 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Surprising Difficulty of Search in Model-Based Reinforcement Learning
Jan 29, 2026This paper investigates search in model-based reinforcement learning (RL). Conventional wisdom holds that long-term predictions and compounding errors are the primary obstacles for model-based RL. We challenge this view, showing that search is not a plug-and-play replacement for a learned policy. Surprisingly, we find that search can harm performance even when the model is highly accurate. Instead, we show that mitigating distribution shift matters more than improving model or value function accuracy. Building on this insight, we identify key techniques for enabling effective search, achieving state-of-the-art performance across multiple popular benchmark domains.
Safety Alignment of LMs via Non-cooperative Games
Dec 23, 2025Ensuring the safety of language models (LMs) while maintaining their usefulness remains a critical challenge in AI alignment. Current approaches rely on sequential adversarial training: generating adversarial prompts and fine-tuning LMs to defend against them. We introduce a different paradigm: framing safety alignment as a non-zero-sum game between an Attacker LM and a Defender LM trained jointly via online reinforcement learning. Each LM continuously adapts to the other's evolving strategies, driving iterative improvement. Our method uses a preference-based reward signal derived from pairwise comparisons instead of point-wise scores, providing more robust supervision and potentially reducing reward hacking. Our RL recipe, AdvGame, shifts the Pareto frontier of safety and utility, yielding a Defender LM that is simultaneously more helpful and more resilient to adversarial attacks. In addition, the resulting Attacker LM converges into a strong, general-purpose red-teaming agent that can be directly deployed to probe arbitrary target models.
BaNEL: Exploration Posteriors for Generative Modeling Using Only Negative Rewards
Oct 10, 2025Today's generative models thrive with large amounts of supervised data and informative reward functions characterizing the quality of the generation. They work under the assumptions that the supervised data provides knowledge to pre-train the model, and the reward function provides dense information about how to further improve the generation quality and correctness. However, in the hardest instances of important problems, two problems arise: (1) the base generative model attains a near-zero reward signal, and (2) calls to the reward oracle are expensive. This setting poses a fundamentally different learning challenge than standard reward-based post-training. To address this, we propose BaNEL (Bayesian Negative Evidence Learning), an algorithm that post-trains the model using failed attempts only, while minimizing the number of reward evaluations (NREs). Our method is based on the idea that the problem of learning regularities underlying failures can be cast as another, in-loop generative modeling problem. We then leverage this model to assess whether new data resembles previously seen failures and steer the generation away from them. We show that BaNEL can improve model performance without observing a single successful sample on several sparse-reward tasks, outperforming existing novelty-bonus approaches by up to several orders of magnitude in success rate, while using fewer reward evaluations.
Adjoint Sampling: Highly Scalable Diffusion Samplers via Adjoint Matching
Apr 16, 2025We introduce Adjoint Sampling, a highly scalable and efficient algorithm for learning diffusion processes that sample from unnormalized densities, or energy functions. It is the first on-policy approach that allows significantly more gradient updates than the number of energy evaluations and model samples, allowing us to scale to much larger problem settings than previously explored by similar methods. Our framework is theoretically grounded in stochastic optimal control and shares the same theoretical guarantees as Adjoint Matching, being able to train without the need for corrective measures that push samples towards the target distribution. We show how to incorporate key symmetries, as well as periodic boundary conditions, for modeling molecules in both cartesian and torsional coordinates. We demonstrate the effectiveness of our approach through extensive experiments on classical energy functions, and further scale up to neural network-based energy models where we perform amortized conformer generation across many molecular systems. To encourage further research in developing highly scalable sampling methods, we plan to open source these challenging benchmarks, where successful methods can directly impact progress in computational chemistry.
AdvPrefix: An Objective for Nuanced LLM Jailbreaks
Dec 13, 2024



Many jailbreak attacks on large language models (LLMs) rely on a common objective: making the model respond with the prefix "Sure, here is (harmful request)". While straightforward, this objective has two limitations: limited control over model behaviors, often resulting in incomplete or unrealistic responses, and a rigid format that hinders optimization. To address these limitations, we introduce AdvPrefix, a new prefix-forcing objective that enables more nuanced control over model behavior while being easy to optimize. Our objective leverages model-dependent prefixes, automatically selected based on two criteria: high prefilling attack success rates and low negative log-likelihood. It can further simplify optimization by using multiple prefixes for a single user request. AdvPrefix can integrate seamlessly into existing jailbreak attacks to improve their performance for free. For example, simply replacing GCG attack's target prefixes with ours on Llama-3 improves nuanced attack success rates from 14% to 80%, suggesting that current alignment struggles to generalize to unseen prefixes. Our work demonstrates the importance of jailbreak objectives in achieving nuanced jailbreaks.
Wasserstein Flow Matching: Generative modeling over families of distributions
Nov 01, 2024



Generative modeling typically concerns the transport of a single source distribution to a single target distribution by learning (i.e., regressing onto) simple probability flows. However, in modern data-driven fields such as computer graphics and single-cell genomics, samples (say, point-clouds) from datasets can themselves be viewed as distributions (as, say, discrete measures). In these settings, the standard generative modeling paradigm of flow matching would ignore the relevant geometry of the samples. To remedy this, we propose \emph{Wasserstein flow matching} (WFM), which appropriately lifts flow matching onto families of distributions by appealing to the Riemannian nature of the Wasserstein geometry. Our algorithm leverages theoretical and computational advances in (entropic) optimal transport, as well as the attention mechanism in our neural network architecture. We present two novel algorithmic contributions. First, we demonstrate how to perform generative modeling over Gaussian distributions, where we generate representations of granular cell states from single-cell genomics data. Secondly, we show that WFM can learn flows between high-dimensional and variable sized point-clouds and synthesize cellular microenvironments from spatial transcriptomics datasets. Code is available at [WassersteinFlowMatching](https://github.com/DoronHav/WassersteinFlowMatching).
Online Intrinsic Rewards for Decision Making Agents from Large Language Model Feedback
Oct 30, 2024Automatically synthesizing dense rewards from natural language descriptions is a promising paradigm in reinforcement learning (RL), with applications to sparse reward problems, open-ended exploration, and hierarchical skill design. Recent works have made promising steps by exploiting the prior knowledge of large language models (LLMs). However, these approaches suffer from important limitations: they are either not scalable to problems requiring billions of environment samples; or are limited to reward functions expressible by compact code, which may require source code and have difficulty capturing nuanced semantics; or require a diverse offline dataset, which may not exist or be impossible to collect. In this work, we address these limitations through a combination of algorithmic and systems-level contributions. We propose ONI, a distributed architecture that simultaneously learns an RL policy and an intrinsic reward function using LLM feedback. Our approach annotates the agent's collected experience via an asynchronous LLM server, which is then distilled into an intrinsic reward model. We explore a range of algorithmic choices for reward modeling with varying complexity, including hashing, classification, and ranking models. By studying their relative tradeoffs, we shed light on questions regarding intrinsic reward design for sparse reward problems. Our approach achieves state-of-the-art performance across a range of challenging, sparse reward tasks from the NetHack Learning Environment in a simple unified process, solely using the agent's gathered experience, without requiring external datasets nor source code. We make our code available at \url{URL} (coming soon).
To the Globe (TTG): Towards Language-Driven Guaranteed Travel Planning
Oct 21, 2024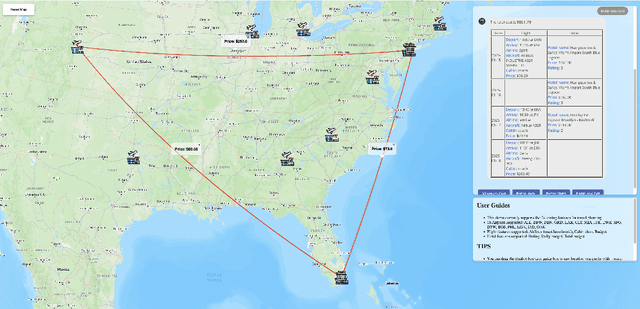
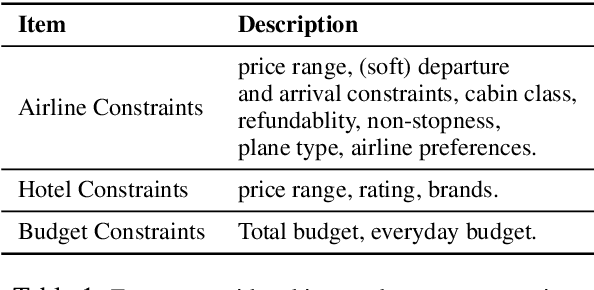
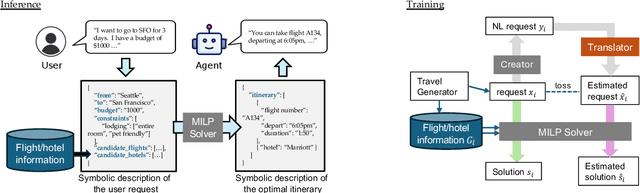

Travel planning is a challenging and time-consuming task that aims to find an itinerary which satisfies multiple, interdependent constraints regarding flights, accommodations, attractions, and other travel arrangements. In this paper, we propose To the Globe (TTG), a real-time demo system that takes natural language requests from users, translates it to symbolic form via a fine-tuned Large Language Model, and produces optimal travel itineraries with Mixed Integer Linear Programming solvers. The overall system takes ~5 seconds to reply to the user request with guaranteed itineraries. To train TTG, we develop a synthetic data pipeline that generates user requests, flight and hotel information in symbolic form without human annotations, based on the statistics of real-world datasets, and fine-tune an LLM to translate NL user requests to their symbolic form, which is sent to the symbolic solver to compute optimal itineraries. Our NL-symbolic translation achieves ~91% exact match in a backtranslation metric (i.e., whether the estimated symbolic form of generated natural language matches the groundtruth), and its returned itineraries have a ratio of 0.979 compared to the optimal cost of the ground truth user request. When evaluated by users, TTG achieves consistently high Net Promoter Scores (NPS) of 35-40% on generated itinerary.
Exact Byte-Level Probabilities from Tokenized Language Models for FIM-Tasks and Model Ensembles
Oct 11, 2024



Tokenization is associated with many poorly understood shortcomings in language models (LMs), yet remains an important component for long sequence scaling purposes. This work studies how tokenization impacts model performance by analyzing and comparing the stochastic behavior of tokenized models with their byte-level, or token-free, counterparts. We discover that, even when the two models are statistically equivalent, their predictive distributions over the next byte can be substantially different, a phenomenon we term as "tokenization bias''. To fully characterize this phenomenon, we introduce the Byte-Token Representation Lemma, a framework that establishes a mapping between the learned token distribution and its equivalent byte-level distribution. From this result, we develop a next-byte sampling algorithm that eliminates tokenization bias without requiring further training or optimization. In other words, this enables zero-shot conversion of tokenized LMs into statistically equivalent token-free ones. We demonstrate its broad applicability with two use cases: fill-in-the-middle (FIM) tasks and model ensembles. In FIM tasks where input prompts may terminate mid-token, leading to out-of-distribution tokenization, our method mitigates performance degradation and achieves an approximately 18% improvement in FIM coding benchmarks, consistently outperforming the standard token healing fix. For model ensembles where each model employs a distinct vocabulary, our approach enables seamless integration, resulting in improved performance (up to 3.7%) over individual models across various standard baselines in reasoning, knowledge, and coding.
Meta Flow Matching: Integrating Vector Fields on the Wasserstein Manifold
Aug 26, 2024



Numerous biological and physical processes can be modeled as systems of interacting entities evolving continuously over time, e.g. the dynamics of communicating cells or physical particles. Learning the dynamics of such systems is essential for predicting the temporal evolution of populations across novel samples and unseen environments. Flow-based models allow for learning these dynamics at the population level - they model the evolution of the entire distribution of samples. However, current flow-based models are limited to a single initial population and a set of predefined conditions which describe different dynamics. We argue that multiple processes in natural sciences have to be represented as vector fields on the Wasserstein manifold of probability densities. That is, the change of the population at any moment in time depends on the population itself due to the interactions between samples. In particular, this is crucial for personalized medicine where the development of diseases and their respective treatment response depends on the microenvironment of cells specific to each patient. We propose Meta Flow Matching (MFM), a practical approach to integrating along these vector fields on the Wasserstein manifold by amortizing the flow model over the initial populations. Namely, we embed the population of samples using a Graph Neural Network (GNN) and use these embeddings to train a Flow Matching model. This gives MFM the ability to generalize over the initial distributions unlike previously proposed methods. We demonstrate the ability of MFM to improve prediction of individual treatment responses on a large scale multi-patient single-cell drug screen dataset.