 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Scheduling for Efficient Inference-Time Reasoning in Large Language Models
Feb 01, 2026Large language models (LLMs) achieve state-of-the-art accuracy on complex reasoning tasks by generating multiple chain-of-thought (CoT) traces, but using a fixed token budget per query leads to over-computation on easy inputs and under-computation on hard ones. We introduce Predictive Scheduling, a plug-and-play framework that pre-runs lightweight predictors, an MLP on intermediate transformer hidden states or a LoRA-fine-tuned classifier on raw question text, to estimate each query's optimal reasoning length or difficulty before any full generation. Our greedy batch allocator dynamically distributes a fixed total token budget across queries to maximize expected accuracy. On the GSM8K arithmetic benchmark, predictive scheduling yields up to 7.9 percentage points of absolute accuracy gain over uniform budgeting at identical token cost, closing over 50\% of the gap to an oracle with perfect foresight. A systematic layer-wise study reveals that middle layers (12 - 17) of the transformer carry the richest signals for size estimation. These results demonstrate that pre-run budget prediction enables fine-grained control of the compute-accuracy trade-off, offering a concrete path toward latency-sensitive, cost-efficient LLM deployments.
Evolutionary Prompt Optimization Discovers Emergent Multimodal Reasoning Strategies in Vision-Language Models
Mar 30, 2025
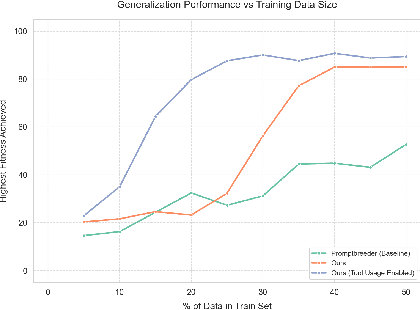


We present a framework for optimizing prompts in vision-language models to elicit multimodal reasoning without model retraining. Using an evolutionary algorithm to guide prompt updates downstream of visual tasks, our approach improves upon baseline prompt-updating algorithms, which lack evolution-style "survival of the fittest" iteration. Crucially, we find this approach enables the language model to independently discover progressive problem-solving techniques across several evolution generations. For example, the model reasons that to "break down" visually complex spatial tasks, making a tool call to a Python interpreter to perform tasks (such as cropping, image segmentation, or saturation changes) would improve performance significantly. Our experimentation shows that explicitly evoking this "tool calling" call, via system-level XML $...\texttt{<tool>} ... \texttt{</tool>}...$ tags, can effectively flag Python interpreter access for the same language model to generate relevant programs, generating advanced multimodal functionality. This functionality can be crystallized into a system-level prompt that induces improved performance at inference time, and our experimentation suggests up to $\approx 50\%$ relative improvement across select visual tasks. Downstream performance is trained and evaluated across subtasks from MathVista, M3CoT, and GeoBench-VLM datasets. Importantly, our approach shows that evolutionary prompt optimization guides language models towards self-reasoning discoveries, which result in improved zero-shot generalization across tasks.
Order Independence With Finetuning
Mar 30, 2025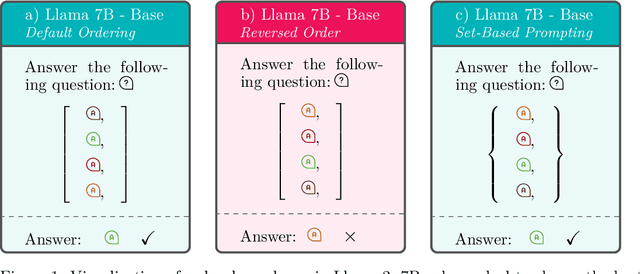

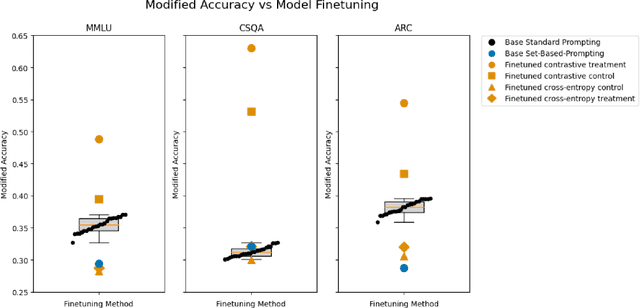

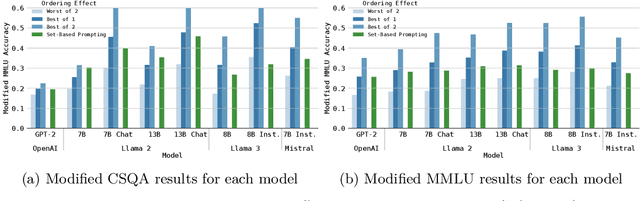
Large language models (LLMs) demonstrate remarkable performance on many NLP tasks, yet often exhibit order dependence: simply reordering semantically identical tokens (e.g., answer choices in multiple-choice questions) can lead to inconsistent predictions. Recent work proposes Set-Based Prompting (SBP) as a way to remove order information from designated token subsets, thereby mitigating positional biases. However, applying SBP on base models induces an out-of-distribution input format, which can degrade in-distribution performance. We introduce a fine-tuning strategy that integrates SBP into the training process, "pulling" these set-formatted prompts closer to the model's training manifold. We show that SBP can be incorporated into a model via fine-tuning. Our experiments on in-distribution (MMLU) and out-of-distribution (CSQA, ARC Challenge) multiple-choice tasks show that SBP fine-tuning significantly improves accuracy and robustness to answer-order permutations, all while preserving broader language modeling capabilities. We discuss the broader implications of order-invariant modeling and outline future directions for building fairer, more consistent LLMs.
Diverse Concept Proposals for Concept Bottleneck Models
Dec 24, 2024



Concept bottleneck models are interpretable predictive models that are often used in domains where model trust is a key priority, such as healthcare. They identify a small number of human-interpretable concepts in the data, which they then use to make predictions. Learning relevant concepts from data proves to be a challenging task. The most predictive concepts may not align with expert intuition, thus, failing interpretability with no recourse. Our proposed approach identifies a number of predictive concepts that explain the data. By offering multiple alternative explanations, we allow the human expert to choose the one that best aligns with their expectation. To demonstrate our method, we show that it is able discover all possible concept representations on a synthetic dataset. On EHR data, our model was able to identify 4 out of the 5 pre-defined concepts without supervision.
Set-Based Prompting: Provably Solving the Language Model Order Dependency Problem
Jun 12, 2024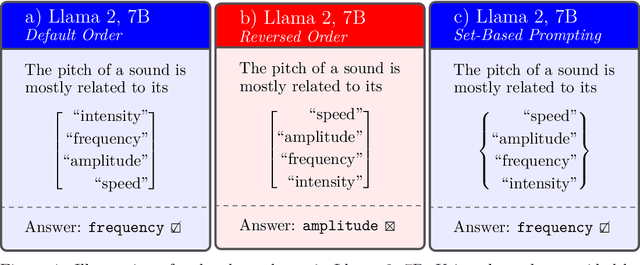


The development of generative language models that can create long and coherent textual outputs via autoregression has lead to a proliferation of uses and a corresponding sweep of analyses as researches work to determine the limitations of this new paradigm. Unlike humans, these 'Large Language Models' (LLMs) are highly sensitive to small changes in their inputs, leading to unwanted inconsistency in their behavior. One problematic inconsistency when LLMs are used to answer multiple-choice questions or analyze multiple inputs is order dependency: the output of an LLM can (and often does) change significantly when sub-sequences are swapped, despite both orderings being semantically identical. In this paper we present Set-Based Prompting, a technique that guarantees the output of an LLM will not have order dependence on a specified set of sub-sequences. We show that this method provably eliminates order dependency, and that it can be applied to any transformer-based LLM to enable text generation that is unaffected by re-orderings. Delving into the implications of our method, we show that, despite our inputs being out of distribution, the impact on expected accuracy is small, where the expectation is over the order of uniformly chosen shuffling of the candidate responses, and usually significantly less in practice. Thus, Set-Based Prompting can be used as a 'dropped-in' method on fully trained models. Finally, we discuss how our method's success suggests that other strong guarantees can be obtained on LLM performance via modifying the input representations.