 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Tokenizer Likelihood Scoring Algorithms for Language Model Distillation
Dec 16, 2025Computing next-token likelihood ratios between two language models (LMs) is a standard task in training paradigms such as knowledge distillation. Since this requires both models to share the same probability space, it becomes challenging when the teacher and student LMs use different tokenizers, for instance, when edge-device deployment necessitates a smaller vocabulary size to lower memory overhead. In this work, we address this vocabulary misalignment problem by uncovering an implicit recursive structure in the commonly deployed Byte-Pair Encoding (BPE) algorithm and utilizing it to create a probabilistic framework for cross-tokenizer likelihood scoring. Our method enables sequence likelihood evaluation for vocabularies different from the teacher model native tokenizer, addressing two specific scenarios: when the student vocabulary is a subset of the teacher vocabulary, and the general case where it is arbitrary. In the subset regime, our framework computes exact likelihoods and provides next-token probabilities for sequential sampling with only O(1) model evaluations per token. When used for distillation, this yields up to a 12% reduction in memory footprint for the Qwen2.5-1.5B model while also improving baseline performance up to 4% on the evaluated tasks. For the general case, we introduce a rigorous lossless procedure that leverages BPE recursive structure, complemented by a fast approximation that keeps large-vocabulary settings practical. Applied to distillation for mathematical reasoning, our approach improves GSM8K accuracy by more than 2% over the current state of the art.
Gumbel-max List Sampling for Distribution Coupling with Multiple Samples
Jun 10, 2025We study a relaxation of the problem of coupling probability distributions -- a list of samples is generated from one distribution and an accept is declared if any one of these samples is identical to the sample generated from the other distribution. We propose a novel method for generating samples, which extends the Gumbel-max sampling suggested in Daliri et al. (arXiv:2408.07978) for coupling probability distributions. We also establish a corresponding lower bound on the acceptance probability, which we call the list matching lemma. We next discuss two applications of our setup. First, we develop a new mechanism for multi-draft speculative sampling that is simple to implement and achieves performance competitive with baselines such as SpecTr and SpecInfer across a range of language tasks. Our method also guarantees a certain degree of drafter invariance with respect to the output tokens which is not supported by existing schemes. We also provide a theoretical lower bound on the token level acceptance probability. As our second application, we consider distributed lossy compression with side information in a setting where a source sample is compressed and available to multiple decoders, each with independent side information. We propose a compression technique that is based on our generalization of Gumbel-max sampling and show that it provides significant gains in experiments involving synthetic Gaussian sources and the MNIST image dataset.
List-Level Distribution Coupling with Applications to Speculative Decoding and Lossy Compression
Jun 05, 2025We study a relaxation of the problem of coupling probability distributions -- a list of samples is generated from one distribution and an accept is declared if any one of these samples is identical to the sample generated from the other distribution. We propose a novel method for generating samples, which extends the Gumbel-max sampling suggested in Daliri et al. (arXiv:2408.07978) for coupling probability distributions. We also establish a corresponding lower bound on the acceptance probability, which we call the list matching lemma. We next discuss two applications of our setup. First, we develop a new mechanism for multi-draft speculative sampling that is simple to implement and achieves performance competitive with baselines such as SpecTr and SpecInfer across a range of language tasks. Our method also guarantees a certain degree of drafter invariance with respect to the output tokens which is not supported by existing schemes. We also provide a theoretical lower bound on the token level acceptance probability. As our second application, we consider distributed lossy compression with side information in a setting where a source sample is compressed and available to multiple decoders, each with independent side information. We propose a compression technique that is based on our generalization of Gumbel-max sampling and show that it provides significant gains in experiments involving synthetic Gaussian sources and the MNIST image dataset.
Exact Byte-Level Probabilities from Tokenized Language Models for FIM-Tasks and Model Ensembles
Oct 11, 2024



Tokenization is associated with many poorly understood shortcomings in language models (LMs), yet remains an important component for long sequence scaling purposes. This work studies how tokenization impacts model performance by analyzing and comparing the stochastic behavior of tokenized models with their byte-level, or token-free, counterparts. We discover that, even when the two models are statistically equivalent, their predictive distributions over the next byte can be substantially different, a phenomenon we term as "tokenization bias''. To fully characterize this phenomenon, we introduce the Byte-Token Representation Lemma, a framework that establishes a mapping between the learned token distribution and its equivalent byte-level distribution. From this result, we develop a next-byte sampling algorithm that eliminates tokenization bias without requiring further training or optimization. In other words, this enables zero-shot conversion of tokenized LMs into statistically equivalent token-free ones. We demonstrate its broad applicability with two use cases: fill-in-the-middle (FIM) tasks and model ensembles. In FIM tasks where input prompts may terminate mid-token, leading to out-of-distribution tokenization, our method mitigates performance degradation and achieves an approximately 18% improvement in FIM coding benchmarks, consistently outperforming the standard token healing fix. For model ensembles where each model employs a distinct vocabulary, our approach enables seamless integration, resulting in improved performance (up to 3.7%) over individual models across various standard baselines in reasoning, knowledge, and coding.
Understanding and Mitigating Tokenization Bias in Language Models
Jun 24, 2024


State-of-the-art language models are autoregressive and operate on subword units known as tokens. Specifically, one must encode the conditioning string into a list of tokens before passing to the language models for next-token prediction. We show that, for encoding schemes such as maximum prefix matching, tokenization induces a sampling bias that cannot be mitigated with more training or data. To counter this universal problem, we propose a novel algorithm to obtain unbiased estimates from a model that was trained on tokenized data. Our method does not require finetuning the model, and its complexity, defined as the number of model runs, scales linearly with the sequence length. As a consequence, we show that one can simulate token-free behavior from a tokenized language model. We empirically verify the correctness of our method through a Markov-chain setup, where it accurately recovers the transition probabilities, as opposed to the conventional method of directly prompting tokens into the language model.
On the Choice of Perception Loss Function for Learned Video Compression
May 30, 2023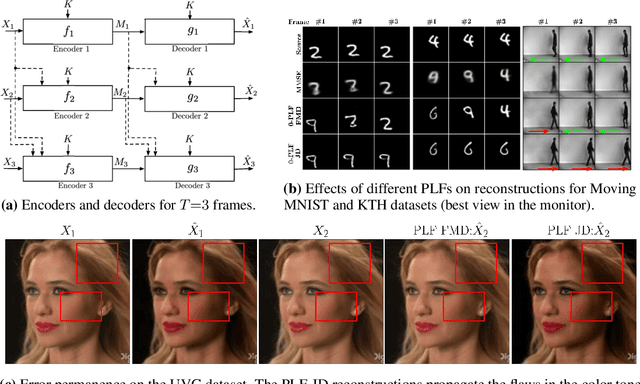
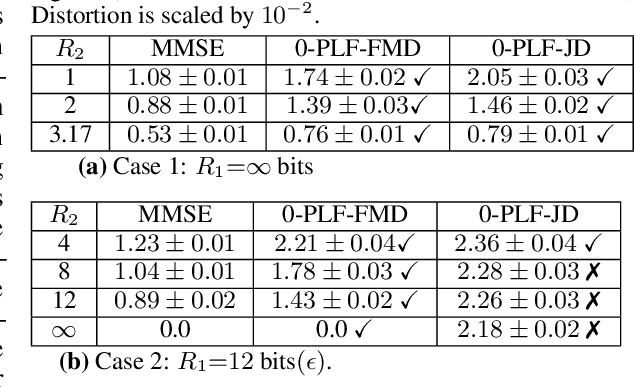
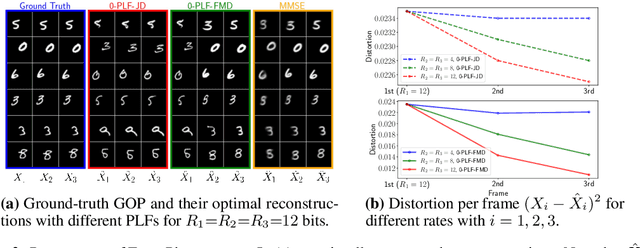

We study causal, low-latency, sequential video compression when the output is subjected to both a mean squared-error (MSE) distortion loss as well as a perception loss to target realism. Motivated by prior approaches, we consider two different perception loss functions (PLFs). The first, PLF-JD, considers the joint distribution (JD) of all the video frames up to the current one, while the second metric, PLF-FMD, considers the framewise marginal distributions (FMD) between the source and reconstruction. Using information theoretic analysis and deep-learning based experiments, we demonstrate that the choice of PLF can have a significant effect on the reconstruction, especially at low-bit rates. In particular, while the reconstruction based on PLF-JD can better preserve the temporal correlation across frames, it also imposes a significant penalty in distortion compared to PLF-FMD and further makes it more difficult to recover from errors made in the earlier output frames. Although the choice of PLF decisively affects reconstruction quality, we also demonstrate that it may not be essential to commit to a particular PLF during encoding and the choice of PLF can be delegated to the decoder. In particular, encoded representations generated by training a system to minimize the MSE (without requiring either PLF) can be {\em near universal} and can generate close to optimal reconstructions for either choice of PLF at the decoder. We validate our results using (one-shot) information-theoretic analysis, detailed study of the rate-distortion-perception tradeoff of the Gauss-Markov source model as well as deep-learning based experiments on moving MNIST and KTH datasets.
Adversarial Imaging Pipelines
Feb 19, 2021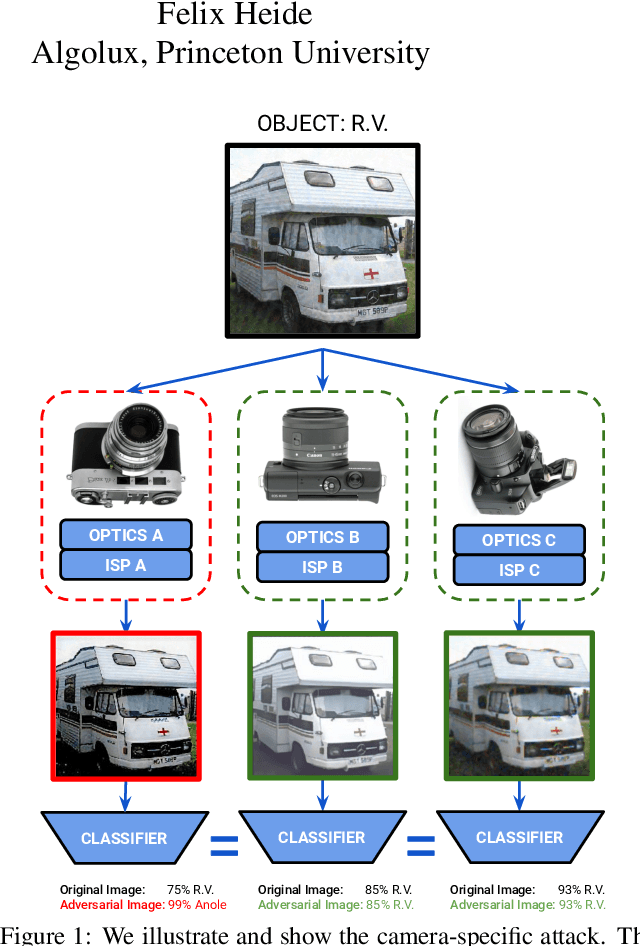
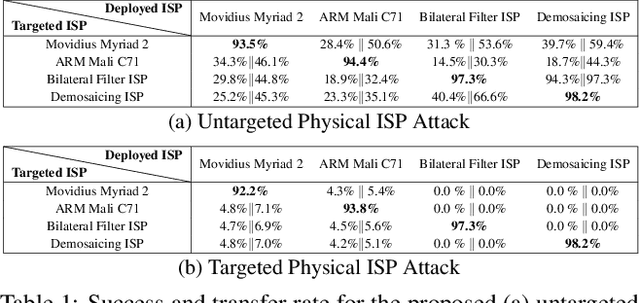
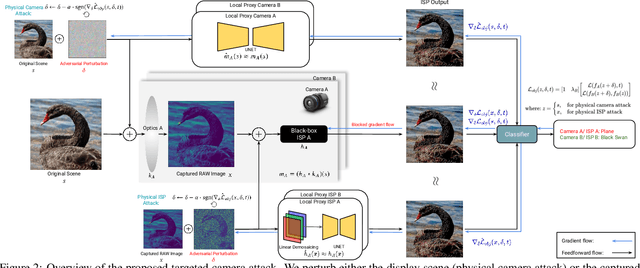

Adversarial attacks play an essential role in understanding deep neural network predictions and improving their robustness. Existing attack methods aim to deceive convolutional neural network (CNN)-based classifiers by manipulating RGB images that are fed directly to the classifiers. However, these approaches typically neglect the influence of the camera optics and image processing pipeline (ISP) that produce the network inputs. ISPs transform RAW measurements to RGB images and traditionally are assumed to preserve adversarial patterns. However, these low-level pipelines can, in fact, destroy, introduce or amplify adversarial patterns that can deceive a downstream detector. As a result, optimized patterns can become adversarial for the classifier after being transformed by a certain camera ISP and optic but not for others. In this work, we examine and develop such an attack that deceives a specific camera ISP while leaving others intact, using the same down-stream classifier. We frame camera-specific attacks as a multi-task optimization problem, relying on a differentiable approximation for the ISP itself. We validate the proposed method using recent state-of-the-art automotive hardware ISPs, achieving 92% fooling rate when attacking a specific ISP. We demonstrate physical optics attacks with 90% fooling rate for a specific camera lenses.
Seeing Around Street Corners: Non-Line-of-Sight Detection and Tracking In-the-Wild Using Doppler Radar
Dec 13, 2019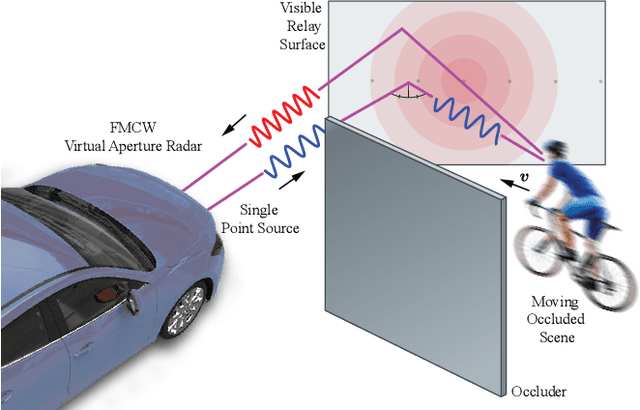
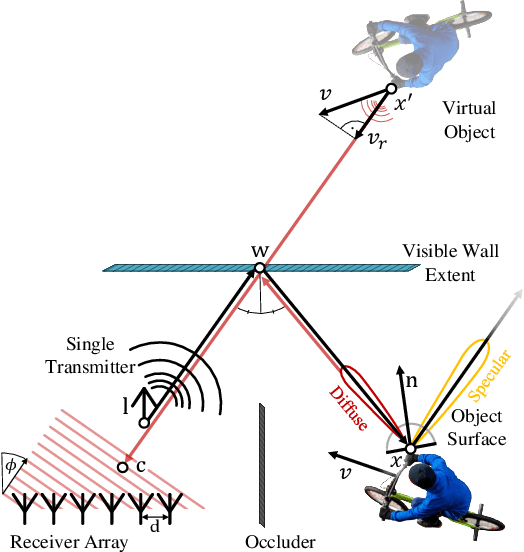

Conventional sensor systems record information about directly visible objects, whereas occluded scene components are considered lost in the measurement process. Nonline-of-sight (NLOS) methods try to recover such hidden objects from their indirect reflections - faint signal components, traditionally treated as measurement noise. Existing NLOS approaches struggle to record these low-signal components outside the lab, and do not scale to large-scale outdoor scenes and high-speed motion, typical in automotive scenarios. Especially optical NLOS is fundamentally limited by the quartic intensity falloff of diffuse indirect reflections. In this work, we depart from visible-wavelength approaches and demonstrate detection, classification, and tracking of hidden objects in large-scale dynamic scenes using a Doppler radar which can be foreseen as a low-cost serial product in the near future. To untangle noisy indirect and direct reflections, we learn from temporal sequences of Doppler velocity and position measurements, which we fuse in a joint NLOS detection and tracking network over time. We validate the approach on in-the-wild automotive scenes, including sequences of parked cars or house facades as indirect reflectors, and demonstrate low-cost, real-time NLOS in dynamic automotive environments.
Detecting Out-of-Distribution Inputs in Deep Neural Networks Using an Early-Layer Output
Oct 23, 2019

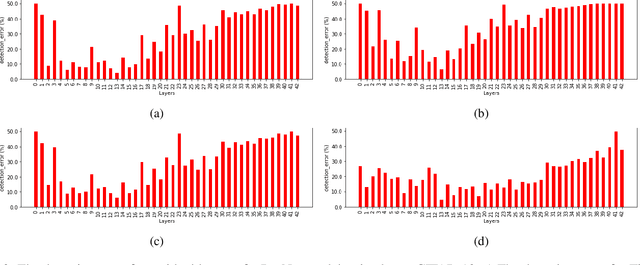
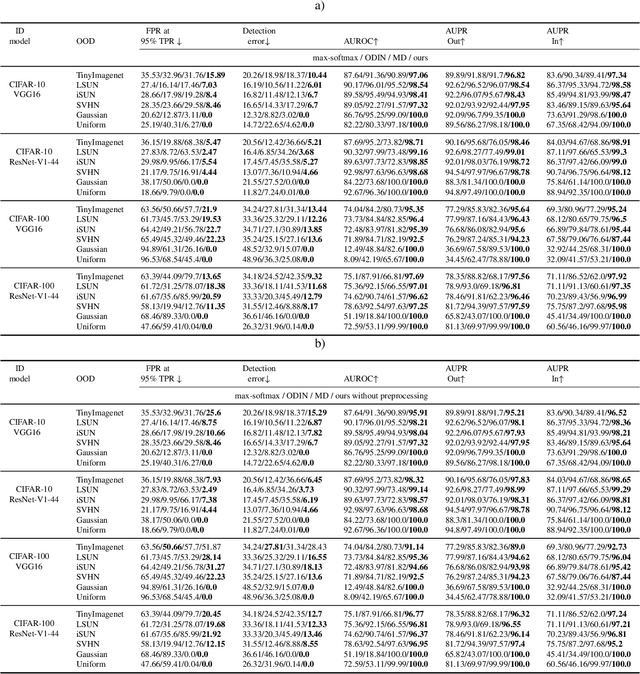
Deep neural networks achieve superior performance in challenging tasks such as image classification. However, deep classifiers tend to incorrectly classify out-of-distribution (OOD) inputs, which are inputs that do not belong to the classifier training distribution. Several approaches have been proposed to detect OOD inputs, but the detection task is still an ongoing challenge. In this paper, we propose a new OOD detection approach that can be easily applied to an existing classifier and does not need to have access to OOD samples. The detector is a one-class classifier trained on the output of an early layer of the original classifier fed with its original training set. We apply our approach to several low- and high-dimensional datasets and compare it to the state-of-the-art detection approaches. Our approach achieves substantially better results over multiple metrics.
Analysis of Confident-Classifiers for Out-of-distribution Detection
Apr 27, 2019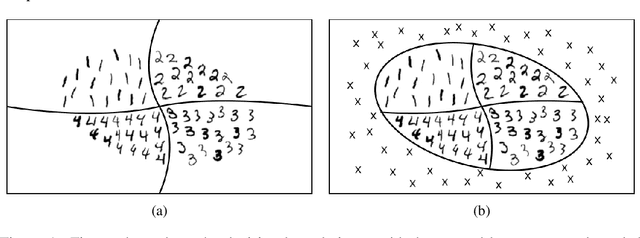
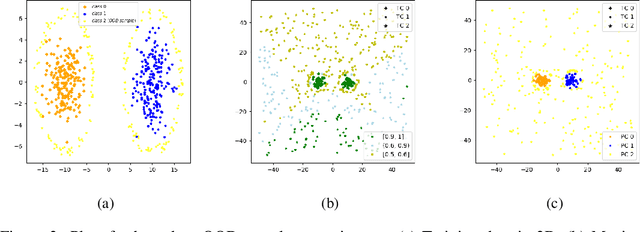
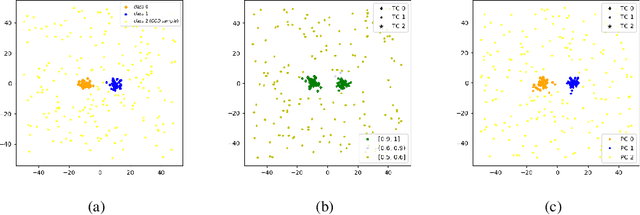
Discriminatively trained neural classifiers can be trusted, only when the input data comes from the training distribution (in-distribution). Therefore, detecting out-of-distribution (OOD) samples is very important to avoid classification errors. In the context of OOD detection for image classification, one of the recent approaches proposes training a classifier called "confident-classifier" by minimizing the standard cross-entropy loss on in-distribution samples and minimizing the KL divergence between the predictive distribution of OOD samples in the low-density regions of in-distribution and the uniform distribution (maximizing the entropy of the outputs). Thus, the samples could be detected as OOD if they have low confidence or high entropy. In this paper, we analyze this setting both theoretically and experimentally. We conclude that the resulting confident-classifier still yields arbitrarily high confidence for OOD samples far away from the in-distribution. We instead suggest training a classifier by adding an explicit "reject" class for OOD samples.