 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning
Apr 16, 2025Recent large language models (LLMs) have demonstrated strong reasoning capabilities that benefits from online reinforcement learning (RL). These capabilities have primarily been demonstrated within the left-to-right autoregressive (AR) generation paradigm. In contrast, non-autoregressive paradigms based on diffusion generate text in a coarse-to-fine manner. Although recent diffusion-based large language models (dLLMs) have achieved competitive language modeling performance compared to their AR counterparts, it remains unclear if dLLMs can also leverage recent advances in LLM reasoning. To this end, we propose d1, a framework to adapt pre-trained masked dLLMs into reasoning models via a combination of supervised finetuning (SFT) and RL. Specifically, we develop and extend techniques to improve reasoning in pretrained dLLMs: (a) we utilize a masked SFT technique to distill knowledge and instill self-improvement behavior directly from existing datasets, and (b) we introduce a novel critic-free, policy-gradient based RL algorithm called diffu-GRPO. Through empirical studies, we investigate the performance of different post-training recipes on multiple mathematical and logical reasoning benchmarks. We find that d1 yields the best performance and significantly improves performance of a state-of-the-art dLLM.
Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning
Feb 05, 2025



Large Language Models (LLMs) excel at reasoning and planning when trained on chainof-thought (CoT) data, where the step-by-step thought process is explicitly outlined by text tokens. However, this results in lengthy inputs where many words support textual coherence rather than core reasoning information, and processing these inputs consumes substantial computation resources. In this work, we propose a hybrid representation of the reasoning process, where we partially abstract away the initial reasoning steps using latent discrete tokens generated by VQ-VAE, significantly reducing the length of reasoning traces. We explore the use of latent trace abstractions in two scenarios: 1) training the model from scratch for the Keys-Finding Maze problem, 2) fine-tuning LLMs on this hybrid data with an extended vocabulary including unseen latent tokens, for both logical and mathematical reasoning problems. To facilitate effective learning, we introduce a simple training procedure that randomly mixes latent and text tokens, which enables fast adaptation to new latent tokens. Our approach consistently outperforms the baselines methods in various benchmarks.
Online Intrinsic Rewards for Decision Making Agents from Large Language Model Feedback
Oct 30, 2024Automatically synthesizing dense rewards from natural language descriptions is a promising paradigm in reinforcement learning (RL), with applications to sparse reward problems, open-ended exploration, and hierarchical skill design. Recent works have made promising steps by exploiting the prior knowledge of large language models (LLMs). However, these approaches suffer from important limitations: they are either not scalable to problems requiring billions of environment samples; or are limited to reward functions expressible by compact code, which may require source code and have difficulty capturing nuanced semantics; or require a diverse offline dataset, which may not exist or be impossible to collect. In this work, we address these limitations through a combination of algorithmic and systems-level contributions. We propose ONI, a distributed architecture that simultaneously learns an RL policy and an intrinsic reward function using LLM feedback. Our approach annotates the agent's collected experience via an asynchronous LLM server, which is then distilled into an intrinsic reward model. We explore a range of algorithmic choices for reward modeling with varying complexity, including hashing, classification, and ranking models. By studying their relative tradeoffs, we shed light on questions regarding intrinsic reward design for sparse reward problems. Our approach achieves state-of-the-art performance across a range of challenging, sparse reward tasks from the NetHack Learning Environment in a simple unified process, solely using the agent's gathered experience, without requiring external datasets nor source code. We make our code available at \url{URL} (coming soon).
Dualformer: Controllable Fast and Slow Thinking by Learning with Randomized Reasoning Traces
Oct 13, 2024In human cognition theory, human thinking is governed by two systems: the fast and intuitive System 1 and the slower but more deliberative System 2. Recent studies have shown that incorporating System 2 process into Transformers including large language models (LLMs), significantly enhances their reasoning capabilities. Nevertheless, models that purely resemble System 2 thinking require substantially higher computational costs and are much slower to respond. To address this challenge, we present Dualformer, a single Transformer model that seamlessly integrates both the fast and slow reasoning modes. Dualformer is obtained by training on data with randomized reasoning traces, where different parts of the traces are dropped during training. The dropping strategies are specifically tailored according to the trace structure, analogous to analyzing our thinking process and creating shortcuts with patterns. At inference time, our model can be configured to output only the solutions (fast mode) or both the reasoning chain and the final solution (slow mode), or automatically decide which mode to engage (auto mode). In all cases, Dualformer outperforms the corresponding baseline models in both performance and computational efficiency: (1) in slow mode, Dualformer optimally solves unseen 30 x 30 maze navigation tasks 97.6% of the time, surpassing the Searchformer (trained on data with complete reasoning traces) baseline performance of 93.3%, while only using 45.5% fewer reasoning steps; (2) in fast mode, Dualformer completes those tasks with an 80% optimal rate, significantly outperforming the Solution-Only model (trained on solution-only data), which has an optimal rate of only 30%. For math problems, our techniques have also achieved improved performance with LLM fine-tuning, showing its generalization beyond task-specific models.
Diffusion World Model
Feb 11, 2024



We introduce Diffusion World Model (DWM), a conditional diffusion model capable of predicting multistep future states and rewards concurrently. As opposed to traditional one-step dynamics models, DWM offers long-horizon predictions in a single forward pass, eliminating the need for recursive queries. We integrate DWM into model-based value estimation, where the short-term return is simulated by future trajectories sampled from DWM. In the context of offline reinforcement learning, DWM can be viewed as a conservative value regularization through generative modeling. Alternatively, it can be seen as a data source that enables offline Q-learning with synthetic data. Our experiments on the D4RL dataset confirm the robustness of DWM to long-horizon simulation. In terms of absolute performance, DWM significantly surpasses one-step dynamics models with a $44\%$ performance gain, and achieves state-of-the-art performance.
Guided Flows for Generative Modeling and Decision Making
Dec 07, 2023Classifier-free guidance is a key component for enhancing the performance of conditional generative models across diverse tasks. While it has previously demonstrated remarkable improvements for the sample quality, it has only been exclusively employed for diffusion models. In this paper, we integrate classifier-free guidance into Flow Matching (FM) models, an alternative simulation-free approach that trains Continuous Normalizing Flows (CNFs) based on regressing vector fields. We explore the usage of \emph{Guided Flows} for a variety of downstream applications. We show that Guided Flows significantly improves the sample quality in conditional image generation and zero-shot text-to-speech synthesis, boasting state-of-the-art performance. Notably, we are the first to apply flow models for plan generation in the offline reinforcement learning setting, showcasing a 10x speedup in computation compared to diffusion models while maintaining comparable performance.
Semi-Supervised Offline Reinforcement Learning with Action-Free Trajectories
Oct 12, 2022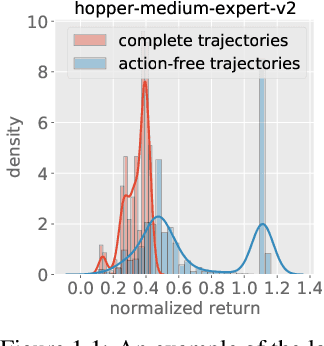
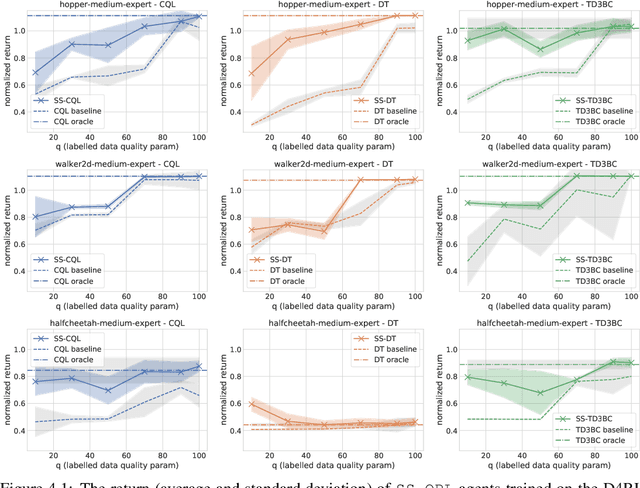
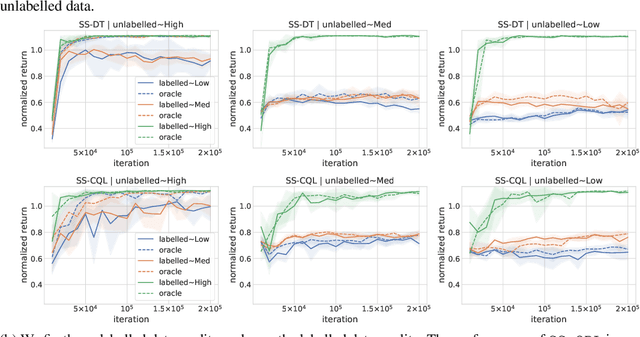
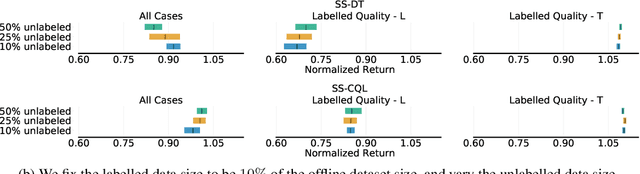
Natural agents can effectively learn from multiple data sources that differ in size, quality, and types of measurements. We study this heterogeneity in the context of offline reinforcement learning (RL) by introducing a new, practically motivated semi-supervised setting. Here, an agent has access to two sets of trajectories: labelled trajectories containing state, action, reward triplets at every timestep, along with unlabelled trajectories that contain only state and reward information. For this setting, we develop a simple meta-algorithmic pipeline that learns an inverse-dynamics model on the labelled data to obtain proxy-labels for the unlabelled data, followed by the use of any offline RL algorithm on the true and proxy-labelled trajectories. Empirically, we find this simple pipeline to be highly successful -- on several D4RL benchmarks \cite{fu2020d4rl}, certain offline RL algorithms can match the performance of variants trained on a fully labeled dataset even when we label only 10\% trajectories from the low return regime. Finally, we perform a large-scale controlled empirical study investigating the interplay of data-centric properties of the labelled and unlabelled datasets, with algorithmic design choices (e.g., inverse dynamics, offline RL algorithm) to identify general trends and best practices for training RL agents on semi-supervised offline datasets.
ConserWeightive Behavioral Cloning for Reliable Offline Reinforcement Learning
Oct 11, 2022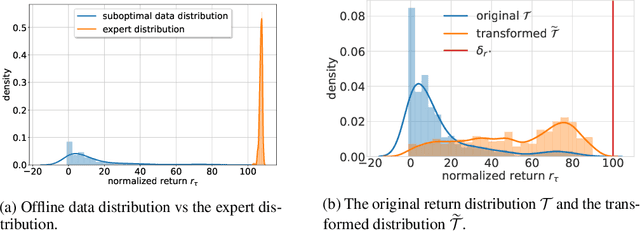
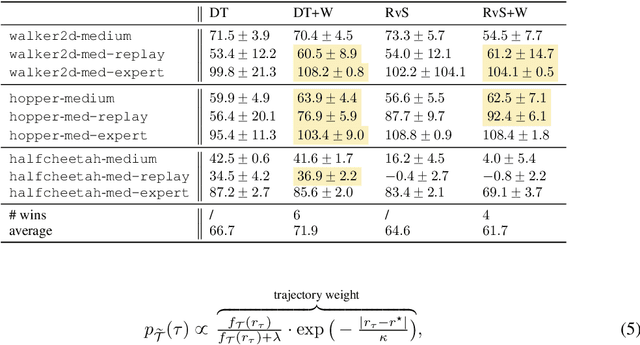
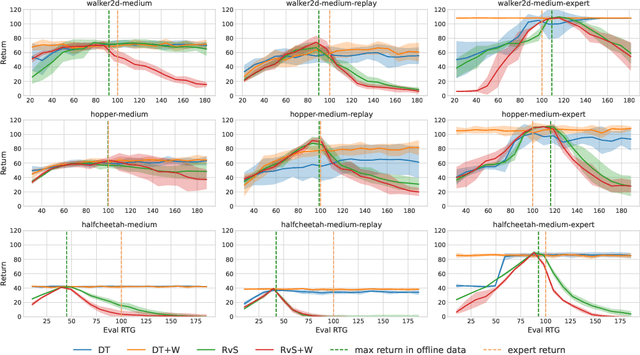
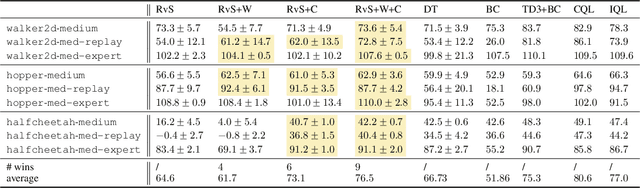
The goal of offline reinforcement learning (RL) is to learn near-optimal policies from static logged datasets, thus sidestepping expensive online interactions. Behavioral cloning (BC) provides a straightforward solution to offline RL by mimicking offline trajectories via supervised learning. Recent advances (Chen et al., 2021; Janner et al., 2021; Emmons et al., 2021) have shown that by conditioning on desired future returns, BC can perform competitively to their value-based counterparts, while enjoying much more simplicity and training stability. However, the distribution of returns in the offline dataset can be arbitrarily skewed and suboptimal, which poses a unique challenge for conditioning BC on expert returns at test time. We propose ConserWeightive Behavioral Cloning (CWBC), a simple and effective method for improving the performance of conditional BC for offline RL with two key components: trajectory weighting and conservative regularization. Trajectory weighting addresses the bias-variance tradeoff in conditional BC and provides a principled mechanism to learn from both low return trajectories (typically plentiful) and high return trajectories (typically few). Further, we analyze the notion of conservatism in existing BC methods, and propose a novel conservative regularize that explicitly encourages the policy to stay close to the data distribution. The regularizer helps achieve more reliable performance, and removes the need for ad-hoc tuning of the conditioning value during evaluation. We instantiate CWBC in the context of Reinforcement Learning via Supervised Learning (RvS) (Emmons et al., 2021) and Decision Transformer (DT) (Chen et al., 2021), and empirically show that it significantly boosts the performance and stability of prior methods on various offline RL benchmarks. Code is available at https://github.com/tung-nd/cwbc.
Latent State Marginalization as a Low-cost Approach for Improving Exploration
Oct 03, 2022

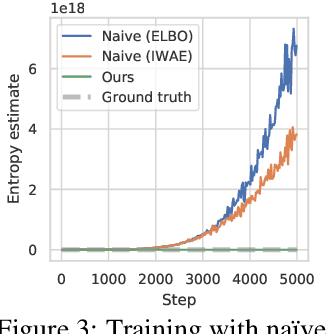
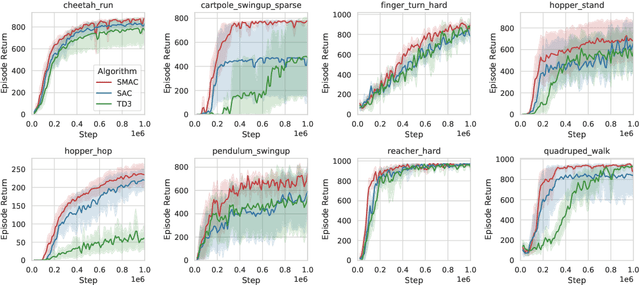
While the maximum entropy (MaxEnt) reinforcement learning (RL) framework -- often touted for its exploration and robustness capabilities -- is usually motivated from a probabilistic perspective, the use of deep probabilistic models has not gained much traction in practice due to their inherent complexity. In this work, we propose the adoption of latent variable policies within the MaxEnt framework, which we show can provably approximate any policy distribution, and additionally, naturally emerges under the use of world models with a latent belief state. We discuss why latent variable policies are difficult to train, how naive approaches can fail, then subsequently introduce a series of improvements centered around low-cost marginalization of the latent state, allowing us to make full use of the latent state at minimal additional cost. We instantiate our method under the actor-critic framework, marginalizing both the actor and critic. The resulting algorithm, referred to as Stochastic Marginal Actor-Critic (SMAC), is simple yet effective. We experimentally validate our method on continuous control tasks, showing that effective marginalization can lead to better exploration and more robust training.