 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOxytrees: Model Trees for Bipartite Learning
Nov 16, 2025Bipartite learning is a machine learning task that aims to predict interactions between pairs of instances. It has been applied to various domains, including drug-target interactions, RNA-disease associations, and regulatory network inference. Despite being widely investigated, current methods still present drawbacks, as they are often designed for a specific application and thus do not generalize to other problems or present scalability issues. To address these challenges, we propose Oxytrees: proxy-based biclustering model trees. Oxytrees compress the interaction matrix into row- and column-wise proxy matrices, significantly reducing training time without compromising predictive performance. We also propose a new leaf-assignment algorithm that significantly reduces the time taken for prediction. Finally, Oxytrees employ linear models using the Kronecker product kernel in their leaves, resulting in shallower trees and thus even faster training. Using 15 datasets, we compared the predictive performance of ensembles of Oxytrees with that of the current state-of-the-art. We achieved up to 30-fold improvement in training times compared to state-of-the-art biclustering forests, while demonstrating competitive or superior performance in most evaluation settings, particularly in the inductive setting. Finally, we provide an intuitive Python API to access all datasets, methods and evaluation measures used in this work, thus enabling reproducible research in this field.
Pairwise and Attribute-Aware Decision Tree-Based Preference Elicitation for Cold-Start Recommendation
Oct 31, 2025


Recommender systems (RSs) are intelligent filtering methods that suggest items to users based on their inferred preferences, derived from their interaction history on the platform. Collaborative filtering-based RSs rely on users past interactions to generate recommendations. However, when a user is new to the platform, referred to as a cold-start user, there is no historical data available, making it difficult to provide personalized recommendations. To address this, rating elicitation techniques can be used to gather initial ratings or preferences on selected items, helping to build an early understanding of the user's tastes. Rating elicitation approaches are generally categorized into two types: non-personalized and personalized. Decision tree-based rating elicitation is a personalized method that queries users about their preferences at each node of the tree until sufficient information is gathered. In this paper, we propose an extension to the decision tree approach for rating elicitation in the context of music recommendation. Our method: (i) elicits not only item ratings but also preferences on attributes such as genres to better cluster users, and (ii) uses item pairs instead of single items at each node to more effectively learn user preferences. Experimental results demonstrate that both proposed enhancements lead to improved performance, particularly with a reduced number of queries.
Label Cluster Chains for Multi-Label Classification
Nov 01, 2024



Multi-label classification is a type of supervised machine learning that can simultaneously assign multiple labels to an instance. To solve this task, some methods divide the original problem into several sub-problems (local approach), others learn all labels at once (global approach), and others combine several classifiers (ensemble approach). Regardless of the approach used, exploring and learning label correlations is important to improve the classifier predictions. Ensemble of Classifier Chains (ECC) is a well-known multi-label method that considers label correlations and can achieve good overall performance on several multi-label datasets and evaluation measures. However, one of the challenges when working with ECC is the high dimensionality of the label space, which can impose limitations for fully-cascaded chains as the complexity increases regarding feature space expansion. To improve classifier chains, we propose a method to chain disjoint correlated label clusters obtained by applying a partition method in the label space. During the training phase, the ground truth labels of each cluster are used as new features for all of the following clusters. During the test phase, the predicted labels of clusters are used as new features for all the following clusters. Our proposal, called Label Cluster Chains for Multi-Label Classification (LCC-ML), uses multi-label Random Forests as base classifiers in each cluster, combining their predictions to obtain a final multi-label classification. Our proposal obtained better results compared to the original ECC. This shows that learning and chaining disjoint correlated label clusters can better explore and learn label correlations.
HypeRS: Building a Hypergraph-driven ensemble Recommender System
Jun 22, 2023Recommender systems are designed to predict user preferences over collections of items. These systems process users' previous interactions to decide which items should be ranked higher to satisfy their desires. An ensemble recommender system can achieve great recommendation performance by effectively combining the decisions generated by individual models. In this paper, we propose a novel ensemble recommender system that combines predictions made by different models into a unified hypergraph ranking framework. This is the first time that hypergraph ranking has been employed to model an ensemble of recommender systems. Hypergraphs are generalizations of graphs where multiple vertices can be connected via hyperedges, efficiently modeling high-order relations. We differentiate real and predicted connections between users and items by assigning different hyperedge weights to individual recommender systems. We perform experiments using four datasets from the fields of movie, music and news media recommendation. The obtained results show that the ensemble hypergraph ranking method generates more accurate recommendations compared to the individual models and a weighted hybrid approach. The assignment of different hyperedge weights to the ensemble hypergraph further improves the performance compared to a setting with identical hyperedge weights.
Predicting Survival Outcomes in the Presence of Unlabeled Data
Oct 25, 2022Many clinical studies require the follow-up of patients over time. This is challenging: apart from frequently observed drop-out, there are often also organizational and financial challenges, which can lead to reduced data collection and, in turn, can complicate subsequent analyses. In contrast, there is often plenty of baseline data available of patients with similar characteristics and background information, e.g., from patients that fall outside the study time window. In this article, we investigate whether we can benefit from the inclusion of such unlabeled data instances to predict accurate survival times. In other words, we introduce a third level of supervision in the context of survival analysis, apart from fully observed and censored instances, we also include unlabeled instances. We propose three approaches to deal with this novel setting and provide an empirical comparison over fifteen real-life clinical and gene expression survival datasets. Our results demonstrate that all approaches are able to increase the predictive performance over independent test data. We also show that integrating the partial supervision provided by censored data in a semi-supervised wrapper approach generally provides the best results, often achieving high improvements, compared to not using unlabeled data.
Hierarchy exploitation to detect missing annotations on hierarchical multi-label classification
Jul 13, 2022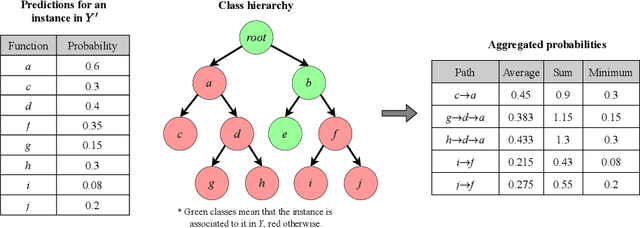
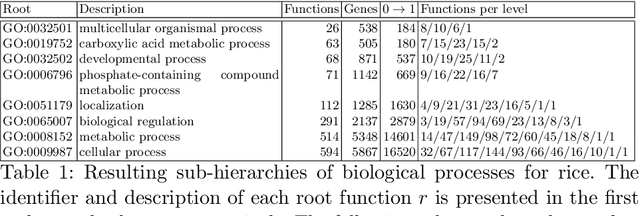
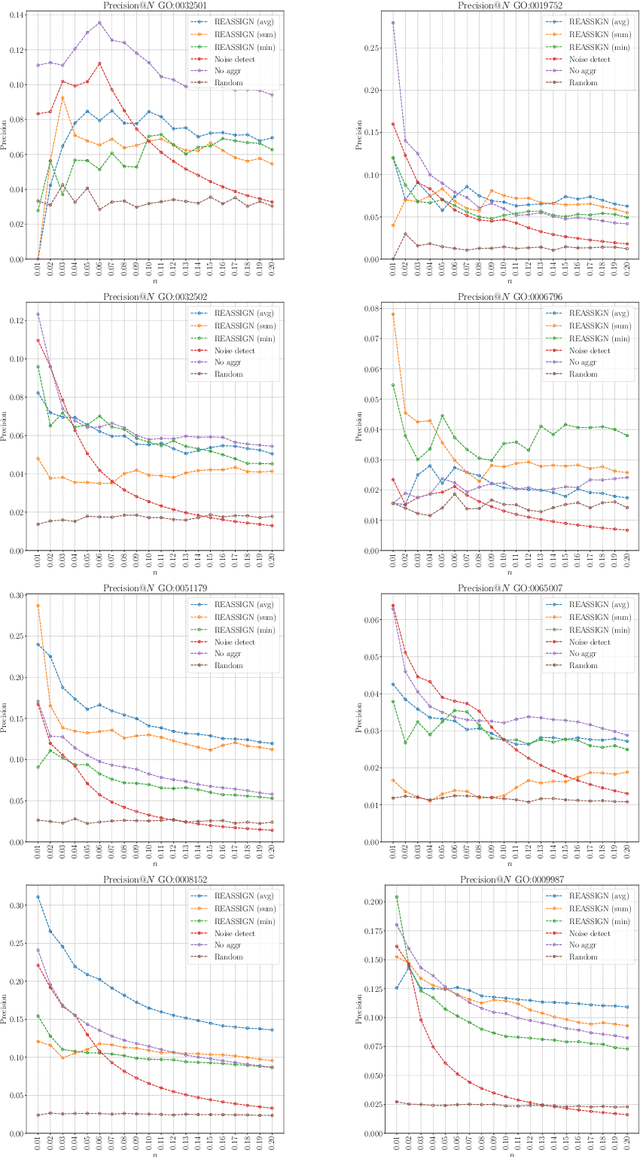
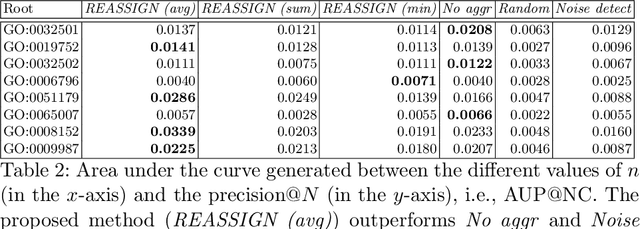
The availability of genomic data has grown exponentially in the last decade, mainly due to the development of new sequencing technologies. Based on the interactions between genes (and gene products) extracted from the increasing genomic data, numerous studies have focused on the identification of associations between genes and functions. While these studies have shown great promise, the problem of annotating genes with functions remains an open challenge. In this work, we present a method to detect missing annotations in hierarchical multi-label classification datasets. We propose a method that exploits the class hierarchy by computing aggregated probabilities to the paths of classes from the leaves to the root for each instance. The proposed method is presented in the context of predicting missing gene function annotations, where these aggregated probabilities are further used to select a set of annotations to be verified through in vivo experiments. The experiments on Oriza sativa Japonica, a variety of rice, showcase that incorporating the hierarchy of classes into the method often improves the predictive performance and our proposed method yields superior results when compared to competitor methods from the literature.
Explaining random forest prediction through diverse rulesets
Mar 29, 2022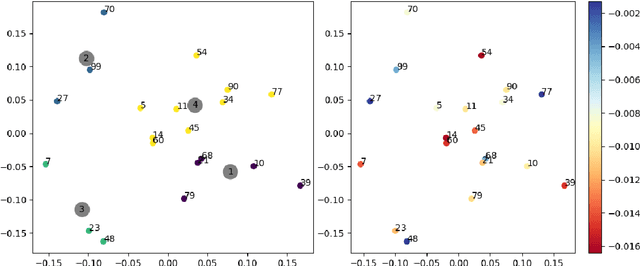

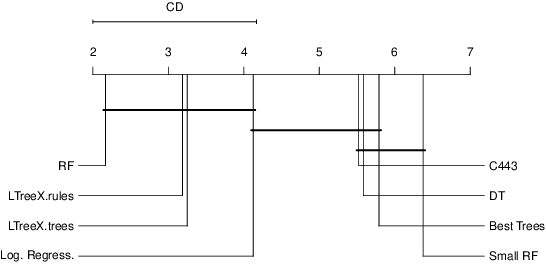
Tree-ensemble algorithms, such as random forest, are effective machine learning methods popular for their flexibility, high performance, and robustness to overfitting. However, since multiple learners are combined,they are not as interpretable as a single decision tree. In this work we propose a methodology, called Local Tree eXtractor (LTreeX) which is able to explain the forest prediction for a given test instance with a few diverse rules. Starting from the decision trees generated by a random forest, our method 1) pre-selects a subset of them, 2) creates a vector representation, and 3) eventually clusters such a representation. Each cluster prototype results in a rule that explains the test instance prediction. We test the effectiveness of LTreeX on 71 real-world datasets and we demonstrate the validity of our approach for binary classification, regression, multi-label classification and time-to-event tasks. In all set-ups, we show that our extracted surrogate model manages to approximate the performance of the corresponding ensemble model, while selecting only few trees from the whole forest.We also show that our proposed approach substantially outperforms other explainable methods in terms of predictive performance.
An Adaptive Hybrid Active Learning Strategy with Free Ratings in Collaborative Filtering
Mar 11, 2022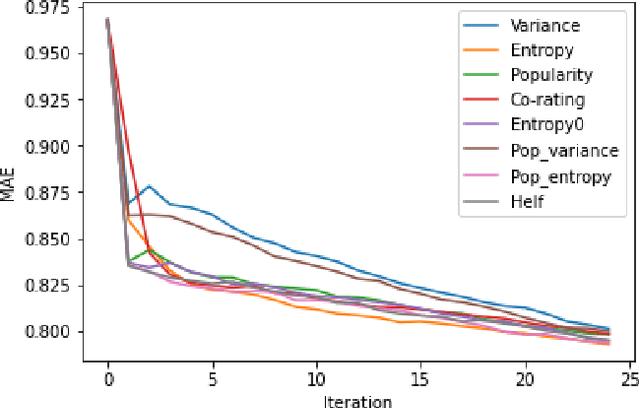
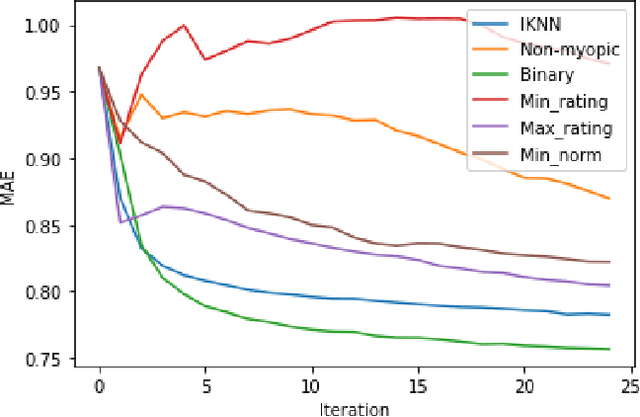
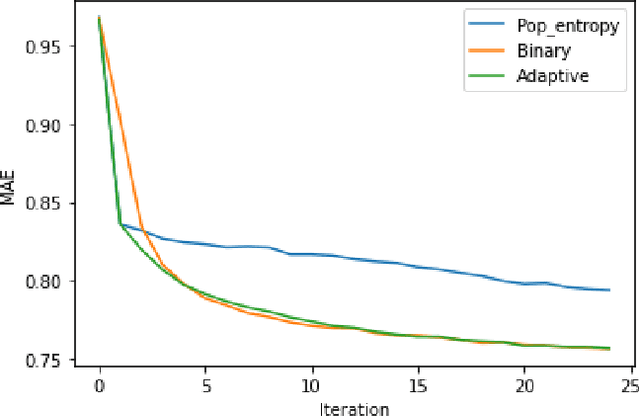
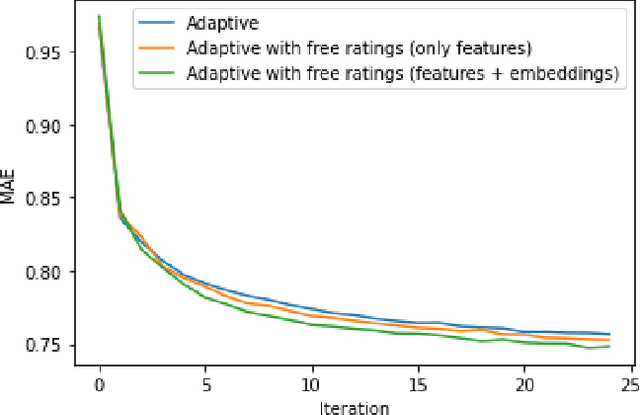
Recommender systems are information retrieval methods that predict user preferences to personalize services. These systems use the feedback and the ratings provided by users to model the behavior of users and to generate recommendations. Typically, the ratings are quite sparse, i.e., only a small fraction of items are rated by each user. To address this issue and enhance the performance, active learning strategies can be used to select the most informative items to be rated. This rating elicitation procedure enriches the interaction matrix with informative ratings and therefore assists the recommender system to better model the preferences of the users. In this paper, we evaluate various non-personalized and personalized rating elicitation strategies. We also propose a hybrid strategy that adaptively combines a non-personalized and a personalized strategy. Furthermore, we propose a new procedure to obtain free ratings based on the side information of the items. We evaluate these ideas on the MovieLens dataset. The experiments reveal that our proposed hybrid strategy outperforms the strategies from the literature. We also propose the extent to which free ratings are obtained, improving further the performance and also the user experience.
Diversification in Session-based News Recommender Systems
Feb 05, 2021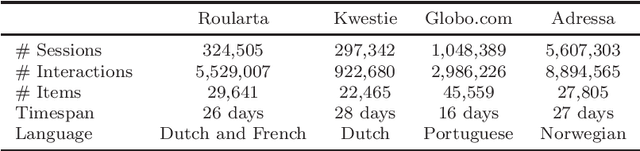
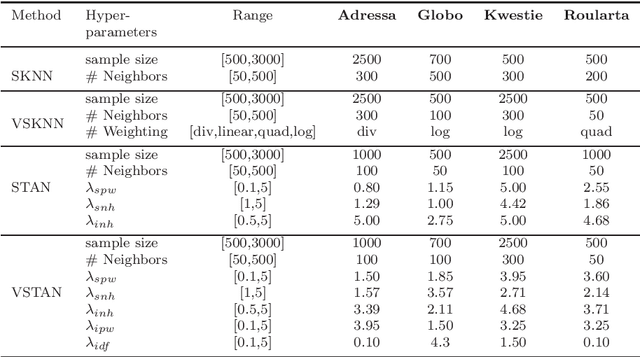
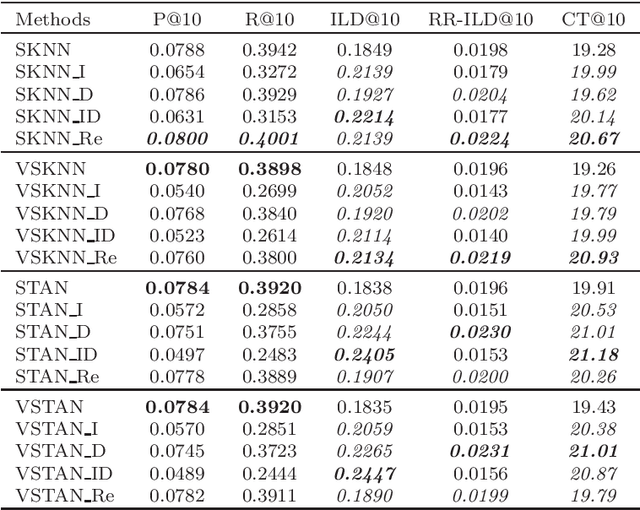
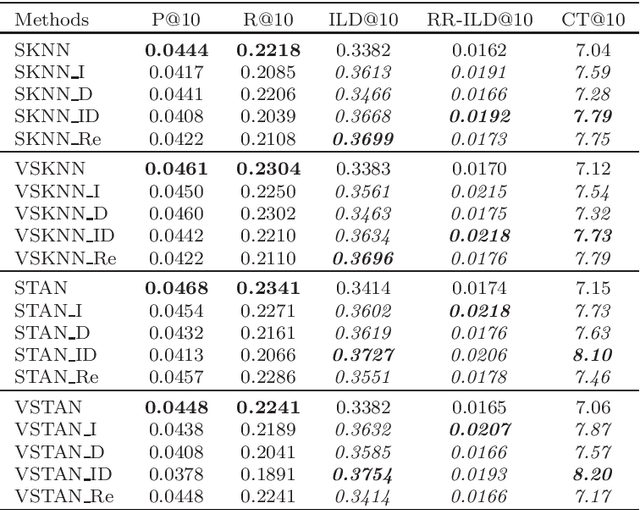
Recommender systems are widely applied in digital platforms such as news websites to personalize services based on user preferences. In news websites most of users are anonymous and the only available data is sequences of items in anonymous sessions. Due to this, typical collaborative filtering methods, which are highly applied in many applications, are not effective in news recommendations. In this context, session-based recommenders are able to recommend next items given the sequence of previous items in the active session. Neighborhood-based session-based recommenders has been shown to be highly effective compared to more sophisticated approaches. In this study we propose scenarios to make these session-based recommender systems diversity-aware and to address the filter bubble phenomenon. The filter bubble phenomenon is a common concern in news recommendation systems and it occurs when the system narrows the information and deprives users of diverse information. The results of applying the proposed scenarios show that these diversification scenarios improve the diversity measures in these session-based recommender systems based on four news datasets.
Drug-Target Interaction Prediction via an Ensemble of Weighted Nearest Neighbors with Interaction Recovery
Dec 22, 2020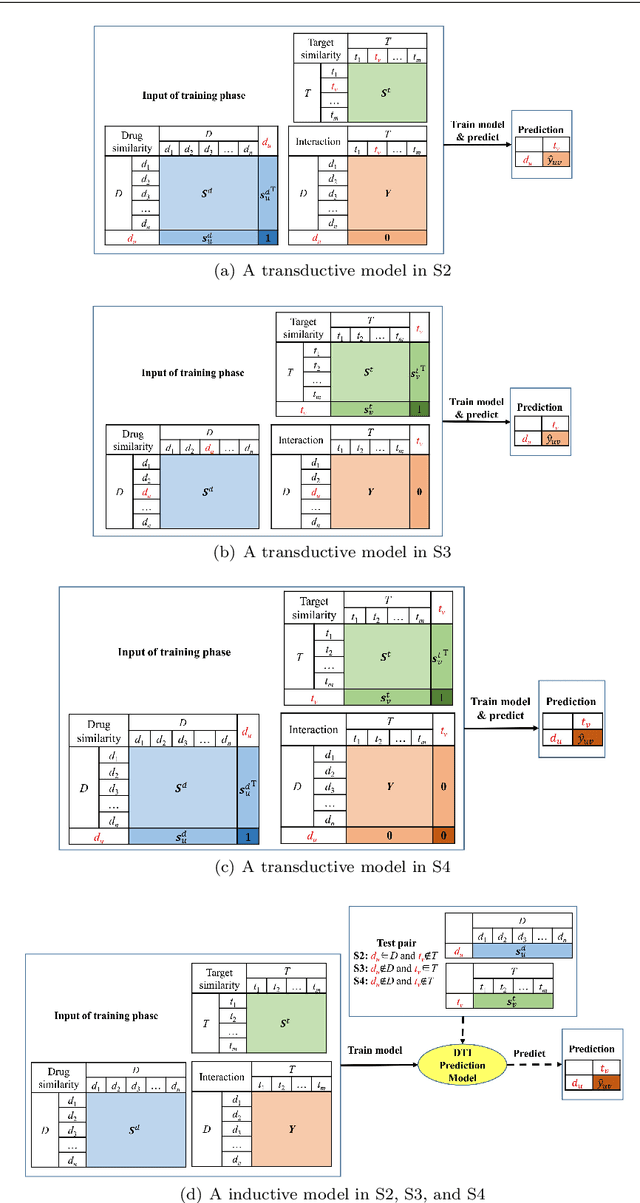



Predicting drug-target interactions (DTI) via reliable computational methods is an effective and efficient way to mitigate the enormous costs and time of the drug discovery process. Structure-based drug similarities and sequence-based target protein similarities are the commonly used information for DTI prediction. Among numerous computational methods, neighborhood-based chemogenomic approaches that leverage drug and target similarities to perform predictions directly are simple but promising ones. However, most existing similarity-based methods follow the transductive setting. These methods cannot directly generalize to unseen data because they should be re-built to predict the interactions for new arriving drugs, targets, or drug-target pairs. Besides, many similarity-based methods, especially neighborhood-based ones, cannot handle directly all three types of interaction prediction. Furthermore, a large amount of missing interactions in current DTI datasets hinders most DTI prediction methods. To address these issues, we propose a new method denoted as Weighted k Nearest Neighbor with Interaction Recovery (WkNNIR). Not only can WkNNIR estimate interactions of any new drugs and/or new targets without any need of re-training, but it can also recover missing interactions. In addition, WkNNIR exploits local imbalance to promote the influence of more reliable similarities on the DTI prediction process. We also propose a series of ensemble methods that employ diverse sampling strategies and could be coupled with WkNNIR as well as any other DTI prediction method to improve performance. Experimental results over four benchmark datasets demonstrate the effectiveness of our approaches in predicting drug-target interactions. Lastly, we confirm the practical prediction ability of proposed methods to discover reliable interactions that not reported in the original benchmark datasets.