 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of AutoML on Dirty Categorical Data
Jan 31, 2026The goal of automated machine learning (AutoML) is to reduce trial and error when doing machine learning (ML). Although AutoML methods for classification are able to deal with data imperfections, such as outliers, multiple scales and missing data, their behavior is less known on dirty categorical datasets. These datasets often have several categorical features with high cardinality arising from issues such as lack of curation and automated collection. Recent research has shown that ML models can benefit from morphological encoders for dirty categorical data, leading to significantly superior predictive performance. However the effects of using such encoders in AutoML methods are not known at the moment. In this paper, we propose a pipeline that transforms categorical data into numerical data so that an AutoML can handle categorical data transformed by more advanced encoding schemes. We benchmark the current robustness of AutoML methods on a set of dirty datasets and compare it with the proposed pipeline. This allows us to get insight on differences in predictive performance. We also look at the ML pipelines built by AutoMLs in order to gain insight beyond the best model as typically returned by these methods.
Score Matching on Large Geometric Graphs for Cosmology Generation
Aug 23, 2025Generative models are a promising tool to produce cosmological simulations but face significant challenges in scalability, physical consistency, and adherence to domain symmetries, limiting their utility as alternatives to $N$-body simulations. To address these limitations, we introduce a score-based generative model with an equivariant graph neural network that simulates gravitational clustering of galaxies across cosmologies starting from an informed prior, respects periodic boundaries, and scales to full galaxy counts in simulations. A novel topology-aware noise schedule, crucial for large geometric graphs, is introduced. The proposed equivariant score-based model successfully generates full-scale cosmological point clouds of up to 600,000 halos, respects periodicity and a uniform prior, and outperforms existing diffusion models in capturing clustering statistics while offering significant computational advantages. This work advances cosmology by introducing a generative model designed to closely resemble the underlying gravitational clustering of structure formation, moving closer to physically realistic and efficient simulators for the evolution of large-scale structures in the universe.
Evolving Machine Learning: A Survey
May 23, 2025In an era defined by rapid data evolution, traditional machine learning (ML) models often fall short in adapting to dynamic environments. Evolving Machine Learning (EML) has emerged as a critical paradigm, enabling continuous learning and adaptation in real-time data streams. This survey presents a comprehensive analysis of EML, focusing on five core challenges: data drift, concept drift, catastrophic forgetting, skewed learning, and network adaptation. We systematically review over 120 studies, categorizing state-of-the-art methods across supervised, unsupervised, and semi-supervised approaches. The survey explores diverse evaluation metrics, benchmark datasets, and real-world applications, offering a comparative lens on the effectiveness and limitations of current techniques. Additionally, we highlight the growing role of adaptive neural architectures, meta-learning, and ensemble strategies in addressing evolving data complexities. By synthesizing insights from recent literature, this work not only maps the current landscape of EML but also identifies critical gaps and opportunities for future research. Our findings aim to guide researchers and practitioners in developing robust, ethical, and scalable EML systems for real-world deployment.
AutoML Benchmark with shorter time constraints and early stopping
Apr 01, 2025Automated Machine Learning (AutoML) automatically builds machine learning (ML) models on data. The de facto standard for evaluating new AutoML frameworks for tabular data is the AutoML Benchmark (AMLB). AMLB proposed to evaluate AutoML frameworks using 1- and 4-hour time budgets across 104 tasks. We argue that shorter time constraints should be considered for the benchmark because of their practical value, such as when models need to be retrained with high frequency, and to make AMLB more accessible. This work considers two ways in which to reduce the overall computation used in the benchmark: smaller time constraints and the use of early stopping. We conduct evaluations of 11 AutoML frameworks on 104 tasks with different time constraints and find the relative ranking of AutoML frameworks is fairly consistent across time constraints, but that using early-stopping leads to a greater variety in model performance.
Sculpting [CLS] Features for Pre-Trained Model-Based Class-Incremental Learning
Feb 20, 2025Class-incremental learning requires models to continually acquire knowledge of new classes without forgetting old ones. Although pre-trained models have demonstrated strong performance in class-incremental learning, they remain susceptible to catastrophic forgetting when learning new concepts. Excessive plasticity in the models breaks generalizability and causes forgetting, while strong stability results in insufficient adaptation to new classes. This necessitates effective adaptation with minimal modifications to preserve the general knowledge of pre-trained models. To address this challenge, we first introduce a new parameter-efficient fine-tuning module 'Learn and Calibrate', or LuCA, designed to acquire knowledge through an adapter-calibrator couple, enabling effective adaptation with well-refined feature representations. Second, for each learning session, we deploy a sparse LuCA module on top of the last token just before the classifier, which we refer to as 'Token-level Sparse Calibration and Adaptation', or TOSCA. This strategic design improves the orthogonality between the modules and significantly reduces both training and inference complexity. By leaving the generalization capabilities of the pre-trained models intact and adapting exclusively via the last token, our approach achieves a harmonious balance between stability and plasticity. Extensive experiments demonstrate TOSCA's state-of-the-art performance while introducing ~8 times fewer parameters compared to prior methods.
Occam's model: Selecting simpler representations for better transferability estimation
Feb 10, 2025Fine-tuning models that have been pre-trained on large datasets has become a cornerstone of modern machine learning workflows. With the widespread availability of online model repositories, such as Hugging Face, it is now easier than ever to fine-tune pre-trained models for specific tasks. This raises a critical question: which pre-trained model is most suitable for a given task? This problem is called transferability estimation. In this work, we introduce two novel and effective metrics for estimating the transferability of pre-trained models. Our approach is grounded in viewing transferability as a measure of how easily a pre-trained model's representations can be trained to separate target classes, providing a unique perspective on transferability estimation. We rigorously evaluate the proposed metrics against state-of-the-art alternatives across diverse problem settings, demonstrating their robustness and practical utility. Additionally, we present theoretical insights that explain our metrics' efficacy and adaptability to various scenarios. We experimentally show that our metrics increase Kendall's Tau by up to 32% compared to the state-of-the-art baselines.
On dataset transferability in medical image classification
Dec 28, 2024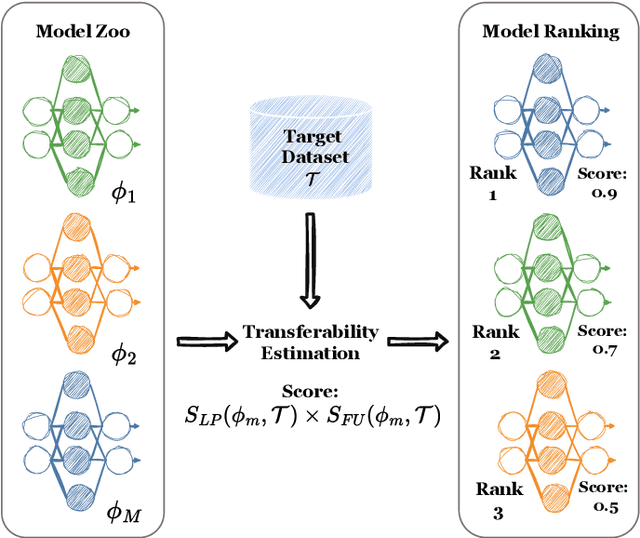
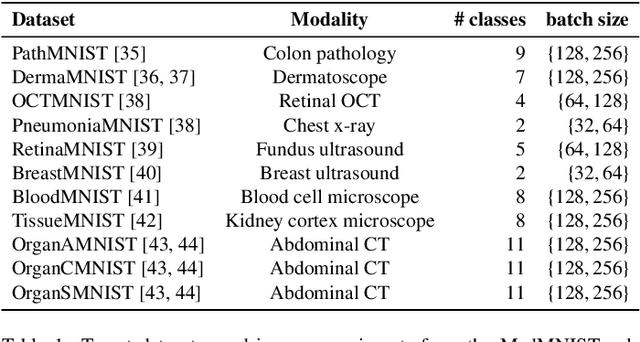
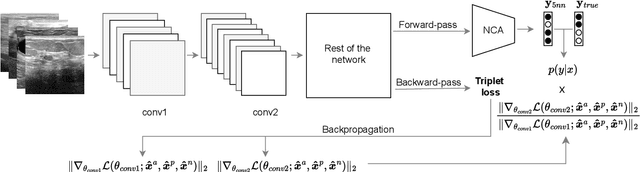
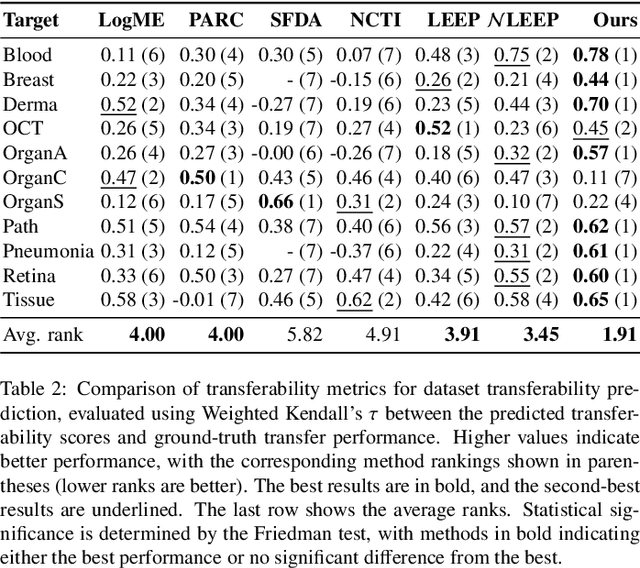
Current transferability estimation methods designed for natural image datasets are often suboptimal in medical image classification. These methods primarily focus on estimating the suitability of pre-trained source model features for a target dataset, which can lead to unrealistic predictions, such as suggesting that the target dataset is the best source for itself. To address this, we propose a novel transferability metric that combines feature quality with gradients to evaluate both the suitability and adaptability of source model features for target tasks. We evaluate our approach in two new scenarios: source dataset transferability for medical image classification and cross-domain transferability. Our results show that our method outperforms existing transferability metrics in both settings. We also provide insight into the factors influencing transfer performance in medical image classification, as well as the dynamics of cross-domain transfer from natural to medical images. Additionally, we provide ground-truth transfer performance benchmarking results to encourage further research into transferability estimation for medical image classification. Our code and experiments are available at https://github.com/DovileDo/transferability-in-medical-imaging.
Continual Learning on a Data Diet
Oct 23, 2024



Continual Learning (CL) methods usually learn from all available data. However, this is not the case in human cognition which efficiently focuses on key experiences while disregarding the redundant information. Similarly, not all data points in a dataset have equal potential; some can be more informative than others. This disparity may significantly impact the performance, as both the quality and quantity of samples directly influence the model's generalizability and efficiency. Drawing inspiration from this, we explore the potential of learning from important samples and present an empirical study for evaluating coreset selection techniques in the context of CL to stimulate research in this unexplored area. We train different continual learners on increasing amounts of selected samples and investigate the learning-forgetting dynamics by shedding light on the underlying mechanisms driving their improved stability-plasticity balance. We present several significant observations: learning from selectively chosen samples (i) enhances incremental accuracy, (ii) improves knowledge retention of previous tasks, and (iii) refines learned representations. This analysis contributes to a deeper understanding of selective learning strategies in CL scenarios.
Learning to Learn without Forgetting using Attention
Aug 06, 2024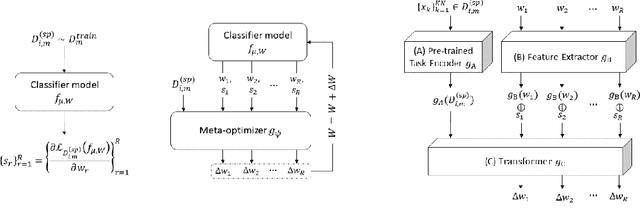

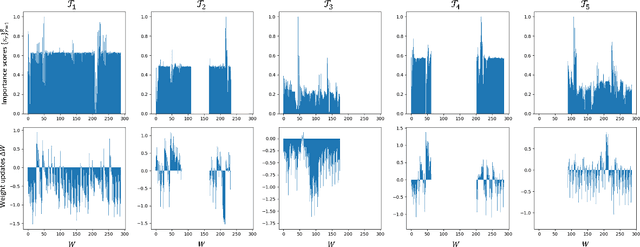
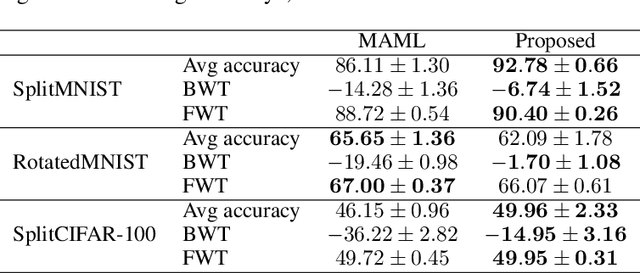
Continual learning (CL) refers to the ability to continually learn over time by accommodating new knowledge while retaining previously learned experience. While this concept is inherent in human learning, current machine learning methods are highly prone to overwrite previously learned patterns and thus forget past experience. Instead, model parameters should be updated selectively and carefully, avoiding unnecessary forgetting while optimally leveraging previously learned patterns to accelerate future learning. Since hand-crafting effective update mechanisms is difficult, we propose meta-learning a transformer-based optimizer to enhance CL. This meta-learned optimizer uses attention to learn the complex relationships between model parameters across a stream of tasks, and is designed to generate effective weight updates for the current task while preventing catastrophic forgetting on previously encountered tasks. Evaluations on benchmark datasets like SplitMNIST, RotatedMNIST, and SplitCIFAR-100 affirm the efficacy of the proposed approach in terms of both forward and backward transfer, even on small sets of labeled data, highlighting the advantages of integrating a meta-learned optimizer within the continual learning framework.
Robust and Efficient Transfer Learning via Supernet Transfer in Warm-started Neural Architecture Search
Jul 26, 2024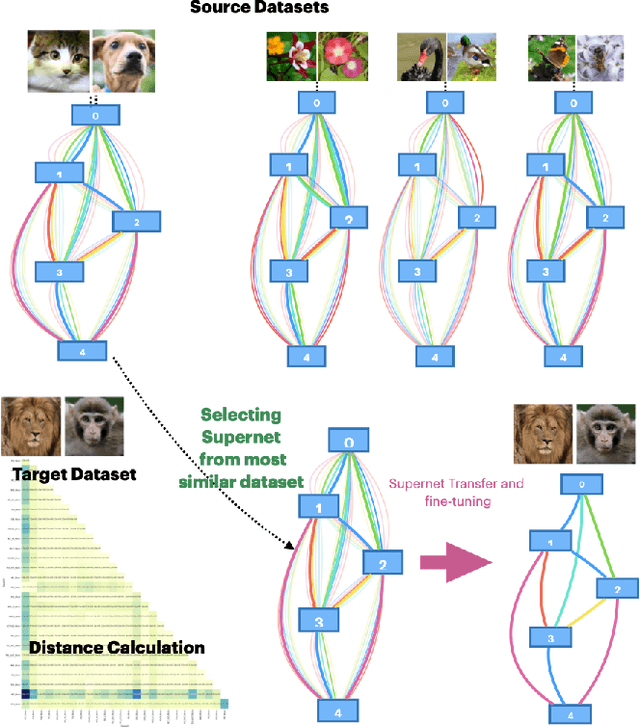
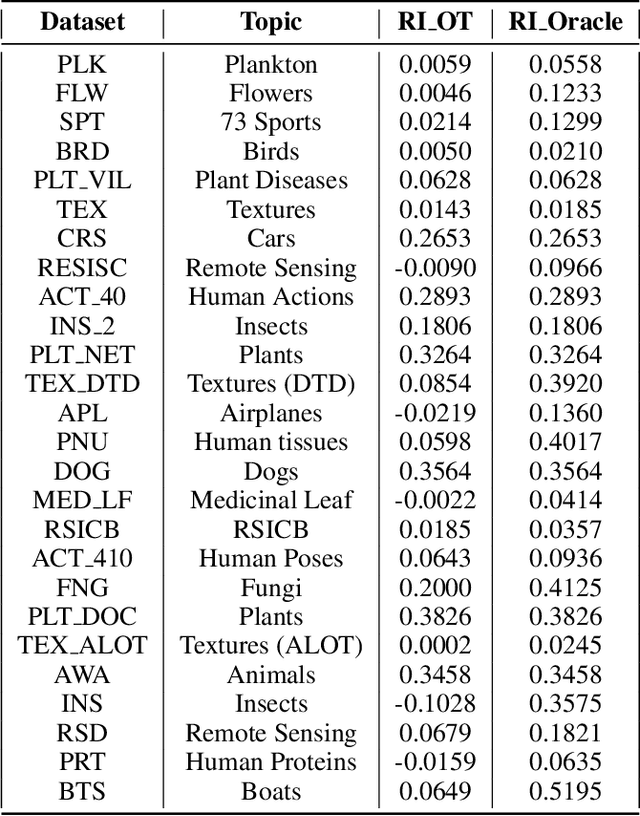
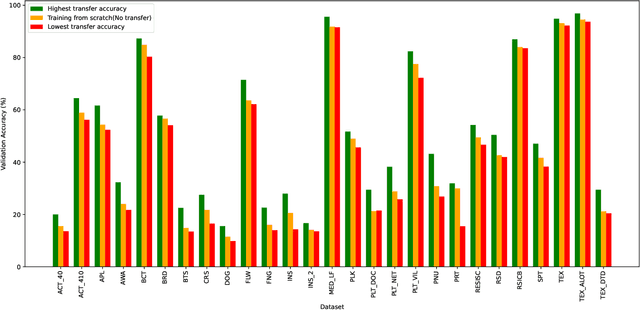
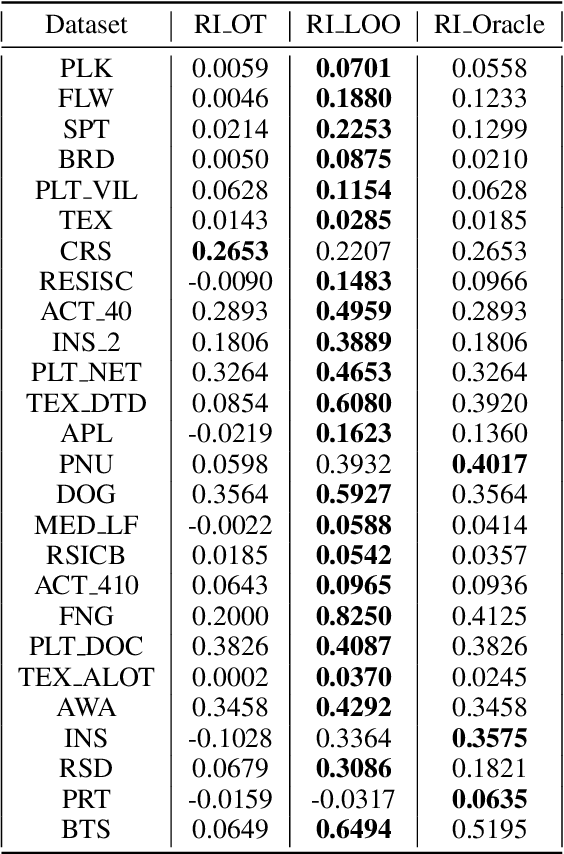
Hand-designing Neural Networks is a tedious process that requires significant expertise. Neural Architecture Search (NAS) frameworks offer a very useful and popular solution that helps to democratize AI. However, these NAS frameworks are often computationally expensive to run, which limits their applicability and accessibility. In this paper, we propose a novel transfer learning approach, capable of effectively transferring pretrained supernets based on Optimal Transport or multi-dataset pretaining. This method can be generally applied to NAS methods based on Differentiable Architecture Search (DARTS). Through extensive experiments across dozens of image classification tasks, we demonstrate that transferring pretrained supernets in this way can not only drastically speed up the supernet training which then finds optimal models (3 to 5 times faster on average), but even yield that outperform those found when running DARTS methods from scratch. We also observe positive transfer to almost all target datasets, making it very robust. Besides drastically improving the applicability of NAS methods, this also opens up new applications for continual learning and related fields.