 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning Framework for Turbofan Health Estimation via Inverse Problem Formulation
Apr 09, 2026Estimating the health state of turbofan engines is a challenging ill-posed inverse problem, hindered by sparse sensing and complex nonlinear thermodynamics. Research in this area remains fragmented, with comparisons limited by the use of unrealistic datasets and insufficient exploration of the exploitation of temporal information. This work investigates how to recover component-level health indicators from operational sensor data under realistic degradation and maintenance patterns. To support this study, we introduce a new dataset that incorporates industry-oriented complexities such as maintenance events and usage changes. Using this dataset, we establish an initial benchmark that compares steady-state and nonstationary data-driven models, and Bayesian filters, classic families of methods used to solve this problem. In addition to this benchmark, we introduce self-supervised learning (SSL) approaches that learn latent representations without access to true health labels, a scenario reflective of real-world operational constraints. By comparing the downstream estimation performance of these unsupervised representations against the direct prediction baselines, we establish a practical lower bound on the difficulty of solving this inverse problem. Our results reveal that traditional filters remain strong baselines, while SSL methods reveal the intrinsic complexity of health estimation and highlight the need for more advanced and interpretable inference strategies. For reproducibility, both the generated dataset and the implementation used in this work are made accessible.
Simulation-Driven Railway Delay Prediction: An Imitation Learning Approach
Dec 17, 2025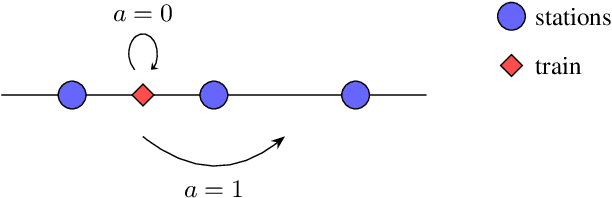
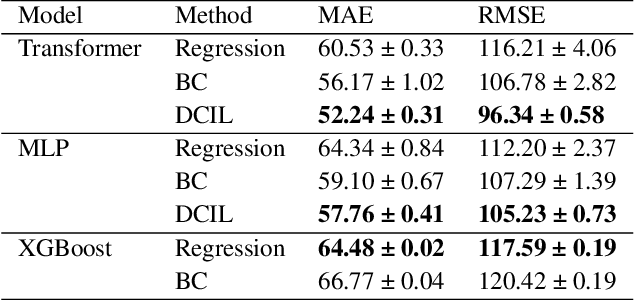
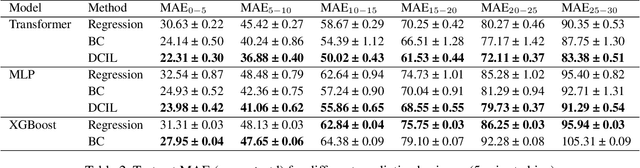
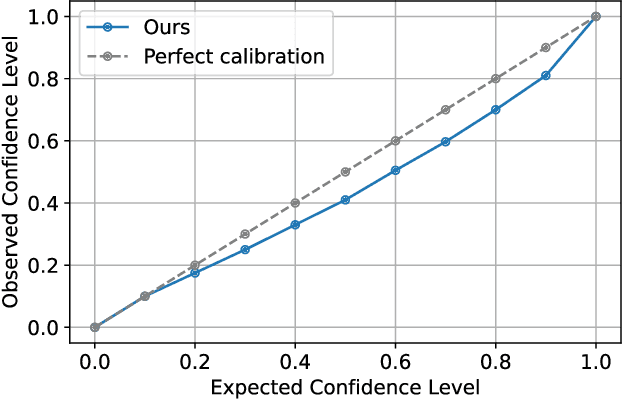
Reliable prediction of train delays is essential for enhancing the robustness and efficiency of railway transportation systems. In this work, we reframe delay forecasting as a stochastic simulation task, modeling state-transition dynamics through imitation learning. We introduce Drift-Corrected Imitation Learning (DCIL), a novel self-supervised algorithm that extends DAgger by incorporating distance-based drift correction, thereby mitigating covariate shift during rollouts without requiring access to an external oracle or adversarial schemes. Our approach synthesizes the dynamical fidelity of event-driven models with the representational capacity of data-driven methods, enabling uncertainty-aware forecasting via Monte Carlo simulation. We evaluate DCIL using a comprehensive real-world dataset from \textsc{Infrabel}, the Belgian railway infrastructure manager, which encompasses over three million train movements. Our results, focused on predictions up to 30 minutes ahead, demonstrate superior predictive performance of DCIL over traditional regression models and behavioral cloning on deep learning architectures, highlighting its effectiveness in capturing the sequential and uncertain nature of delay propagation in large-scale networks.
Binary Split Categorical feature with Mean Absolute Error Criteria in CART
Nov 11, 2025


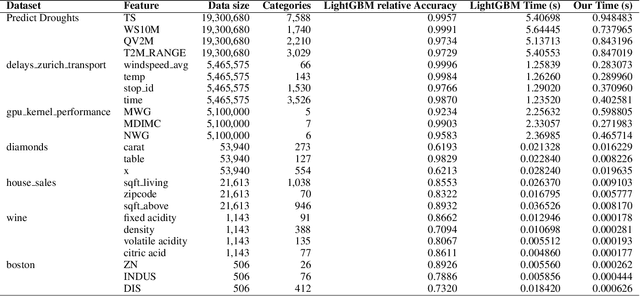
In the context of the Classification and Regression Trees (CART) algorithm, the efficient splitting of categorical features using standard criteria like GINI and Entropy is well-established. However, using the Mean Absolute Error (MAE) criterion for categorical features has traditionally relied on various numerical encoding methods. This paper demonstrates that unsupervised numerical encoding methods are not viable for the MAE criteria. Furthermore, we present a novel and efficient splitting algorithm that addresses the challenges of handling categorical features with the MAE criterion. Our findings underscore the limitations of existing approaches and offer a promising solution to enhance the handling of categorical data in CART algorithms.
Estimating Conditional Covariance between labels for Multilabel Data
Aug 26, 2025Multilabel data should be analysed for label dependence before applying multilabel models. Independence between multilabel data labels cannot be measured directly from the label values due to their dependence on the set of covariates $\vec{x}$, but can be measured by examining the conditional label covariance using a multivariate Probit model. Unfortunately, the multivariate Probit model provides an estimate of its copula covariance, and so might not be reliable in estimating constant covariance and dependent covariance. In this article, we compare three models (Multivariate Probit, Multivariate Bernoulli and Staged Logit) for estimating the constant and dependent multilabel conditional label covariance. We provide an experiment that allows us to observe each model's measurement of conditional covariance. We found that all models measure constant and dependent covariance equally well, depending on the strength of the covariance, but the models all falsely detect that dependent covariance is present for data where constant covariance is present. Of the three models, the Multivariate Probit model had the lowest error rate.
Flow Models for Unbounded and Geometry-Aware Distributional Reinforcement Learning
May 07, 2025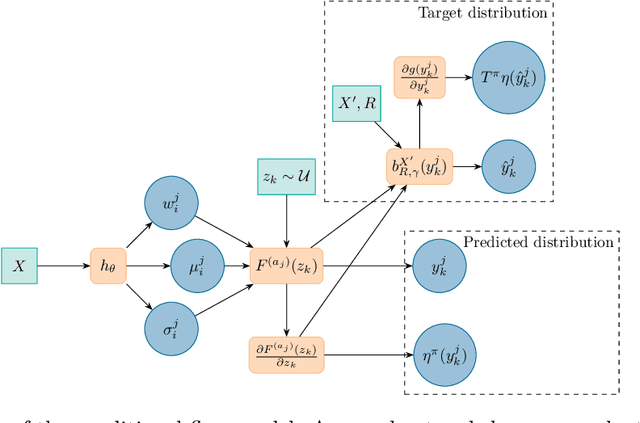
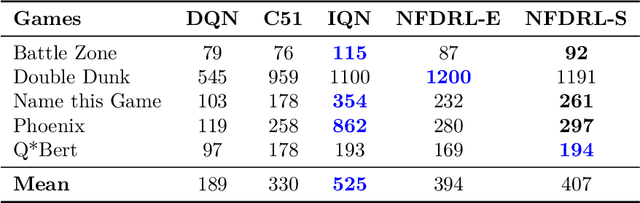
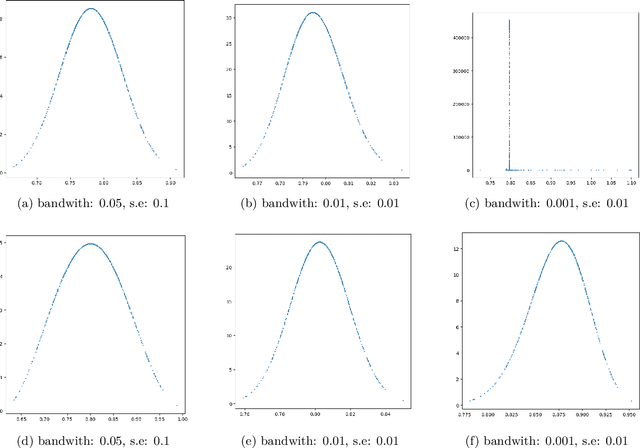

We introduce a new architecture for Distributional Reinforcement Learning (DistRL) that models return distributions using normalizing flows. This approach enables flexible, unbounded support for return distributions, in contrast to categorical approaches like C51 that rely on fixed or bounded representations. It also offers richer modeling capacity to capture multi-modality, skewness, and tail behavior than quantile based approaches. Our method is significantly more parameter-efficient than categorical approaches. Standard metrics used to train existing models like KL divergence or Wasserstein distance either are scale insensitive or have biased sample gradients, especially when return supports do not overlap. To address this, we propose a novel surrogate for the Cram\`er distance, that is geometry-aware and computable directly from the return distribution's PDF, avoiding the costly CDF computation. We test our model on the ATARI-5 sub-benchmark and show that our approach outperforms PDF based models while remaining competitive with quantile based methods.
Feature Importance Depends on Properties of the Data: Towards Choosing the Correct Explanations for Your Data and Decision Trees based Models
Feb 11, 2025In order to ensure the reliability of the explanations of machine learning models, it is crucial to establish their advantages and limits and in which case each of these methods outperform. However, the current understanding of when and how each method of explanation can be used is insufficient. To fill this gap, we perform a comprehensive empirical evaluation by synthesizing multiple datasets with the desired properties. Our main objective is to assess the quality of feature importance estimates provided by local explanation methods, which are used to explain predictions made by decision tree-based models. By analyzing the results obtained from synthetic datasets as well as publicly available binary classification datasets, we observe notable disparities in the magnitude and sign of the feature importance estimates generated by these methods. Moreover, we find that these estimates are sensitive to specific properties present in the data. Although some model hyper-parameters do not significantly influence feature importance assignment, it is important to recognize that each method of explanation has limitations in specific contexts. Our assessment highlights these limitations and provides valuable insight into the suitability and reliability of different explanatory methods in various scenarios.
Label Cluster Chains for Multi-Label Classification
Nov 01, 2024



Multi-label classification is a type of supervised machine learning that can simultaneously assign multiple labels to an instance. To solve this task, some methods divide the original problem into several sub-problems (local approach), others learn all labels at once (global approach), and others combine several classifiers (ensemble approach). Regardless of the approach used, exploring and learning label correlations is important to improve the classifier predictions. Ensemble of Classifier Chains (ECC) is a well-known multi-label method that considers label correlations and can achieve good overall performance on several multi-label datasets and evaluation measures. However, one of the challenges when working with ECC is the high dimensionality of the label space, which can impose limitations for fully-cascaded chains as the complexity increases regarding feature space expansion. To improve classifier chains, we propose a method to chain disjoint correlated label clusters obtained by applying a partition method in the label space. During the training phase, the ground truth labels of each cluster are used as new features for all of the following clusters. During the test phase, the predicted labels of clusters are used as new features for all the following clusters. Our proposal, called Label Cluster Chains for Multi-Label Classification (LCC-ML), uses multi-label Random Forests as base classifiers in each cluster, combining their predictions to obtain a final multi-label classification. Our proposal obtained better results compared to the original ECC. This shows that learning and chaining disjoint correlated label clusters can better explore and learn label correlations.
Branches: A Fast Dynamic Programming and Branch & Bound Algorithm for Optimal Decision Trees
Jun 04, 2024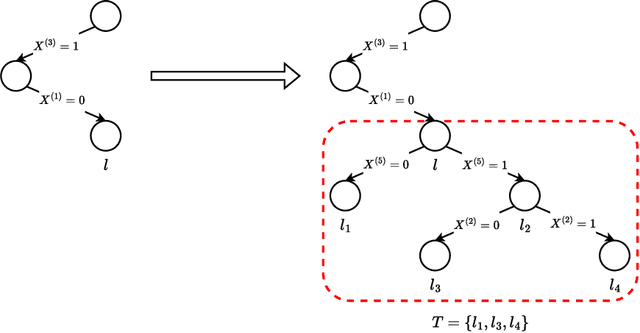
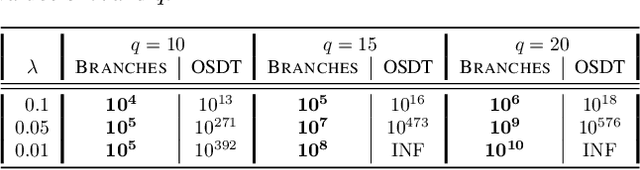
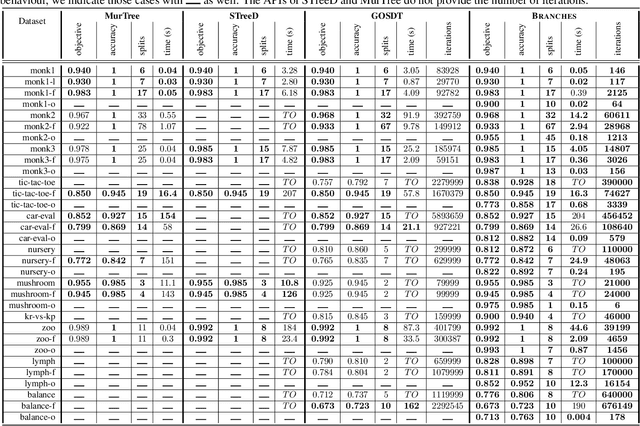
Decision Tree Learning is a fundamental problem for Interpretable Machine Learning, yet it poses a formidable optimization challenge. Despite numerous efforts dating back to the early 1990's, practical algorithms have only recently emerged, primarily leveraging Dynamic Programming (DP) and Branch & Bound (B&B) techniques. These breakthroughs led to the development of two distinct approaches. Algorithms like DL8.5 and MurTree operate on the space of nodes (or branches), they are very fast, but do not penalise complex Decision Trees, i.e. they do not solve for sparsity. On the other hand, algorithms like OSDT and GOSDT operate on the space of Decision Trees, they solve for sparsity but at the detriment of speed. In this work, we introduce Branches, a novel algorithm that integrates the strengths of both paradigms. Leveraging DP and B&B, Branches achieves exceptional speed while also solving for sparsity. Central to its efficiency is a novel analytical bound enabling substantial pruning of the search space. Theoretical analysis demonstrates that Branches has lower complexity compared to state-of-the-art methods, a claim validated through extensive empirical evaluation. Our results illustrate that Branches not only greatly outperforms existing approaches in terms of speed and number of iterations, it also consistently yields optimal Decision Trees.
Online Learning of Decision Trees with Thompson Sampling
Apr 09, 2024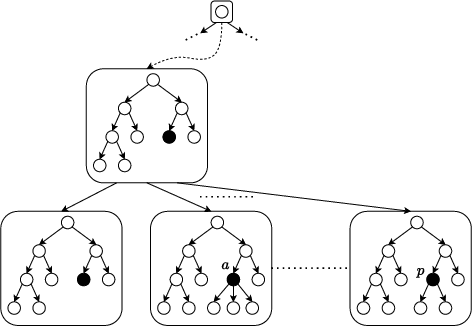

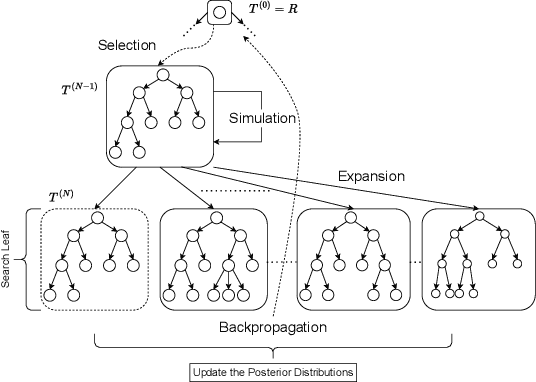
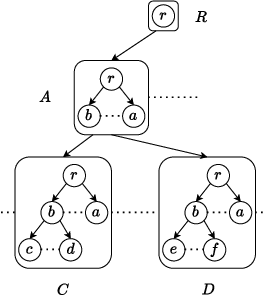
Decision Trees are prominent prediction models for interpretable Machine Learning. They have been thoroughly researched, mostly in the batch setting with a fixed labelled dataset, leading to popular algorithms such as C4.5, ID3 and CART. Unfortunately, these methods are of heuristic nature, they rely on greedy splits offering no guarantees of global optimality and often leading to unnecessarily complex and hard-to-interpret Decision Trees. Recent breakthroughs addressed this suboptimality issue in the batch setting, but no such work has considered the online setting with data arriving in a stream. To this end, we devise a new Monte Carlo Tree Search algorithm, Thompson Sampling Decision Trees (TSDT), able to produce optimal Decision Trees in an online setting. We analyse our algorithm and prove its almost sure convergence to the optimal tree. Furthermore, we conduct extensive experiments to validate our findings empirically. The proposed TSDT outperforms existing algorithms on several benchmarks, all while presenting the practical advantage of being tailored to the online setting.
A Historical Context for Data Streams
Oct 18, 2023Machine learning from data streams is an active and growing research area. Research on learning from streaming data typically makes strict assumptions linked to computational resource constraints, including requirements for stream mining algorithms to inspect each instance not more than once and be ready to give a prediction at any time. Here we review the historical context of data streams research placing the common assumptions used in machine learning over data streams in their historical context.