 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy LLMs Fail at Causal Discovery and How Interventional Agents Escape
May 26, 2026Causal discovery is a cornerstone of scientific reasoning, yet whether large language models can perform it reliably remains an open question. Recent benchmarks show that even fine-tuned models plateau on simple causal graphs and degrade as complexity grows, but why they fail has not been established. We prove the failure is fundamental: supervised fine-tuning, direct preference optimization, and in-context learning all produce predictors that cannot distinguish between causal graphs generating similar observational data, and any attempt to do so requires the model's internal representations to grow unboundedly, violating the very conditions under which these methods work. We formalize this as a kernel obstruction theorem, establishing that the limitation is intrinsic to the learning paradigm, \emph{not any particular model or dataset}. We propose Agentic Causal Bayesian Optimization (A-CBO), wherein a frozen language model serves as an interventional oracle answering targeted queries about intervention effects, while an external Bayesian loop concentrates beliefs over candidate graphs in logarithmically many rounds. Because the decision operates outside the space where the obstruction applies, A-CBO provably converges while the underlying model remains unchanged. On Corr2Cause, A-CBO matches fine-tuned baselines without any training. On Extended Corr2Cause, a new benchmark scaling to 24 variables with 18K test samples, A-CBO significantly outperforms both fine-tuning and preference optimization, with the advantage growing
Causal methods for LLM development and evaluation
May 25, 2026Large language model (LLM) development is currently driven by large-scale empirical iteration over data mixtures, reward models, routing strategies, and evaluation pipelines. Here, we argue that many central questions in LLM development and evaluation are inherently causal: What is the effect of adding a data domain during pretraining? How do annotator preferences change when LLMs generate text in a different style? Should a prompt be routed to a larger or smaller model given inference cost constraints? In general, causal methods are well-suited to such settings where interventions change outcomes but, surprisingly, are underrepresented in LLM development. Our contribution is threefold: (1) We explain how causal methods can help develop modern LLM development and evaluation: LLM development relies heavily on logged data, which are often subject to confounding and distribution shifts; evaluation uses learned but potentially biased judges; and deployment environments are non-stationary. These conditions make purely predictive approaches fragile and create opportunities for principled identification and estimation methods from causal inference. (2) We further map opportunities for causal methods in the entire LLM development pipeline, including pretraining, alignment, routing, agentic workflows, and evaluation. (3) We discuss new research opportunities around leveraging causal methods for LLM development and evaluation. Overall, we argue that causal methods are potentially underutilized for the LLM development and evaluation pipeline, despite the fact that such methods can ensure a reliable and scientifically grounded design.
Causal Machine Learning Is Not a Panacea: A Roadmap for Observational Causal Inference in Health
May 20, 2026Objective: The growing availability of large-scale observational clinical datasets and challenges in conducting randomized controlled trials have spurred enthusiasm in using causal machine learning (ML) for causal inference in observational data. We present a roadmap for applying causal ML to observational data. Materials and methods: We outline the importance of assessing validity assumptions within available data and applying causal ML responsibly for clinical experts using causal ML and ML practitioners with limited clinical expertise. Observations: Despite advances in causal ML, its limitations remain largely under-appreciated across disciplines. This gap in shared knowledge may impact the validity of findings. Discussion: Causal assumptions must be satisfied and modeling choices justified. Otherwise, these approaches risk producing biased or misleading results, with consequences for clinical research and patient care. Conclusion: Causal ML can be a powerful tool for generating causal hypotheses. We provide a template to strengthen the rigor and interpretability of causal analyses.
Causal Bayesian Optimization with Unknown Graphs
Mar 25, 2025Causal Bayesian Optimization (CBO) is a methodology designed to optimize an outcome variable by leveraging known causal relationships through targeted interventions. Traditional CBO methods require a fully and accurately specified causal graph, which is a limitation in many real-world scenarios where such graphs are unknown. To address this, we propose a new method for the CBO framework that operates without prior knowledge of the causal graph. Consistent with causal bandit theory, we demonstrate through theoretical analysis and that focusing on the direct causal parents of the target variable is sufficient for optimization, and provide empirical validation in the context of CBO. Furthermore we introduce a new method that learns a Bayesian posterior over the direct parents of the target variable. This allows us to optimize the outcome variable while simultaneously learning the causal structure. Our contributions include a derivation of the closed-form posterior distribution for the linear case. In the nonlinear case where the posterior is not tractable, we present a Gaussian Process (GP) approximation that still enables CBO by inferring the parents of the outcome variable. The proposed method performs competitively with existing benchmarks and scales well to larger graphs, making it a practical tool for real-world applications where causal information is incomplete.
Feature Importance Depends on Properties of the Data: Towards Choosing the Correct Explanations for Your Data and Decision Trees based Models
Feb 11, 2025In order to ensure the reliability of the explanations of machine learning models, it is crucial to establish their advantages and limits and in which case each of these methods outperform. However, the current understanding of when and how each method of explanation can be used is insufficient. To fill this gap, we perform a comprehensive empirical evaluation by synthesizing multiple datasets with the desired properties. Our main objective is to assess the quality of feature importance estimates provided by local explanation methods, which are used to explain predictions made by decision tree-based models. By analyzing the results obtained from synthetic datasets as well as publicly available binary classification datasets, we observe notable disparities in the magnitude and sign of the feature importance estimates generated by these methods. Moreover, we find that these estimates are sensitive to specific properties present in the data. Although some model hyper-parameters do not significantly influence feature importance assignment, it is important to recognize that each method of explanation has limitations in specific contexts. Our assessment highlights these limitations and provides valuable insight into the suitability and reliability of different explanatory methods in various scenarios.
Concept-driven Off Policy Evaluation
Nov 28, 2024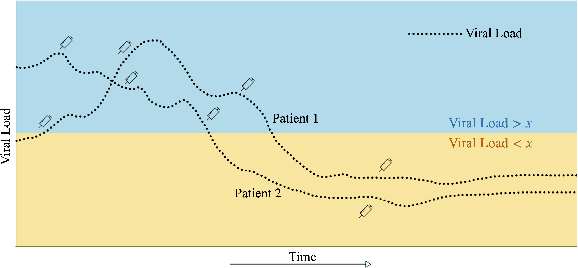
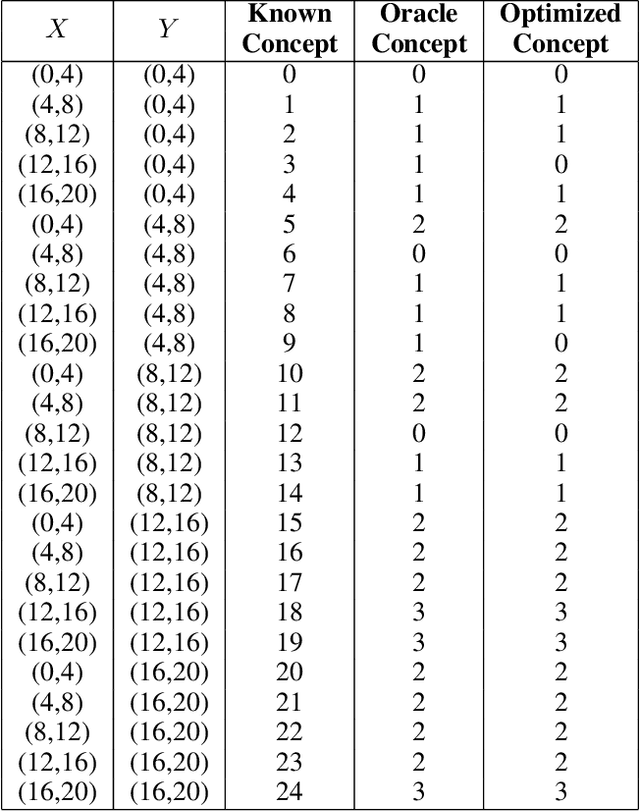
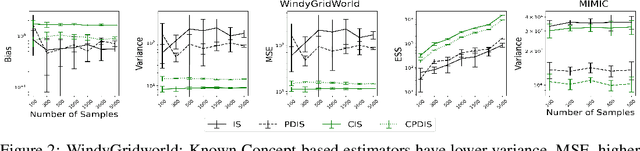
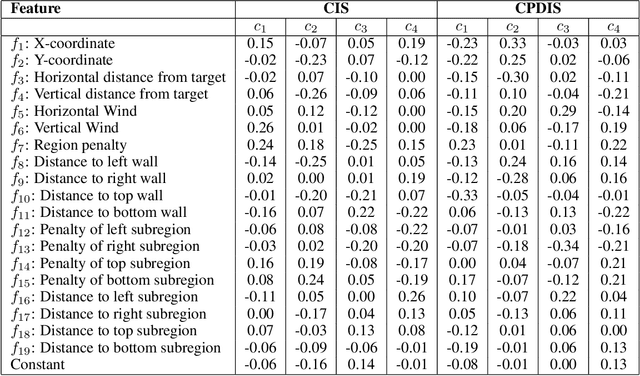
Evaluating off-policy decisions using batch data poses significant challenges due to limited sample sizes leading to high variance. To improve Off-Policy Evaluation (OPE), we must identify and address the sources of this variance. Recent research on Concept Bottleneck Models (CBMs) shows that using human-explainable concepts can improve predictions and provide better understanding. We propose incorporating concepts into OPE to reduce variance. Our work introduces a family of concept-based OPE estimators, proving that they remain unbiased and reduce variance when concepts are known and predefined. Since real-world applications often lack predefined concepts, we further develop an end-to-end algorithm to learn interpretable, concise, and diverse parameterized concepts optimized for variance reduction. Our experiments with synthetic and real-world datasets show that both known and learned concept-based estimators significantly improve OPE performance. Crucially, we show that, unlike other OPE methods, concept-based estimators are easily interpretable and allow for targeted interventions on specific concepts, further enhancing the quality of these estimators.
Inverse Transition Learning: Learning Dynamics from Demonstrations
Nov 07, 2024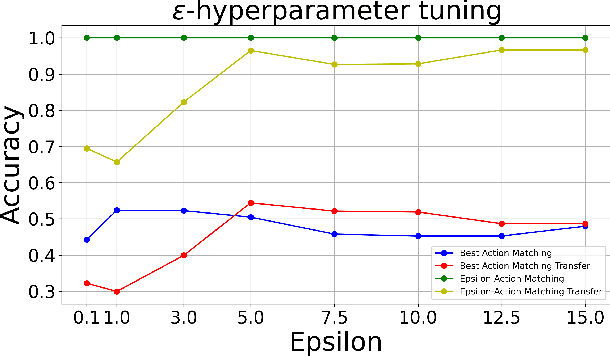
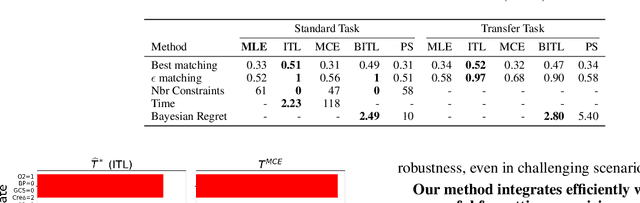
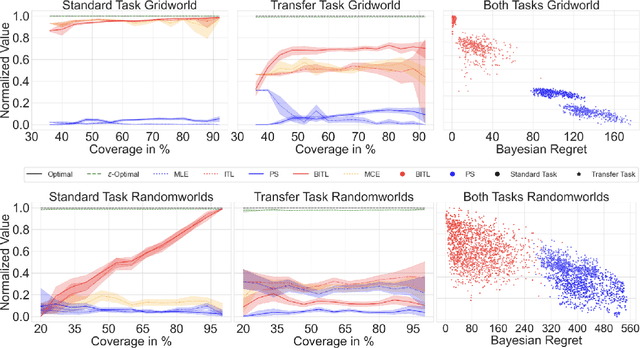
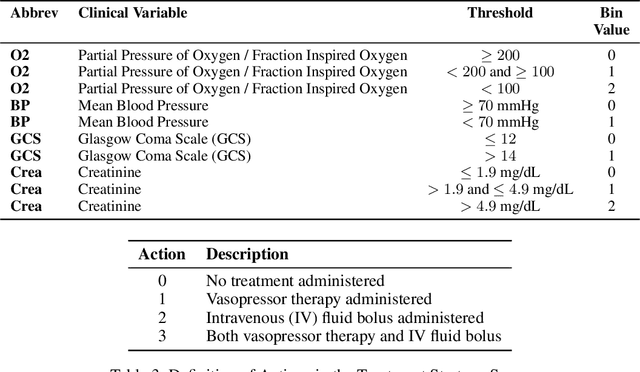
We consider the problem of estimating the transition dynamics $T^*$ from near-optimal expert trajectories in the context of offline model-based reinforcement learning. We develop a novel constraint-based method, Inverse Transition Learning, that treats the limited coverage of the expert trajectories as a \emph{feature}: we use the fact that the expert is near-optimal to inform our estimate of $T^*$. We integrate our constraints into a Bayesian approach. Across both synthetic environments and real healthcare scenarios like Intensive Care Unit (ICU) patient management in hypotension, we demonstrate not only significant improvements in decision-making, but that our posterior can inform when transfer will be successful.
Insights from the Inverse: Reconstructing LLM Training Goals Through Inverse RL
Oct 16, 2024



Large language models (LLMs) trained with Reinforcement Learning from Human Feedback (RLHF) have demonstrated remarkable capabilities, but their underlying reward functions and decision-making processes remain opaque. This paper introduces a novel approach to interpreting LLMs by applying inverse reinforcement learning (IRL) to recover their implicit reward functions. We conduct experiments on toxicity-aligned LLMs of varying sizes, extracting reward models that achieve up to 80.40% accuracy in predicting human preferences. Our analysis reveals key insights into the non-identifiability of reward functions, the relationship between model size and interpretability, and potential pitfalls in the RLHF process. We demonstrate that IRL-derived reward models can be used to fine-tune new LLMs, resulting in comparable or improved performance on toxicity benchmarks. This work provides a new lens for understanding and improving LLM alignment, with implications for the responsible development and deployment of these powerful systems.
Decision-Point Guided Safe Policy Improvement
Oct 12, 2024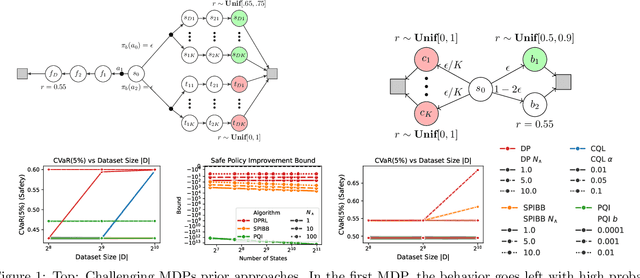
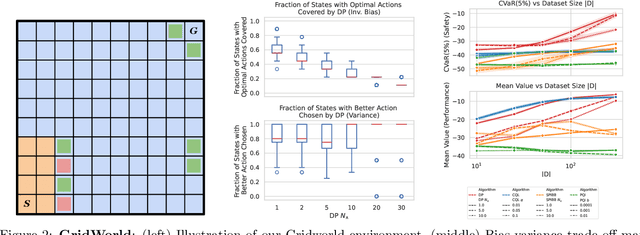

Within batch reinforcement learning, safe policy improvement (SPI) seeks to ensure that the learnt policy performs at least as well as the behavior policy that generated the dataset. The core challenge in SPI is seeking improvements while balancing risk when many state-action pairs may be infrequently visited. In this work, we introduce Decision Points RL (DPRL), an algorithm that restricts the set of state-action pairs (or regions for continuous states) considered for improvement. DPRL ensures high-confidence improvement in densely visited states (i.e. decision points) while still utilizing data from sparsely visited states. By appropriately limiting where and how we may deviate from the behavior policy, we achieve tighter bounds than prior work; specifically, our data-dependent bounds do not scale with the size of the state and action spaces. In addition to the analysis, we demonstrate that DPRL is both safe and performant on synthetic and real datasets.
Tree-Based Leakage Inspection and Control in Concept Bottleneck Models
Oct 08, 2024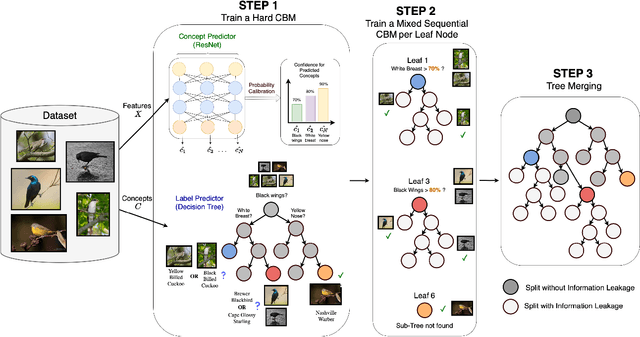

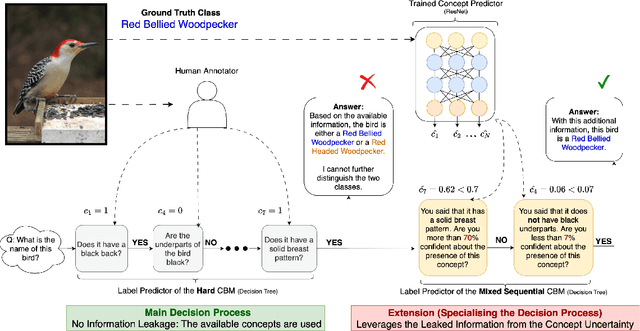

As AI models grow larger, the demand for accountability and interpretability has become increasingly critical for understanding their decision-making processes. Concept Bottleneck Models (CBMs) have gained attention for enhancing interpretability by mapping inputs to intermediate concepts before making final predictions. However, CBMs often suffer from information leakage, where additional input data, not captured by the concepts, is used to improve task performance, complicating the interpretation of downstream predictions. In this paper, we introduce a novel approach for training both joint and sequential CBMs that allows us to identify and control leakage using decision trees. Our method quantifies leakage by comparing the decision paths of hard CBMs with their soft, leaky counterparts. Specifically, we show that soft leaky CBMs extend the decision paths of hard CBMs, particularly in cases where concept information is incomplete. Using this insight, we develop a technique to better inspect and manage leakage, isolating the subsets of data most affected by this. Through synthetic and real-world experiments, we demonstrate that controlling leakage in this way not only improves task accuracy but also yields more informative and transparent explanations.