 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClient Error Clustering Approaches in Content Delivery Networks (CDN)
Oct 11, 2022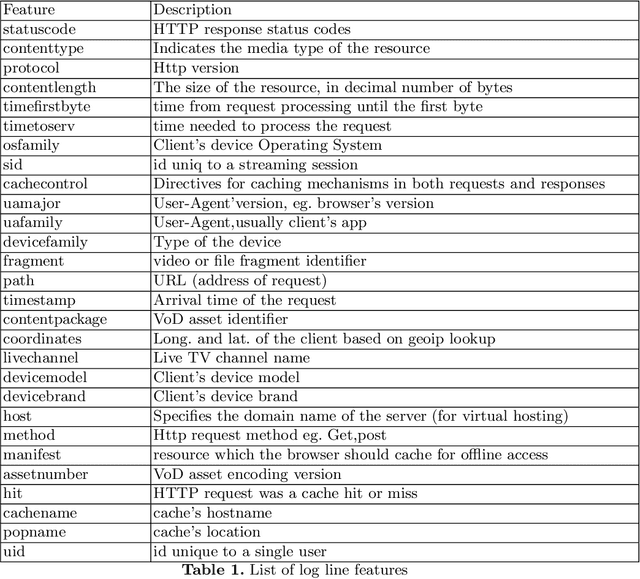


Content delivery networks (CDNs) are the backbone of the Internet and are key in delivering high quality video on demand (VoD), web content and file services to billions of users. CDNs usually consist of hierarchically organized content servers positioned as close to the customers as possible. CDN operators face a significant challenge when analyzing billions of web server and proxy logs generated by their systems. The main objective of this study was to analyze the applicability of various clustering methods in CDN error log analysis. We worked with real-life CDN proxy logs, identified key features included in the logs (e.g., content type, HTTP status code, time-of-day, host) and clustered the log lines corresponding to different host types offering live TV, video on demand, file caching and web content. Our experiments were run on a dataset consisting of proxy logs collected over a 7-day period from a single, physical CDN server running multiple types of services (VoD, live TV, file). The dataset consisted of 2.2 billion log lines. Our analysis showed that CDN error clustering is a viable approach towards identifying recurring errors and improving overall quality of service.
Denoising Architecture for Unsupervised Anomaly Detection in Time-Series
Aug 30, 2022Anomalies in time-series provide insights of critical scenarios across a range of industries, from banking and aerospace to information technology, security, and medicine. However, identifying anomalies in time-series data is particularly challenging due to the imprecise definition of anomalies, the frequent absence of labels, and the enormously complex temporal correlations present in such data. The LSTM Autoencoder is an Encoder-Decoder scheme for Anomaly Detection based on Long Short Term Memory Networks that learns to reconstruct time-series behavior and then uses reconstruction error to identify abnormalities. We introduce the Denoising Architecture as a complement to this LSTM Encoder-Decoder model and investigate its effect on real-world as well as artificially generated datasets. We demonstrate that the proposed architecture increases both the accuracy and the training speed, thereby, making the LSTM Autoencoder more efficient for unsupervised anomaly detection tasks.
Object Detection Using Sim2Real Domain Randomization for Robotic Applications
Aug 08, 2022

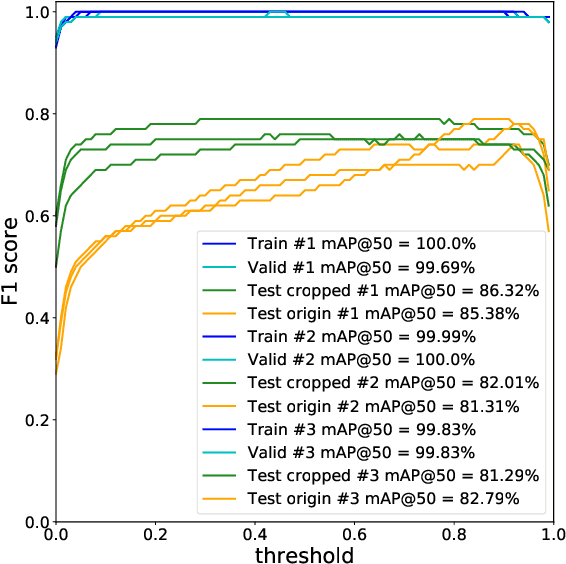

Robots working in unstructured environments must be capable of sensing and interpreting their surroundings. One of the main obstacles of deep learning based models in the field of robotics is the lack of domain-specific labeled data for different industrial applications. In this paper, we propose a sim2real transfer learning method based on domain randomization for object detection with which labeled synthetic datasets of arbitrary size and object types can be automatically generated. Subsequently, a state-of-the-art convolutional neural network, YOLOv4, is trained to detect the different types of industrial objects. With the proposed domain randomization method, we could shrink the reality gap to a satisfactory level, achieving 86.32% and 97.38% mAP50 scores respectively in the case of zero-shot and one-shot transfers, on our manually annotated dataset containing 190 real images. On a GeForce RTX 2080 Ti GPU, the data generation process takes less than 0.5s per image and the training lasts around 12h which makes it convenient for industrial use. Our solution matches industrial needs as it can reliably differentiate similar classes of objects by using only 1 real image for training. To our best knowledge, this is the only work thus far satisfying these constraints.
An empirical study on hyperparameter tuning of decision trees
Dec 05, 2018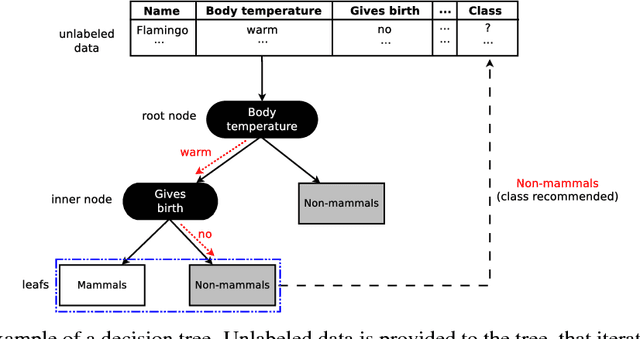
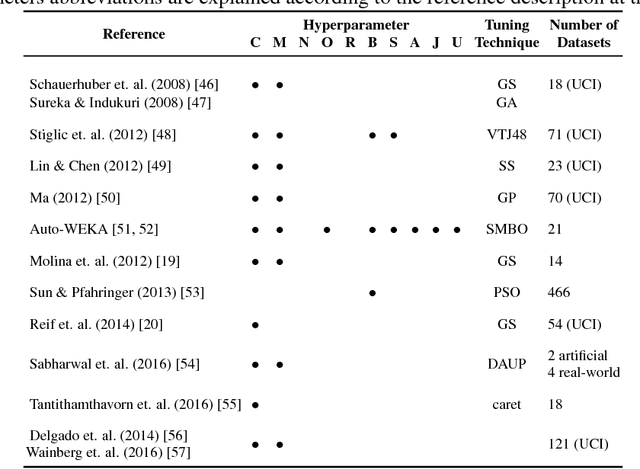
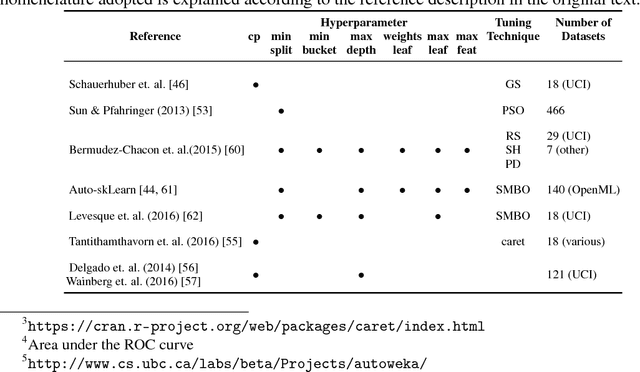
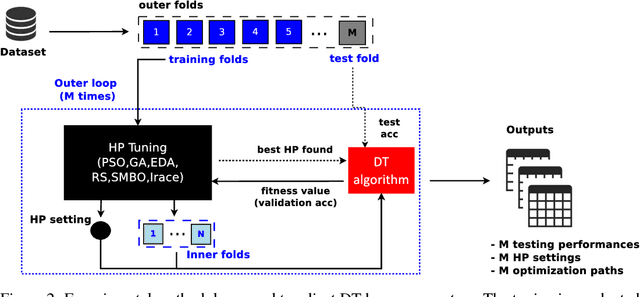
Machine learning algorithms often contain many hyperparameters whose values affect the predictive performance of the induced models in intricate ways. Due to the high number of possibilities for these hyperparameter configurations, and their complex interactions, it is common to use optimization techniques to find settings that lead to high predictive accuracy. However, we lack insight into how to efficiently explore this vast space of configurations: which are the best optimization techniques, how should we use them, and how significant is their effect on predictive or runtime performance? This paper provides a comprehensive approach for investigating the effects of hyperparameter tuning on three Decision Tree induction algorithms, CART, C4.5 and CTree. These algorithms were selected because they are based on similar principles, have presented a high predictive performance in several previous works and induce interpretable classification models. Additionally, they contain many interacting hyperparameters to be adjusted. Experiments were carried out with different tuning strategies to induce models and evaluate the relevance of hyperparameters using 94 classification datasets from OpenML. Experimental results indicate that hyperparameter tuning provides statistically significant improvements for C4.5 and CTree in only one-third of the datasets, and in most of the datasets for CART. Different tree algorithms may present different tuning scenarios, but in general, the tuning techniques required relatively few iterations to find accurate solutions. Furthermore, the best technique for all the algorithms was the Irace. Finally, we find that tuning a specific small subset of hyperparameters contributes most of the achievable optimal predictive performance.