 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOxytrees: Model Trees for Bipartite Learning
Nov 16, 2025Bipartite learning is a machine learning task that aims to predict interactions between pairs of instances. It has been applied to various domains, including drug-target interactions, RNA-disease associations, and regulatory network inference. Despite being widely investigated, current methods still present drawbacks, as they are often designed for a specific application and thus do not generalize to other problems or present scalability issues. To address these challenges, we propose Oxytrees: proxy-based biclustering model trees. Oxytrees compress the interaction matrix into row- and column-wise proxy matrices, significantly reducing training time without compromising predictive performance. We also propose a new leaf-assignment algorithm that significantly reduces the time taken for prediction. Finally, Oxytrees employ linear models using the Kronecker product kernel in their leaves, resulting in shallower trees and thus even faster training. Using 15 datasets, we compared the predictive performance of ensembles of Oxytrees with that of the current state-of-the-art. We achieved up to 30-fold improvement in training times compared to state-of-the-art biclustering forests, while demonstrating competitive or superior performance in most evaluation settings, particularly in the inductive setting. Finally, we provide an intuitive Python API to access all datasets, methods and evaluation measures used in this work, thus enabling reproducible research in this field.
Label Cluster Chains for Multi-Label Classification
Nov 01, 2024



Multi-label classification is a type of supervised machine learning that can simultaneously assign multiple labels to an instance. To solve this task, some methods divide the original problem into several sub-problems (local approach), others learn all labels at once (global approach), and others combine several classifiers (ensemble approach). Regardless of the approach used, exploring and learning label correlations is important to improve the classifier predictions. Ensemble of Classifier Chains (ECC) is a well-known multi-label method that considers label correlations and can achieve good overall performance on several multi-label datasets and evaluation measures. However, one of the challenges when working with ECC is the high dimensionality of the label space, which can impose limitations for fully-cascaded chains as the complexity increases regarding feature space expansion. To improve classifier chains, we propose a method to chain disjoint correlated label clusters obtained by applying a partition method in the label space. During the training phase, the ground truth labels of each cluster are used as new features for all of the following clusters. During the test phase, the predicted labels of clusters are used as new features for all the following clusters. Our proposal, called Label Cluster Chains for Multi-Label Classification (LCC-ML), uses multi-label Random Forests as base classifiers in each cluster, combining their predictions to obtain a final multi-label classification. Our proposal obtained better results compared to the original ECC. This shows that learning and chaining disjoint correlated label clusters can better explore and learn label correlations.
Multi-label Stream Classification with Self-Organizing Maps
Apr 20, 2020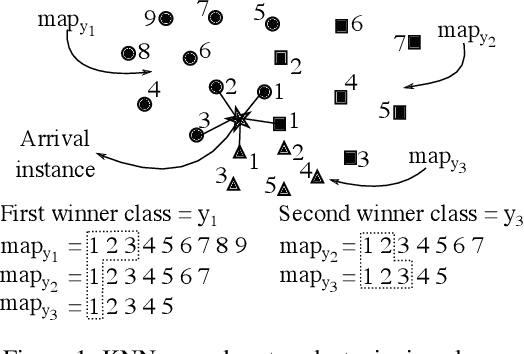
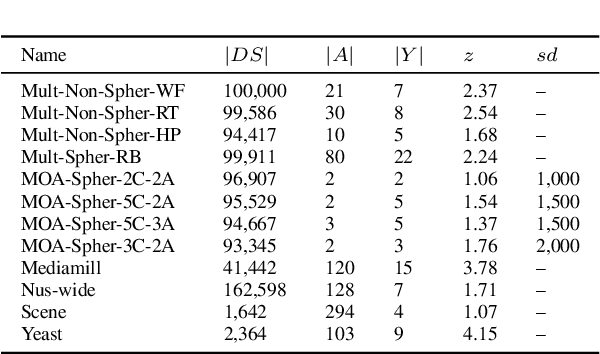
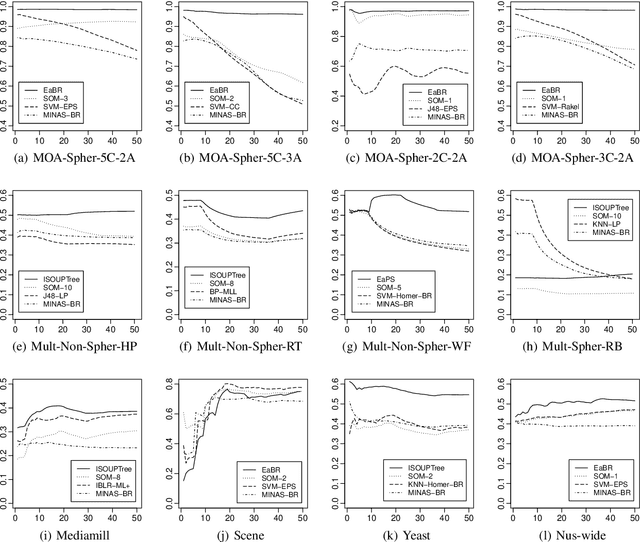
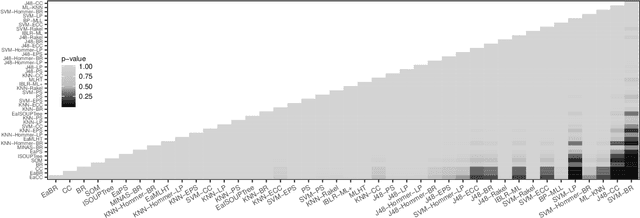
Several learning algorithms have been proposed for offline multi-label classification. However, applications in areas such as traffic monitoring, social networks, and sensors produce data continuously, the so called data streams, posing challenges to batch multi-label learning. With the lack of stationarity in the distribution of data streams, new algorithms are needed to online adapt to such changes (concept drift). Also, in realistic applications, changes occur in scenarios of infinitely delayed labels, where the true classes of the arrival instances are never available. We propose an online unsupervised incremental method based on self-organizing maps for multi-label stream classification with infinitely delayed labels. In the classification phase, we use a k-nearest neighbors strategy to compute the winning neurons in the maps, adapting to concept drift by online adjusting neuron weight vectors and dataset label cardinality. We predict labels for each instance using the Bayes rule and the outputs of each neuron, adapting the probabilities and conditional probabilities of the classes in the stream. Experiments using synthetic and real datasets show that our method is highly competitive with several ones from the literature, in both stationary and concept drift scenarios.
Generation of Consistent Sets of Multi-Label Classification Rules with a Multi-Objective Evolutionary Algorithm
Mar 27, 2020
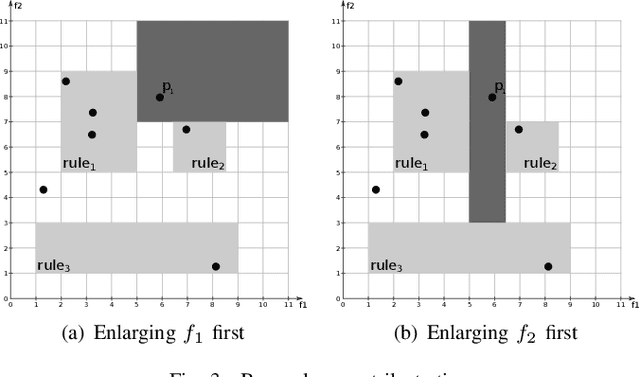
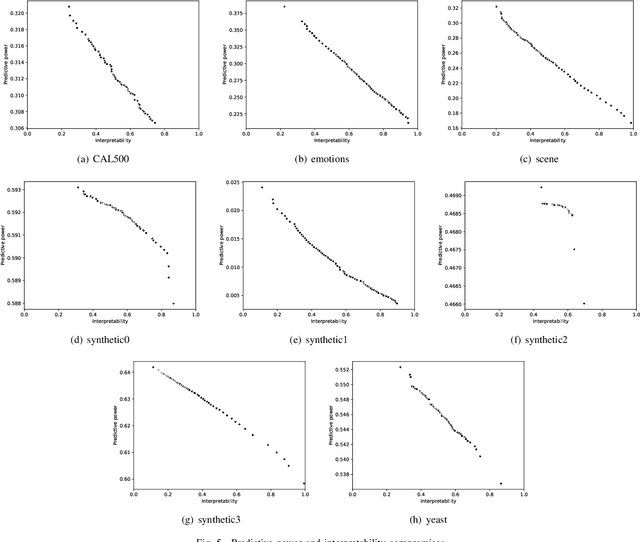
Multi-label classification consists in classifying an instance into two or more classes simultaneously. It is a very challenging task present in many real-world applications, such as classification of biology, image, video, audio, and text. Recently, the interest in interpretable classification models has grown, partially as a consequence of regulations such as the General Data Protection Regulation. In this context, we propose a multi-objective evolutionary algorithm that generates multiple rule-based multi-label classification models, allowing users to choose among models that offer different compromises between predictive power and interpretability. An important contribution of this work is that different from most algorithms, which usually generate models based on lists (ordered collections) of rules, our algorithm generates models based on sets (unordered collections) of rules, increasing interpretability. Also, by employing a conflict avoidance algorithm during the rule-creation, every rule within a given model is guaranteed to be consistent with every other rule in the same model. Thus, no conflict resolution strategy is required, evolving simpler models. We conducted experiments on synthetic and real-world datasets and compared our results with state-of-the-art algorithms in terms of predictive performance (F-Score) and interpretability (model size), and demonstrate that our best models had comparable F-Score and smaller model sizes.
Preventing the Generation of Inconsistent Sets of Classification Rules
Aug 23, 2019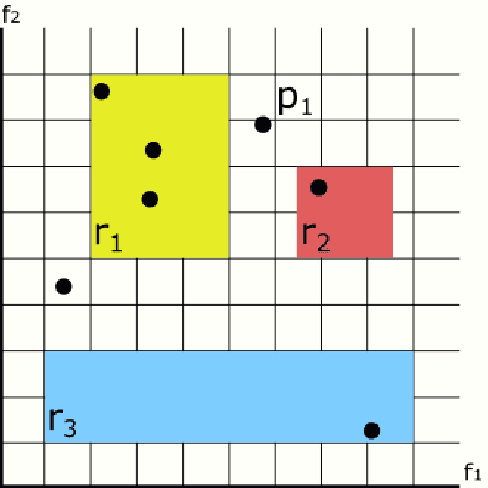
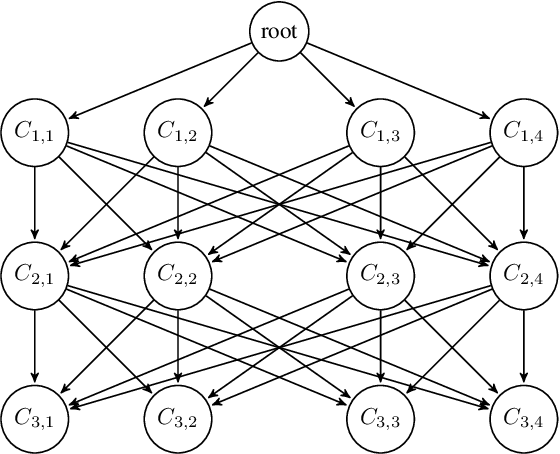
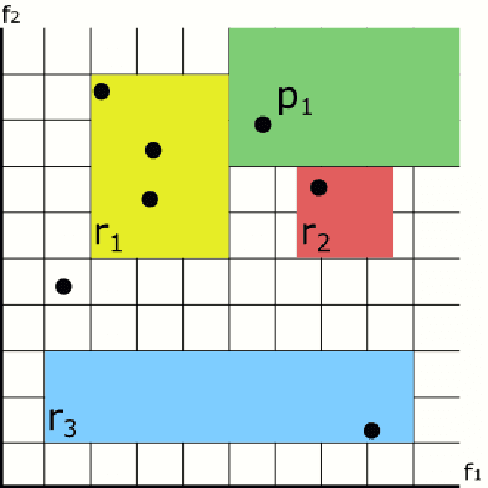
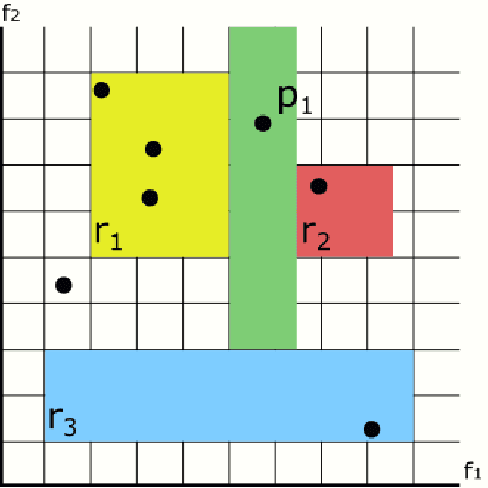
In recent years, the interest in interpretable classification models has grown. One of the proposed ways to improve the interpretability of a rule-based classification model is to use sets (unordered collections) of rules, instead of lists (ordered collections) of rules. One of the problems associated with sets is that multiple rules may cover a single instance, but predict different classes for it, thus requiring a conflict resolution strategy. In this work, we propose two algorithms capable of finding feature-space regions inside which any created rule would be consistent with the already existing rules, preventing inconsistencies from arising. Our algorithms do not generate classification models, but are instead meant to enhance algorithms that do so, such as Learning Classifier Systems. Both algorithms are described and analyzed exclusively from a theoretical perspective, since we have not modified a model-generating algorithm to incorporate our proposed solutions yet. This work presents the novelty of using conflict avoidance strategies instead of conflict resolution strategies.
An empirical study on hyperparameter tuning of decision trees
Dec 05, 2018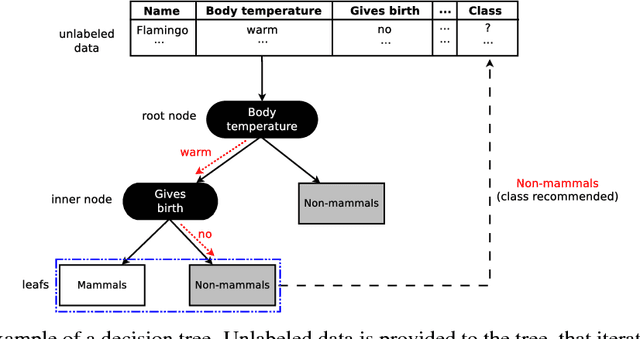
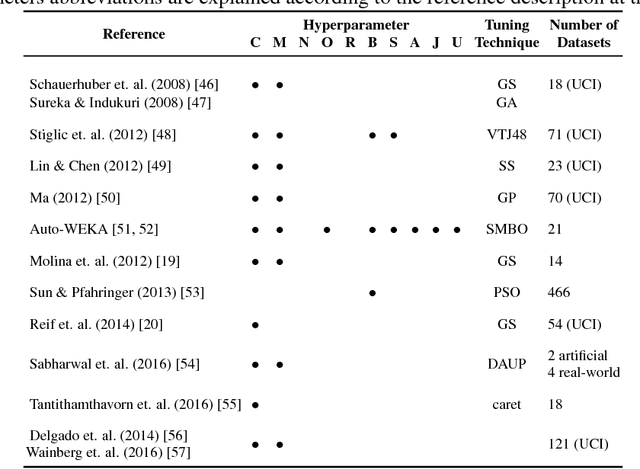
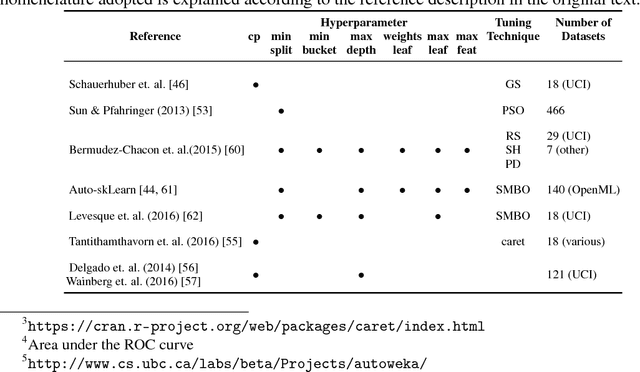
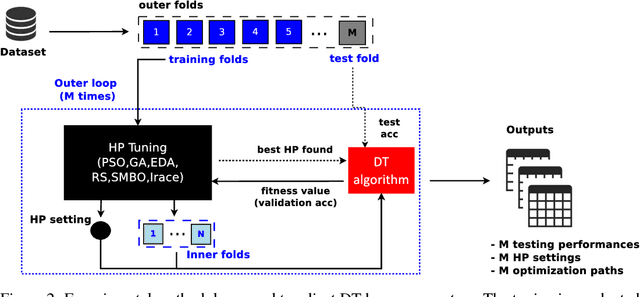
Machine learning algorithms often contain many hyperparameters whose values affect the predictive performance of the induced models in intricate ways. Due to the high number of possibilities for these hyperparameter configurations, and their complex interactions, it is common to use optimization techniques to find settings that lead to high predictive accuracy. However, we lack insight into how to efficiently explore this vast space of configurations: which are the best optimization techniques, how should we use them, and how significant is their effect on predictive or runtime performance? This paper provides a comprehensive approach for investigating the effects of hyperparameter tuning on three Decision Tree induction algorithms, CART, C4.5 and CTree. These algorithms were selected because they are based on similar principles, have presented a high predictive performance in several previous works and induce interpretable classification models. Additionally, they contain many interacting hyperparameters to be adjusted. Experiments were carried out with different tuning strategies to induce models and evaluate the relevance of hyperparameters using 94 classification datasets from OpenML. Experimental results indicate that hyperparameter tuning provides statistically significant improvements for C4.5 and CTree in only one-third of the datasets, and in most of the datasets for CART. Different tree algorithms may present different tuning scenarios, but in general, the tuning techniques required relatively few iterations to find accurate solutions. Furthermore, the best technique for all the algorithms was the Irace. Finally, we find that tuning a specific small subset of hyperparameters contributes most of the achievable optimal predictive performance.