attention mask and positional encoding to compute multiple prefilled KV-caches for multiple prompts within a single sequence. On standard curated dataset containing prompts with varying lengths, we obtain a significant speed and memory efficiency improvements as compared to the default padding-based prefilling computation within Huggingface across a range of base model configurations and inference serving scenarios.