 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet Block Decoding is a Language Model Inference Accelerator
Sep 04, 2025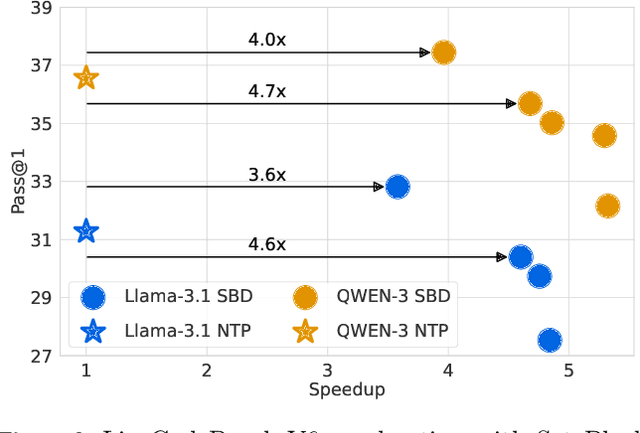
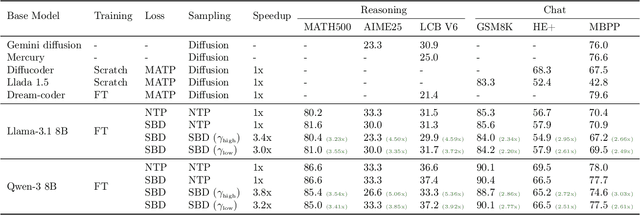
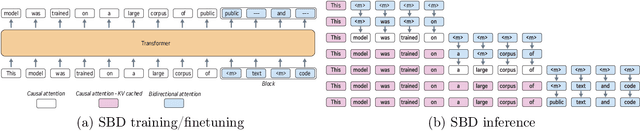

Autoregressive next token prediction language models offer powerful capabilities but face significant challenges in practical deployment due to the high computational and memory costs of inference, particularly during the decoding stage. We introduce Set Block Decoding (SBD), a simple and flexible paradigm that accelerates generation by integrating standard next token prediction (NTP) and masked token prediction (MATP) within a single architecture. SBD allows the model to sample multiple, not necessarily consecutive, future tokens in parallel, a key distinction from previous acceleration methods. This flexibility allows the use of advanced solvers from the discrete diffusion literature, offering significant speedups without sacrificing accuracy. SBD requires no architectural changes or extra training hyperparameters, maintains compatibility with exact KV-caching, and can be implemented by fine-tuning existing next token prediction models. By fine-tuning Llama-3.1 8B and Qwen-3 8B, we demonstrate that SBD enables a 3-5x reduction in the number of forward passes required for generation while achieving same performance as equivalent NTP training.
Edit Flows: Flow Matching with Edit Operations
Jun 10, 2025Autoregressive generative models naturally generate variable-length sequences, while non-autoregressive models struggle, often imposing rigid, token-wise structures. We propose Edit Flows, a non-autoregressive model that overcomes these limitations by defining a discrete flow over sequences through edit operations-insertions, deletions, and substitutions. By modeling these operations within a Continuous-time Markov Chain over the sequence space, Edit Flows enable flexible, position-relative generation that aligns more closely with the structure of sequence data. Our training method leverages an expanded state space with auxiliary variables, making the learning process efficient and tractable. Empirical results show that Edit Flows outperforms both autoregressive and mask models on image captioning and significantly outperforms the mask construction in text and code generation.
Diverse Concept Proposals for Concept Bottleneck Models
Dec 24, 2024



Concept bottleneck models are interpretable predictive models that are often used in domains where model trust is a key priority, such as healthcare. They identify a small number of human-interpretable concepts in the data, which they then use to make predictions. Learning relevant concepts from data proves to be a challenging task. The most predictive concepts may not align with expert intuition, thus, failing interpretability with no recourse. Our proposed approach identifies a number of predictive concepts that explain the data. By offering multiple alternative explanations, we allow the human expert to choose the one that best aligns with their expectation. To demonstrate our method, we show that it is able discover all possible concept representations on a synthetic dataset. On EHR data, our model was able to identify 4 out of the 5 pre-defined concepts without supervision.
EvalGIM: A Library for Evaluating Generative Image Models
Dec 18, 2024



As the use of text-to-image generative models increases, so does the adoption of automatic benchmarking methods used in their evaluation. However, while metrics and datasets abound, there are few unified benchmarking libraries that provide a framework for performing evaluations across many datasets and metrics. Furthermore, the rapid introduction of increasingly robust benchmarking methods requires that evaluation libraries remain flexible to new datasets and metrics. Finally, there remains a gap in synthesizing evaluations in order to deliver actionable takeaways about model performance. To enable unified, flexible, and actionable evaluations, we introduce EvalGIM (pronounced ''EvalGym''), a library for evaluating generative image models. EvalGIM contains broad support for datasets and metrics used to measure quality, diversity, and consistency of text-to-image generative models. In addition, EvalGIM is designed with flexibility for user customization as a top priority and contains a structure that allows plug-and-play additions of new datasets and metrics. To enable actionable evaluation insights, we introduce ''Evaluation Exercises'' that highlight takeaways for specific evaluation questions. The Evaluation Exercises contain easy-to-use and reproducible implementations of two state-of-the-art evaluation methods of text-to-image generative models: consistency-diversity-realism Pareto Fronts and disaggregated measurements of performance disparities across groups. EvalGIM also contains Evaluation Exercises that introduce two new analysis methods for text-to-image generative models: robustness analyses of model rankings and balanced evaluations across different prompt styles. We encourage text-to-image model exploration with EvalGIM and invite contributions at https://github.com/facebookresearch/EvalGIM/.
Flow Matching Guide and Code
Dec 09, 2024Flow Matching (FM) is a recent framework for generative modeling that has achieved state-of-the-art performance across various domains, including image, video, audio, speech, and biological structures. This guide offers a comprehensive and self-contained review of FM, covering its mathematical foundations, design choices, and extensions. By also providing a PyTorch package featuring relevant examples (e.g., image and text generation), this work aims to serve as a resource for both novice and experienced researchers interested in understanding, applying and further developing FM.
Flow Matching with General Discrete Paths: A Kinetic-Optimal Perspective
Dec 04, 2024The design space of discrete-space diffusion or flow generative models are significantly less well-understood than their continuous-space counterparts, with many works focusing only on a simple masked construction. In this work, we aim to take a holistic approach to the construction of discrete generative models based on continuous-time Markov chains, and for the first time, allow the use of arbitrary discrete probability paths, or colloquially, corruption processes. Through the lens of optimizing the symmetric kinetic energy, we propose velocity formulas that can be applied to any given probability path, completely decoupling the probability and velocity, and giving the user the freedom to specify any desirable probability path based on expert knowledge specific to the data domain. Furthermore, we find that a special construction of mixture probability paths optimizes the symmetric kinetic energy for the discrete case. We empirically validate the usefulness of this new design space across multiple modalities: text generation, inorganic material generation, and image generation. We find that we can outperform the mask construction even in text with kinetic-optimal mixture paths, while we can make use of domain-specific constructions of the probability path over the visual domain.
Boosting Latent Diffusion with Perceptual Objectives
Nov 06, 2024Latent diffusion models (LDMs) power state-of-the-art high-resolution generative image models. LDMs learn the data distribution in the latent space of an autoencoder (AE) and produce images by mapping the generated latents into RGB image space using the AE decoder. While this approach allows for efficient model training and sampling, it induces a disconnect between the training of the diffusion model and the decoder, resulting in a loss of detail in the generated images. To remediate this disconnect, we propose to leverage the internal features of the decoder to define a latent perceptual loss (LPL). This loss encourages the models to create sharper and more realistic images. Our loss can be seamlessly integrated with common autoencoders used in latent diffusion models, and can be applied to different generative modeling paradigms such as DDPM with epsilon and velocity prediction, as well as flow matching. Extensive experiments with models trained on three datasets at 256 and 512 resolution show improved quantitative -- with boosts between 6% and 20% in FID -- and qualitative results when using our perceptual loss.
On Improved Conditioning Mechanisms and Pre-training Strategies for Diffusion Models
Nov 05, 2024Large-scale training of latent diffusion models (LDMs) has enabled unprecedented quality in image generation. However, the key components of the best performing LDM training recipes are oftentimes not available to the research community, preventing apple-to-apple comparisons and hindering the validation of progress in the field. In this work, we perform an in-depth study of LDM training recipes focusing on the performance of models and their training efficiency. To ensure apple-to-apple comparisons, we re-implement five previously published models with their corresponding recipes. Through our study, we explore the effects of (i)~the mechanisms used to condition the generative model on semantic information (e.g., text prompt) and control metadata (e.g., crop size, random flip flag, etc.) on the model performance, and (ii)~the transfer of the representations learned on smaller and lower-resolution datasets to larger ones on the training efficiency and model performance. We then propose a novel conditioning mechanism that disentangles semantic and control metadata conditionings and sets a new state-of-the-art in class-conditional generation on the ImageNet-1k dataset -- with FID improvements of 7% on 256 and 8% on 512 resolutions -- as well as text-to-image generation on the CC12M dataset -- with FID improvements of 8% on 256 and 23% on 512 resolution.
Generator Matching: Generative modeling with arbitrary Markov processes
Oct 27, 2024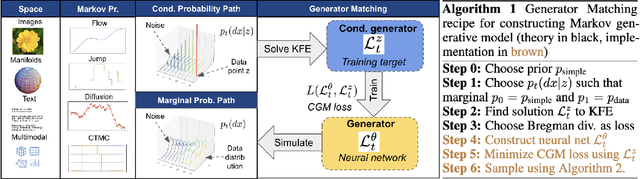

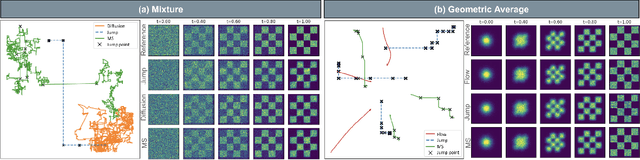
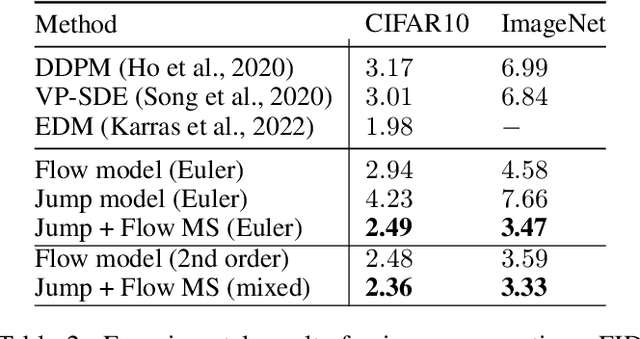
We introduce generator matching, a modality-agnostic framework for generative modeling using arbitrary Markov processes. Generators characterize the infinitesimal evolution of a Markov process, which we leverage for generative modeling in a similar vein to flow matching: we construct conditional generators which generate single data points, then learn to approximate the marginal generator which generates the full data distribution. We show that generator matching unifies various generative modeling methods, including diffusion models, flow matching and discrete diffusion models. Furthermore, it provides the foundation to expand the design space to new and unexplored Markov processes such as jump processes. Finally, generator matching enables the construction of superpositions of Markov generative processes and enables the construction of multimodal models in a rigorous manner. We empirically validate our method on protein and image structure generation, showing that superposition with a jump process improves image generation.
Exact Byte-Level Probabilities from Tokenized Language Models for FIM-Tasks and Model Ensembles
Oct 11, 2024



Tokenization is associated with many poorly understood shortcomings in language models (LMs), yet remains an important component for long sequence scaling purposes. This work studies how tokenization impacts model performance by analyzing and comparing the stochastic behavior of tokenized models with their byte-level, or token-free, counterparts. We discover that, even when the two models are statistically equivalent, their predictive distributions over the next byte can be substantially different, a phenomenon we term as "tokenization bias''. To fully characterize this phenomenon, we introduce the Byte-Token Representation Lemma, a framework that establishes a mapping between the learned token distribution and its equivalent byte-level distribution. From this result, we develop a next-byte sampling algorithm that eliminates tokenization bias without requiring further training or optimization. In other words, this enables zero-shot conversion of tokenized LMs into statistically equivalent token-free ones. We demonstrate its broad applicability with two use cases: fill-in-the-middle (FIM) tasks and model ensembles. In FIM tasks where input prompts may terminate mid-token, leading to out-of-distribution tokenization, our method mitigates performance degradation and achieves an approximately 18% improvement in FIM coding benchmarks, consistently outperforming the standard token healing fix. For model ensembles where each model employs a distinct vocabulary, our approach enables seamless integration, resulting in improved performance (up to 3.7%) over individual models across various standard baselines in reasoning, knowledge, and coding.