 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Multi-Party Negotiation Games from Real Negotiation Data
Mar 14, 2026Many real-world multi-party negotiations unfold as sequences of binding, action-level commitments rather than a single final outcome. We introduce a benchmark for this under-studied regime featuring a configurable game generator that sweeps key structural properties such as incentive alignment, goal complexity, and payoff distribution. To evaluate decision-making, we test three value-function approximations - myopic reward, an optimistic upper bound, and a pessimistic lower bound - that act as biased lenses on deal evaluation. Through exact evaluation on small games and comparative evaluation on large, document-grounded instances derived from the Harvard Negotiation Challenge, we map the strategic regimes where each approximation succeeds or fails. We observe that different game structures demand different valuation strategies, motivating agents that learn robust state values and plan effectively over long horizons under binding commitments and terminal only rewards.
Federated ADMM from Bayesian Duality
Jun 16, 2025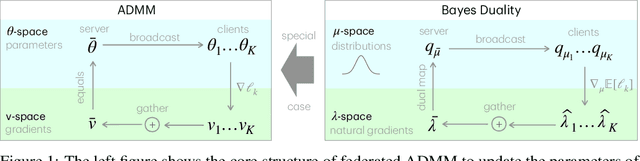
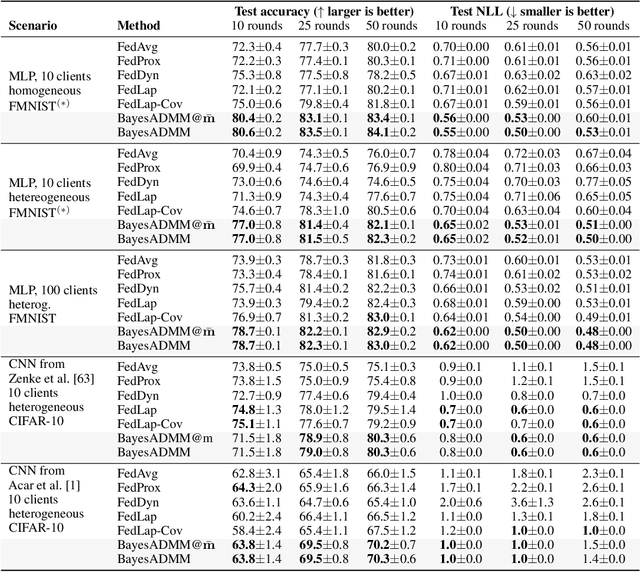

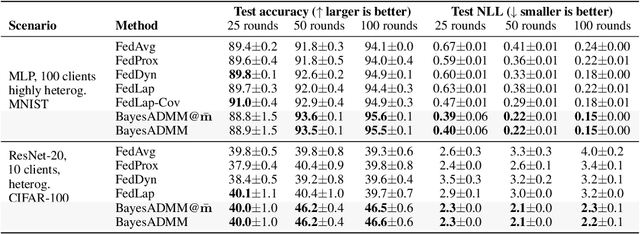
ADMM is a popular method for federated deep learning which originated in the 1970s and, even though many new variants of it have been proposed since then, its core algorithmic structure has remained unchanged. Here, we take a major departure from the old structure and present a fundamentally new way to derive and extend federated ADMM. We propose to use a structure called Bayesian Duality which exploits a duality of the posterior distributions obtained by solving a variational-Bayesian reformulation of the original problem. We show that this naturally recovers the original ADMM when isotropic Gaussian posteriors are used, and yields non-trivial extensions for other posterior forms. For instance, full-covariance Gaussians lead to Newton-like variants of ADMM, while diagonal covariances result in a cheap Adam-like variant. This is especially useful to handle heterogeneity in federated deep learning, giving up to 7% accuracy improvements over recent baselines. Our work opens a new Bayesian path to improve primal-dual methods.
Strategically Linked Decisions in Long-Term Planning and Reinforcement Learning
May 22, 2025Long-term planning, as in reinforcement learning (RL), involves finding strategies: actions that collectively work toward a goal rather than individually optimizing their immediate outcomes. As part of a strategy, some actions are taken at the expense of short-term benefit to enable future actions with even greater returns. These actions are only advantageous if followed up by the actions they facilitate, consequently, they would not have been taken if those follow-ups were not available. In this paper, we quantify such dependencies between planned actions with strategic link scores: the drop in the likelihood of one decision under the constraint that a follow-up decision is no longer available. We demonstrate the utility of strategic link scores through three practical applications: (i) explaining black-box RL agents by identifying strategically linked pairs among decisions they make, (ii) improving the worst-case performance of decision support systems by distinguishing whether recommended actions can be adopted as standalone improvements or whether they are strategically linked hence requiring a commitment to a broader strategy to be effective, and (iii) characterizing the planning processes of non-RL agents purely through interventions aimed at measuring strategic link scores - as an example, we consider a realistic traffic simulator and analyze through road closures the effective planning horizon of the emergent routing behavior of many drivers.
Connecting Federated ADMM to Bayes
Jan 28, 2025We provide new connections between two distinct federated learning approaches based on (i) ADMM and (ii) Variational Bayes (VB), and propose new variants by combining their complementary strengths. Specifically, we show that the dual variables in ADMM naturally emerge through the 'site' parameters used in VB with isotropic Gaussian covariances. Using this, we derive two versions of ADMM from VB that use flexible covariances and functional regularisation, respectively. Through numerical experiments, we validate the improvements obtained in performance. The work shows connection between two fields that are believed to be fundamentally different and combines them to improve federated learning.
Diverse Concept Proposals for Concept Bottleneck Models
Dec 24, 2024



Concept bottleneck models are interpretable predictive models that are often used in domains where model trust is a key priority, such as healthcare. They identify a small number of human-interpretable concepts in the data, which they then use to make predictions. Learning relevant concepts from data proves to be a challenging task. The most predictive concepts may not align with expert intuition, thus, failing interpretability with no recourse. Our proposed approach identifies a number of predictive concepts that explain the data. By offering multiple alternative explanations, we allow the human expert to choose the one that best aligns with their expectation. To demonstrate our method, we show that it is able discover all possible concept representations on a synthetic dataset. On EHR data, our model was able to identify 4 out of the 5 pre-defined concepts without supervision.
Shaping AI's Impact on Billions of Lives
Dec 03, 2024
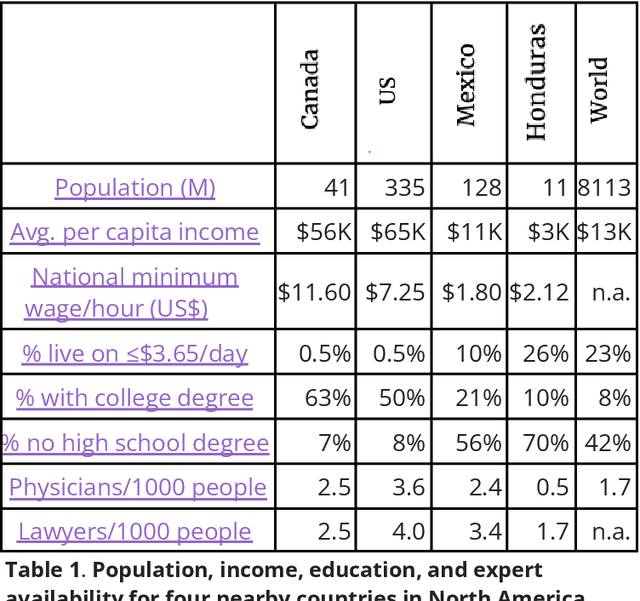
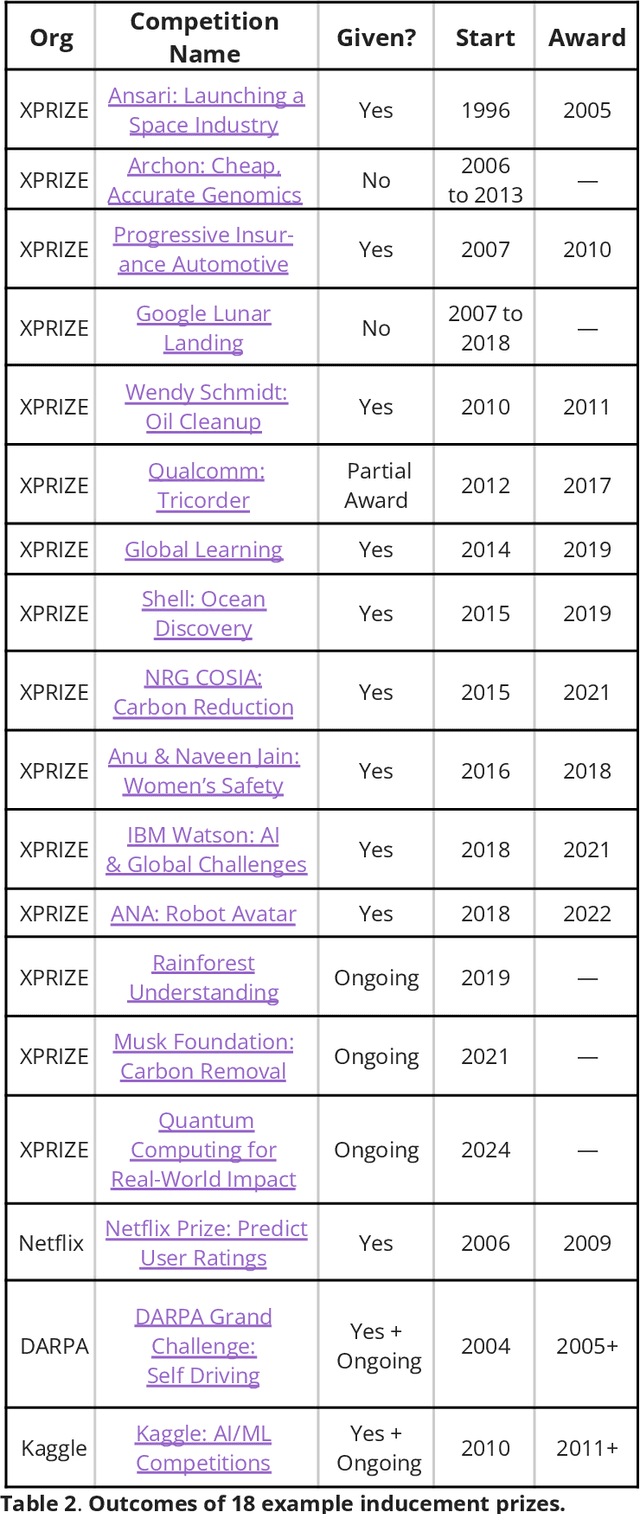
Artificial Intelligence (AI), like any transformative technology, has the potential to be a double-edged sword, leading either toward significant advancements or detrimental outcomes for society as a whole. As is often the case when it comes to widely-used technologies in market economies (e.g., cars and semiconductor chips), commercial interest tends to be the predominant guiding factor. The AI community is at risk of becoming polarized to either take a laissez-faire attitude toward AI development, or to call for government overregulation. Between these two poles we argue for the community of AI practitioners to consciously and proactively work for the common good. This paper offers a blueprint for a new type of innovation infrastructure including 18 concrete milestones to guide AI research in that direction. Our view is that we are still in the early days of practical AI, and focused efforts by practitioners, policymakers, and other stakeholders can still maximize the upsides of AI and minimize its downsides. We talked to luminaries such as recent Nobelist John Jumper on science, President Barack Obama on governance, former UN Ambassador and former National Security Advisor Susan Rice on security, philanthropist Eric Schmidt on several topics, and science fiction novelist Neal Stephenson on entertainment. This ongoing dialogue and collaborative effort has produced a comprehensive, realistic view of what the actual impact of AI could be, from a diverse assembly of thinkers with deep understanding of this technology and these domains. From these exchanges, five recurring guidelines emerged, which form the cornerstone of a framework for beginning to harness AI in service of the public good. They not only guide our efforts in discovery but also shape our approach to deploying this transformative technology responsibly and ethically.
Inverse Transition Learning: Learning Dynamics from Demonstrations
Nov 07, 2024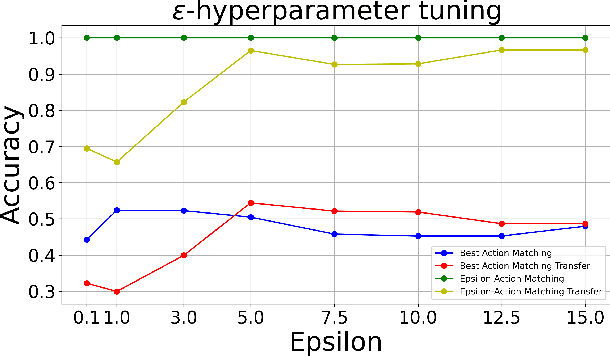
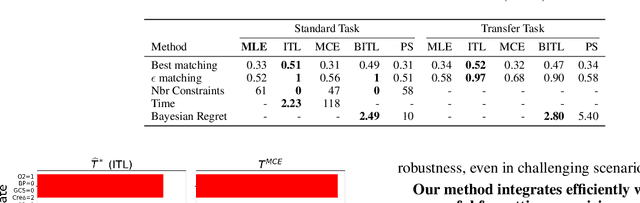
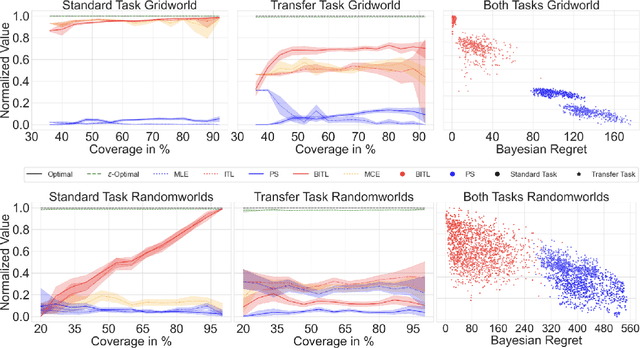
We consider the problem of estimating the transition dynamics $T^*$ from near-optimal expert trajectories in the context of offline model-based reinforcement learning. We develop a novel constraint-based method, Inverse Transition Learning, that treats the limited coverage of the expert trajectories as a \emph{feature}: we use the fact that the expert is near-optimal to inform our estimate of $T^*$. We integrate our constraints into a Bayesian approach. Across both synthetic environments and real healthcare scenarios like Intensive Care Unit (ICU) patient management in hypotension, we demonstrate not only significant improvements in decision-making, but that our posterior can inform when transfer will be successful.
Pruning the Path to Optimal Care: Identifying Systematically Suboptimal Medical Decision-Making with Inverse Reinforcement Learning
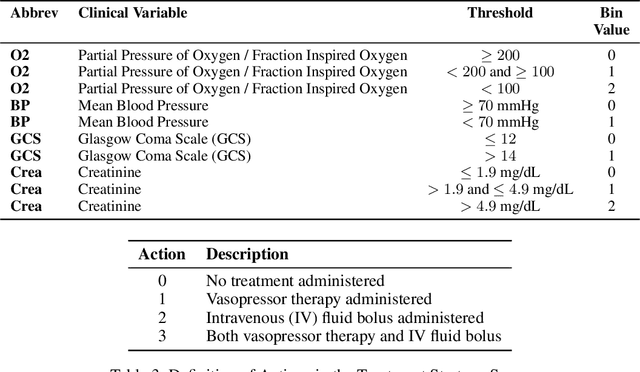
Nov 07, 2024In aims to uncover insights into medical decision-making embedded within observational data from clinical settings, we present a novel application of Inverse Reinforcement Learning (IRL) that identifies suboptimal clinician actions based on the actions of their peers. This approach centers two stages of IRL with an intermediate step to prune trajectories displaying behavior that deviates significantly from the consensus. This enables us to effectively identify clinical priorities and values from ICU data containing both optimal and suboptimal clinician decisions. We observe that the benefits of removing suboptimal actions vary by disease and differentially impact certain demographic groups.
Directly Optimizing Explanations for Desired Properties
Oct 31, 2024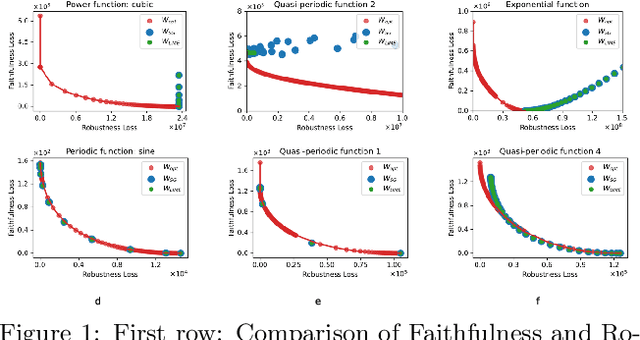
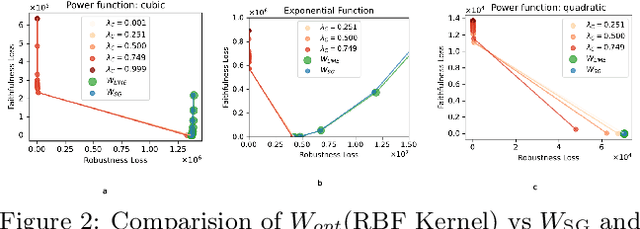
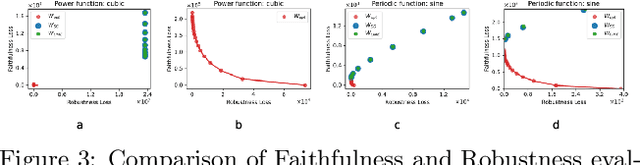
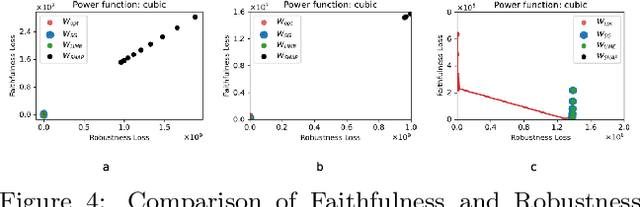
When explaining black-box machine learning models, it's often important for explanations to have certain desirable properties. Most existing methods `encourage' desirable properties in their construction of explanations. In this work, we demonstrate that these forms of encouragement do not consistently create explanations with the properties that are supposedly being targeted. Moreover, they do not allow for any control over which properties are prioritized when different properties are at odds with each other. We propose to directly optimize explanations for desired properties. Our direct approach not only produces explanations with optimal properties more consistently but also empowers users to control trade-offs between different properties, allowing them to create explanations with exactly what is needed for a particular task.
Decision-Point Guided Safe Policy Improvement
Oct 12, 2024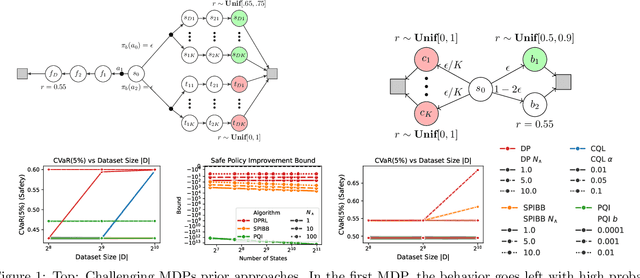
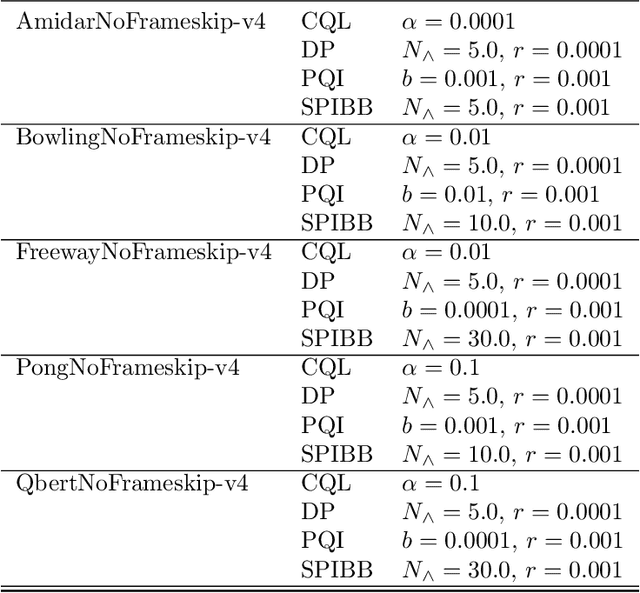
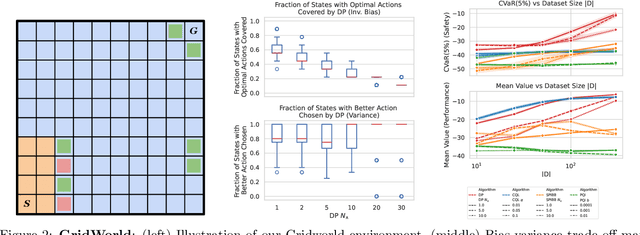

Within batch reinforcement learning, safe policy improvement (SPI) seeks to ensure that the learnt policy performs at least as well as the behavior policy that generated the dataset. The core challenge in SPI is seeking improvements while balancing risk when many state-action pairs may be infrequently visited. In this work, we introduce Decision Points RL (DPRL), an algorithm that restricts the set of state-action pairs (or regions for continuous states) considered for improvement. DPRL ensures high-confidence improvement in densely visited states (i.e. decision points) while still utilizing data from sparsely visited states. By appropriately limiting where and how we may deviate from the behavior policy, we achieve tighter bounds than prior work; specifically, our data-dependent bounds do not scale with the size of the state and action spaces. In addition to the analysis, we demonstrate that DPRL is both safe and performant on synthetic and real datasets.